 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction-Graph Policies: Learning Action Co-dependencies in Multi-Agent Reinforcement Learning
Feb 19, 2026Coordinating actions is the most fundamental form of cooperation in multi-agent reinforcement learning (MARL). Successful decentralized decision-making often depends not only on good individual actions, but on selecting compatible actions across agents to synchronize behavior, avoid conflicts, and satisfy global constraints. In this paper, we propose Action Graph Policies (AGP), that model dependencies among agents' available action choices. It constructs, what we call, \textit{coordination contexts}, that enable agents to condition their decisions on global action dependencies. Theoretically, we show that AGPs induce a strictly more expressive joint policy compared to fully independent policies and can realize coordinated joint actions that are provably more optimal than greedy execution even from centralized value-decomposition methods. Empirically, we show that AGP achieves 80-95\% success on canonical coordination tasks with partial observability and anti-coordination penalties, where other MARL methods reach only 10-25\%. We further demonstrate that AGP consistently outperforms these baselines in diverse multi-agent environments.
TIGER-MARL: Enhancing Multi-Agent Reinforcement Learning with Temporal Information through Graph-based Embeddings and Representations
Nov 11, 2025



In this paper, we propose capturing and utilizing \textit{Temporal Information through Graph-based Embeddings and Representations} or \textbf{TIGER} to enhance multi-agent reinforcement learning (MARL). We explicitly model how inter-agent coordination structures evolve over time. While most MARL approaches rely on static or per-step relational graphs, they overlook the temporal evolution of interactions that naturally arise as agents adapt, move, or reorganize cooperation strategies. Capturing such evolving dependencies is key to achieving robust and adaptive coordination. To this end, TIGER constructs dynamic temporal graphs of MARL agents, connecting their current and historical interactions. It then employs a temporal attention-based encoder to aggregate information across these structural and temporal neighborhoods, yielding time-aware agent embeddings that guide cooperative policy learning. Through extensive experiments on two coordination-intensive benchmarks, we show that TIGER consistently outperforms diverse value-decomposition and graph-based MARL baselines in task performance and sample efficiency. Furthermore, we conduct comprehensive ablation studies to isolate the impact of key design parameters in TIGER, revealing how structural and temporal factors can jointly shape effective policy learning in MARL. All codes can be found here: https://github.com/Nikunj-Gupta/tiger-marl.
Deep Meta Coordination Graphs for Multi-agent Reinforcement Learning
Feb 06, 2025



This paper presents deep meta coordination graphs (DMCG) for learning cooperative policies in multi-agent reinforcement learning (MARL). Coordination graph formulations encode local interactions and accordingly factorize the joint value function of all agents to improve efficiency in MARL. However, existing approaches rely solely on pairwise relations between agents, which potentially oversimplifies complex multi-agent interactions. DMCG goes beyond these simple direct interactions by also capturing useful higher-order and indirect relationships among agents. It generates novel graph structures accommodating multiple types of interactions and arbitrary lengths of multi-hop connections in coordination graphs to model such interactions. It then employs a graph convolutional network module to learn powerful representations in an end-to-end manner. We demonstrate its effectiveness in multiple coordination problems in MARL where other state-of-the-art methods can suffer from sample inefficiency or fail entirely. All codes can be found here: https://github.com/Nikunj-Gupta/dmcg-marl.
Enhancing Multi-Agent Coordination through Common Operating Picture Integration
Nov 08, 2023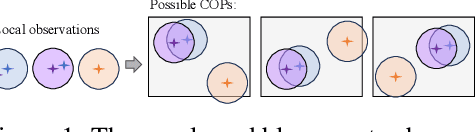
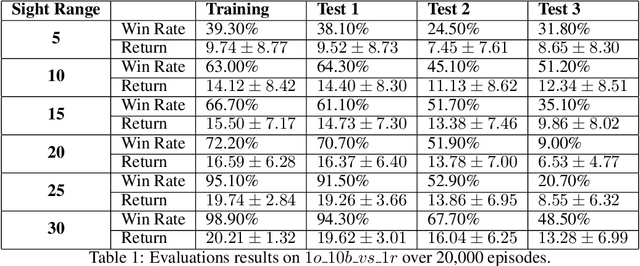
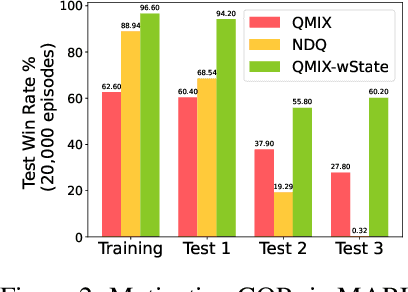

In multi-agent systems, agents possess only local observations of the environment. Communication between teammates becomes crucial for enhancing coordination. Past research has primarily focused on encoding local information into embedding messages which are unintelligible to humans. We find that using these messages in agent's policy learning leads to brittle policies when tested on out-of-distribution initial states. We present an approach to multi-agent coordination, where each agent is equipped with the capability to integrate its (history of) observations, actions and messages received into a Common Operating Picture (COP) and disseminate the COP. This process takes into account the dynamic nature of the environment and the shared mission. We conducted experiments in the StarCraft2 environment to validate our approach. Our results demonstrate the efficacy of COP integration, and show that COP-based training leads to robust policies compared to state-of-the-art Multi-Agent Reinforcement Learning (MARL) methods when faced with out-of-distribution initial states.