 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrototype-Based Disentanglement for Controllable Dysarthric Speech Synthesis
Feb 09, 2026Dysarthric speech exhibits high variability and limited labeled data, posing major challenges for both automatic speech recognition (ASR) and assistive speech technologies. Existing approaches rely on synthetic data augmentation or speech reconstruction, yet often entangle speaker identity with pathological articulation, limiting controllability and robustness. In this paper, we propose ProtoDisent-TTS, a prototype-based disentanglement TTS framework built on a pre-trained text-to-speech backbone that factorizes speaker timbre and dysarthric articulation within a unified latent space. A pathology prototype codebook provides interpretable and controllable representations of healthy and dysarthric speech patterns, while a dual-classifier objective with a gradient reversal layer enforces invariance of speaker embeddings to pathological attributes. Experiments on the TORGO dataset demonstrate that this design enables bidirectional transformation between healthy and dysarthric speech, leading to consistent ASR performance gains and robust, speaker-aware speech reconstruction.
Lumos3D: A Single-Forward Framework for Low-Light 3D Scene Restoration
Nov 12, 2025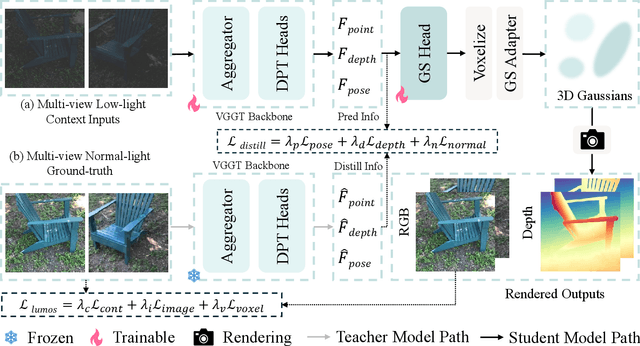

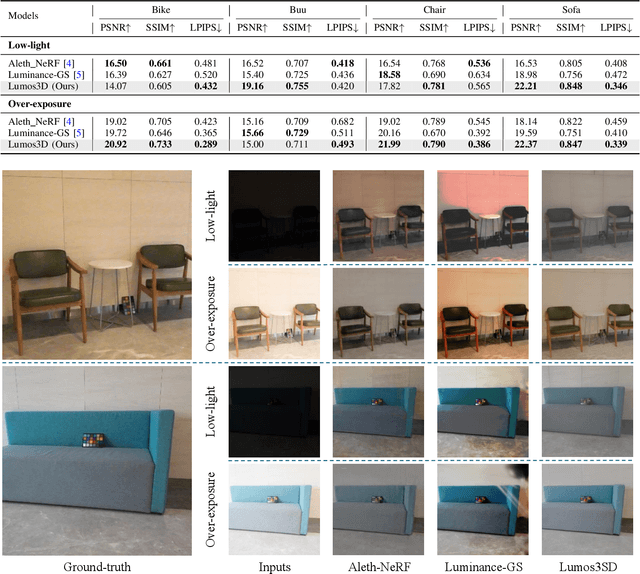
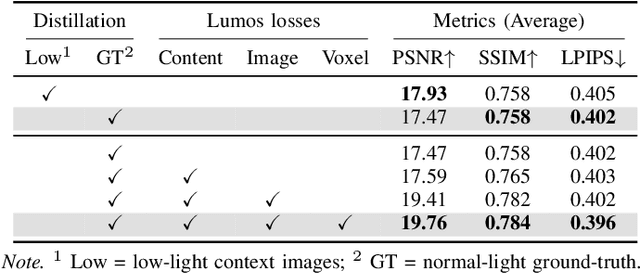
Restoring 3D scenes captured under low-light con- ditions remains a fundamental yet challenging problem. Most existing approaches depend on precomputed camera poses and scene-specific optimization, which greatly restricts their scala- bility to dynamic real-world environments. To overcome these limitations, we introduce Lumos3D, a generalizable pose-free framework for 3D low-light scene restoration. Trained once on a single dataset, Lumos3D performs inference in a purely feed- forward manner, directly restoring illumination and structure from unposed, low-light multi-view images without any per- scene training or optimization. Built upon a geometry-grounded backbone, Lumos3D reconstructs a normal-light 3D Gaussian representation that restores illumination while faithfully pre- serving structural details. During training, a cross-illumination distillation scheme is employed, where the teacher network is distilled on normal-light ground truth to transfer accurate geometric information, such as depth, to the student model. A dedicated Lumos loss is further introduced to promote photomet- ric consistency within the reconstructed 3D space. Experiments on real-world datasets demonstrate that Lumos3D achieves high- fidelity low-light 3D scene restoration with accurate geometry and strong generalization to unseen cases. Furthermore, the framework naturally extends to handle over-exposure correction, highlighting its versatility for diverse lighting restoration tasks.
Stylos: Multi-View 3D Stylization with Single-Forward Gaussian Splatting
Sep 30, 2025We present Stylos, a single-forward 3D Gaussian framework for 3D style transfer that operates on unposed content, from a single image to a multi-view collection, conditioned on a separate reference style image. Stylos synthesizes a stylized 3D Gaussian scene without per-scene optimization or precomputed poses, achieving geometry-aware, view-consistent stylization that generalizes to unseen categories, scenes, and styles. At its core, Stylos adopts a Transformer backbone with two pathways: geometry predictions retain self-attention to preserve geometric fidelity, while style is injected via global cross-attention to enforce visual consistency across views. With the addition of a voxel-based 3D style loss that aligns aggregated scene features to style statistics, Stylos enforces view-consistent stylization while preserving geometry. Experiments across multiple datasets demonstrate that Stylos delivers high-quality zero-shot stylization, highlighting the effectiveness of global style-content coupling, the proposed 3D style loss, and the scalability of our framework from single view to large-scale multi-view settings.
Privacy Protected Contactless Cardio-respiratory Monitoring using Defocused Cameras during Sleep
Jan 17, 2024The monitoring of vital signs such as heart rate (HR) and respiratory rate (RR) during sleep is important for the assessment of sleep quality and detection of sleep disorders. Camera-based HR and RR monitoring gained popularity in sleep monitoring in recent years. However, they are all facing with serious privacy issues when using a video camera in the sleeping scenario. In this paper, we propose to use the defocused camera to measure vital signs from optically blurred images, which can fundamentally eliminate the privacy invasion as face is difficult to be identified in obtained blurry images. A spatial-redundant framework involving living-skin detection is used to extract HR and RR from the defocused camera in NIR, and a motion metric is designed to exclude outliers caused by body motions. In the benchmark, the overall Mean Absolute Error (MAE) for HR measurement is 4.4 bpm, for RR measurement is 5.9 bpm. Both have quality drops as compared to the measurement using a focused camera, but the degradation in HR is much less, i.e. HR measurement has strong correlation with the reference ($R \geq 0.90$). Preliminary experiments suggest that it is feasible to use a defocused camera for cardio-respiratory monitoring while protecting the privacy. Further improvement is needed for robust RR measurement, such as by PPG-modulation based RR extraction.
GPT-4V Takes the Wheel: Evaluating Promise and Challenges for Pedestrian Behavior Prediction
Nov 24, 2023



