 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatents2Segments: Disentangling the Latent Space of Generative Models for Semantic Segmentation of Face Images
Paper and Code
Jul 06, 2022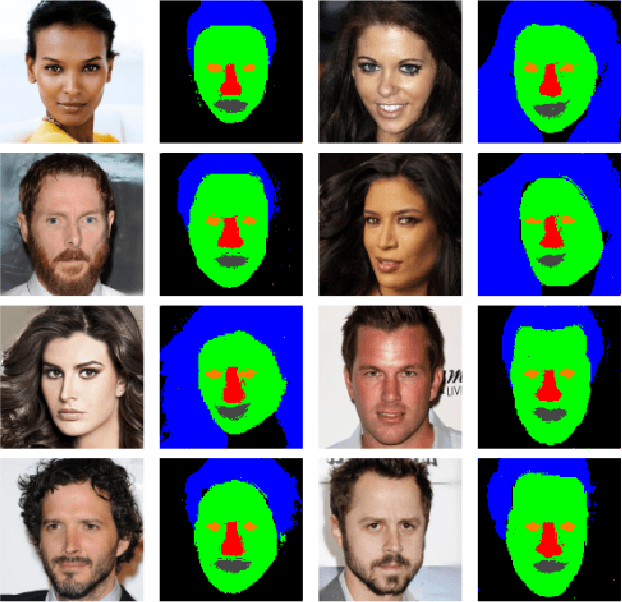
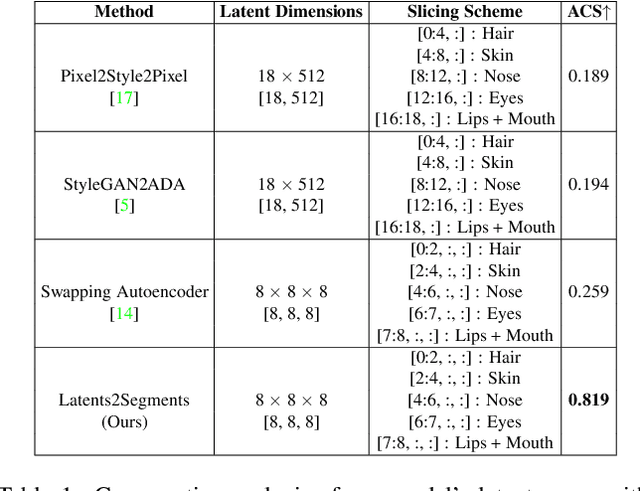
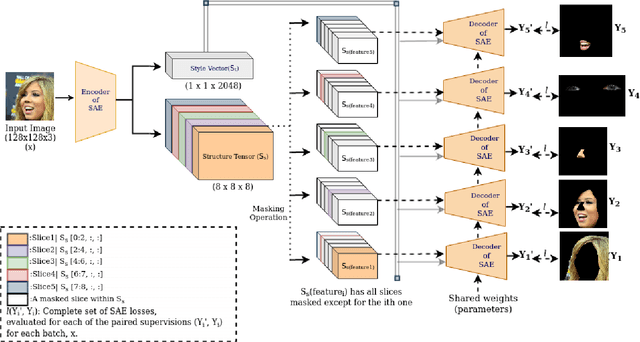

With the advent of an increasing number of Augmented and Virtual Reality applications that aim to perform meaningful and controlled style edits on images of human faces, the impetus for the task of parsing face images to produce accurate and fine-grained semantic segmentation maps is more than ever before. Few State of the Art (SOTA) methods which solve this problem, do so by incorporating priors with respect to facial structure or other face attributes such as expression and pose in their deep classifier architecture. Our endeavour in this work is to do away with the priors and complex pre-processing operations required by SOTA multi-class face segmentation models by reframing this operation as a downstream task post infusion of disentanglement with respect to facial semantic regions of interest (ROIs) in the latent space of a Generative Autoencoder model. We present results for our model's performance on the CelebAMask-HQ and HELEN datasets. The encoded latent space of our model achieves significantly higher disentanglement with respect to semantic ROIs than that of other SOTA works. Moreover, it achieves a 13% faster inference rate and comparable accuracy with respect to the publicly available SOTA for the downstream task of semantic segmentation of face images.