 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierRouter: Coordinated Routing of Specialized Large Language Models via Reinforcement Learning
Nov 13, 2025Large Language Models (LLMs) deliver state-of-the-art performance across many tasks but impose high computational and memory costs, limiting their deployment in resource-constrained or real-time settings. To address this, we propose HierRouter, a hierarchical routing approach that dynamically assembles inference pipelines from a pool of specialized, lightweight language models. Formulated as a finite-horizon Markov Decision Process (MDP), our approach trains a Proximal Policy Optimization (PPO)-based reinforcement learning agent to iteratively select which models to invoke at each stage of multi-hop inference. The agent conditions on the evolving context and accumulated cost to make context-aware routing decisions. Experiments with three open-source candidate LLMs across six benchmarks, including QA, code generation, and mathematical reasoning, show that HierRouter improves response quality by up to 2.4x compared to using individual models independently, while incurring only a minimal additional inference cost on average. These results highlight the promise of hierarchical routing for cost-efficient, high-performance LLM inference. All codes can be found here https://github.com/ Nikunj-Gupta/hierouter.
TIGER-MARL: Enhancing Multi-Agent Reinforcement Learning with Temporal Information through Graph-based Embeddings and Representations
Nov 11, 2025



In this paper, we propose capturing and utilizing \textit{Temporal Information through Graph-based Embeddings and Representations} or \textbf{TIGER} to enhance multi-agent reinforcement learning (MARL). We explicitly model how inter-agent coordination structures evolve over time. While most MARL approaches rely on static or per-step relational graphs, they overlook the temporal evolution of interactions that naturally arise as agents adapt, move, or reorganize cooperation strategies. Capturing such evolving dependencies is key to achieving robust and adaptive coordination. To this end, TIGER constructs dynamic temporal graphs of MARL agents, connecting their current and historical interactions. It then employs a temporal attention-based encoder to aggregate information across these structural and temporal neighborhoods, yielding time-aware agent embeddings that guide cooperative policy learning. Through extensive experiments on two coordination-intensive benchmarks, we show that TIGER consistently outperforms diverse value-decomposition and graph-based MARL baselines in task performance and sample efficiency. Furthermore, we conduct comprehensive ablation studies to isolate the impact of key design parameters in TIGER, revealing how structural and temporal factors can jointly shape effective policy learning in MARL. All codes can be found here: https://github.com/Nikunj-Gupta/tiger-marl.
Deep Meta Coordination Graphs for Multi-agent Reinforcement Learning
Feb 06, 2025



This paper presents deep meta coordination graphs (DMCG) for learning cooperative policies in multi-agent reinforcement learning (MARL). Coordination graph formulations encode local interactions and accordingly factorize the joint value function of all agents to improve efficiency in MARL. However, existing approaches rely solely on pairwise relations between agents, which potentially oversimplifies complex multi-agent interactions. DMCG goes beyond these simple direct interactions by also capturing useful higher-order and indirect relationships among agents. It generates novel graph structures accommodating multiple types of interactions and arbitrary lengths of multi-hop connections in coordination graphs to model such interactions. It then employs a graph convolutional network module to learn powerful representations in an end-to-end manner. We demonstrate its effectiveness in multiple coordination problems in MARL where other state-of-the-art methods can suffer from sample inefficiency or fail entirely. All codes can be found here: https://github.com/Nikunj-Gupta/dmcg-marl.
On the calibration of compartmental epidemiological models
Dec 09, 2023