Existing pedestrian behavior prediction methods rely primarily on deep neural networks that utilize features extracted from video frame sequences. Although these vision-based models have shown promising results, they face limitations in effectively capturing and utilizing the dynamic spatio-temporal interactions between the target pedestrian and its surrounding traffic elements, crucial for accurate reasoning. Additionally, training these models requires manually annotating domain-specific datasets, a process that is expensive, time-consuming, and difficult to generalize to new environments and scenarios. The recent emergence of Large Multimodal Models (LMMs) offers potential solutions to these limitations due to their superior visual understanding and causal reasoning capabilities, which can be harnessed through semi-supervised training. GPT-4V(ision), the latest iteration of the state-of-the-art Large-Language Model GPTs, now incorporates vision input capabilities. This report provides a comprehensive evaluation of the potential of GPT-4V for pedestrian behavior prediction in autonomous driving using publicly available datasets: JAAD, PIE, and WiDEVIEW. Quantitative and qualitative evaluations demonstrate GPT-4V(ision)'s promise in zero-shot pedestrian behavior prediction and driving scene understanding ability for autonomous driving. However, it still falls short of the state-of-the-art traditional domain-specific models. Challenges include difficulties in handling small pedestrians and vehicles in motion. These limitations highlight the need for further research and development in this area.
WiDEVIEW: An UltraWideBand and Vision Dataset for Deciphering Pedestrian-Vehicle Interactions
Sep 27, 2023



Robust and accurate tracking and localization of road users like pedestrians and cyclists is crucial to ensure safe and effective navigation of Autonomous Vehicles (AVs), particularly so in urban driving scenarios with complex vehicle-pedestrian interactions. Existing datasets that are useful to investigate vehicle-pedestrian interactions are mostly image-centric and thus vulnerable to vision failures. In this paper, we investigate Ultra-wideband (UWB) as an additional modality for road users' localization to enable a better understanding of vehicle-pedestrian interactions. We present WiDEVIEW, the first multimodal dataset that integrates LiDAR, three RGB cameras, GPS/IMU, and UWB sensors for capturing vehicle-pedestrian interactions in an urban autonomous driving scenario. Ground truth image annotations are provided in the form of 2D bounding boxes and the dataset is evaluated on standard 2D object detection and tracking algorithms. The feasibility of UWB is evaluated for typical traffic scenarios in both line-of-sight and non-line-of-sight conditions using LiDAR as ground truth. We establish that UWB range data has comparable accuracy with LiDAR with an error of 0.19 meters and reliable anchor-tag range data for up to 40 meters in line-of-sight conditions. UWB performance for non-line-of-sight conditions is subjective to the nature of the obstruction (trees vs. buildings). Further, we provide a qualitative analysis of UWB performance for scenarios susceptible to intermittent vision failures. The dataset can be downloaded via https://github.com/unmannedlab/UWB_Dataset.
Learning Pedestrian Actions to Ensure Safe Autonomous Driving
May 22, 2023



To ensure safe autonomous driving in urban environments with complex vehicle-pedestrian interactions, it is critical for Autonomous Vehicles (AVs) to have the ability to predict pedestrians' short-term and immediate actions in real-time. In recent years, various methods have been developed to study estimating pedestrian behaviors for autonomous driving scenarios, but there is a lack of clear definitions for pedestrian behaviors. In this work, the literature gaps are investigated and a taxonomy is presented for pedestrian behavior characterization. Further, a novel multi-task sequence to sequence Transformer encoders-decoders (TF-ed) architecture is proposed for pedestrian action and trajectory prediction using only ego vehicle camera observations as inputs. The proposed approach is compared against an existing LSTM encoders decoders (LSTM-ed) architecture for action and trajectory prediction. The performance of both models is evaluated on the publicly available Joint Attention Autonomous Driving (JAAD) dataset, CARLA simulation data as well as real-time self-driving shuttle data collected on university campus. Evaluation results illustrate that the proposed method reaches an accuracy of 81% on action prediction task on JAAD testing data and outperforms the LSTM-ed by 7.4%, while LSTM counterpart performs much better on trajectory prediction task for a prediction sequence length of 25 frames.