Epidemiological compartmental models are useful for understanding infectious disease propagation and directing public health policy decisions. Calibration of these models is an important step in offering accurate forecasts of disease dynamics and the effectiveness of interventions. In this study, we present an overview of calibrating strategies that can be employed, including several optimization methods and reinforcement learning (RL). We discuss the benefits and drawbacks of these methods and highlight relevant practical conclusions from our experiments. Optimization methods iteratively adjust the parameters of the model until the model output matches the available data, whereas RL uses trial and error to learn the optimal set of parameters by maximizing a reward signal. Finally, we discuss how the calibration of parameters of epidemiological compartmental models is an emerging field that has the potential to improve the accuracy of disease modeling and public health decision-making. Further research is needed to validate the effectiveness and scalability of these approaches in different epidemiological contexts. All codes and resources are available on \url{https://github.com/Nikunj-Gupta/On-the-Calibration-of-Compartmental-Epidemiological-Models}. We hope this work can facilitate related research.
Understanding human mobility patterns in Chicago: an analysis of taxi data using clustering techniques
Jun 21, 2023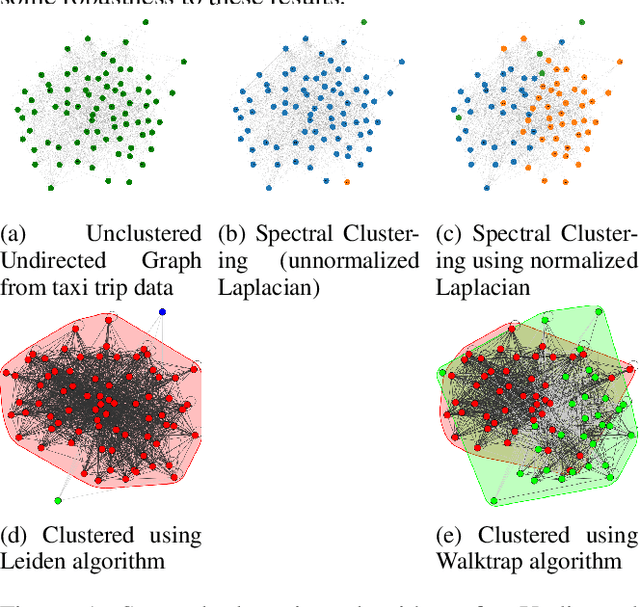
Understanding human mobility patterns is important in applications as diverse as urban planning, public health, and political organizing. One rich source of data on human mobility is taxi ride data. Using the city of Chicago as a case study, we examine data from taxi rides in 2016 with the goal of understanding how neighborhoods are interconnected. This analysis will provide a sense of which neighborhoods individuals are using taxis to travel between, suggesting regions to focus new public transit development efforts. Additionally, this analysis will map traffic circulation patterns and provide an understanding of where in the city people are traveling from and where they are heading to - perhaps informing traffic or road pollution mitigation efforts. For the first application, representing the data as an undirected graph will suffice. Transit lines run in both directions so simply a knowledge of which neighborhoods have high rates of taxi travel between them provides an argument for placing public transit along those routes. However, in order to understand the flow of people throughout a city, we must make a distinction between the neighborhood from which people are departing and the areas to which they are arriving - this requires methods that can deal with directed graphs. All developed codes can be found at https://github.com/Nikunj-Gupta/Spectral-Clustering-Directed-Graphs.
Efficient ResNets: Residual Network Design
Jun 21, 2023



ResNets (or Residual Networks) are one of the most commonly used models for image classification tasks. In this project, we design and train a modified ResNet model for CIFAR-10 image classification. In particular, we aimed at maximizing the test accuracy on the CIFAR-10 benchmark while keeping the size of our ResNet model under the specified fixed budget of 5 million trainable parameters. Model size, typically measured as the number of trainable parameters, is important when models need to be stored on devices with limited storage capacity (e.g. IoT/edge devices). In this article, we present our residual network design which has less than 5 million parameters. We show that our ResNet achieves a test accuracy of 96.04% on CIFAR-10 which is much higher than ResNet18 (which has greater than 11 million trainable parameters) when equipped with a number of training strategies and suitable ResNet hyperparameters. Models and code are available at https://github.com/Nikunj-Gupta/Efficient_ResNets.
CAMMARL: Conformal Action Modeling in Multi Agent Reinforcement Learning
Jun 19, 2023


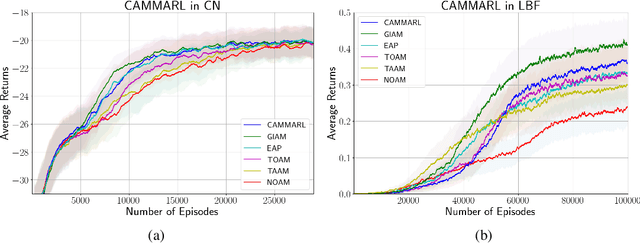
Before taking actions in an environment with more than one intelligent agent, an autonomous agent may benefit from reasoning about the other agents and utilizing a notion of a guarantee or confidence about the behavior of the system. In this article, we propose a novel multi-agent reinforcement learning (MARL) algorithm CAMMARL, which involves modeling the actions of other agents in different situations in the form of confident sets, i.e., sets containing their true actions with a high probability. We then use these estimates to inform an agent's decision-making. For estimating such sets, we use the concept of conformal predictions, by means of which, we not only obtain an estimate of the most probable outcome but get to quantify the operable uncertainty as well. For instance, we can predict a set that provably covers the true predictions with high probabilities (e.g., 95%). Through several experiments in two fully cooperative multi-agent tasks, we show that CAMMARL elevates the capabilities of an autonomous agent in MARL by modeling conformal prediction sets over the behavior of other agents in the environment and utilizing such estimates to enhance its policy learning. All developed codes can be found here: https://github.com/Nikunj-Gupta/conformal-agent-modelling.
Predicting blood pressure under circumstances of missing data: An analysis of missing data patterns and imputation methods using NHANES
May 01, 2023The World Health Organization defines cardio-vascular disease (CVD) as "a group of disorders of the heart and blood vessels," including coronary heart disease and stroke (WHO 21). CVD is affected by "intermediate risk factors" such as raised blood pressure, raised blood glucose, raised blood lipids, and obesity. These are predominantly influenced by lifestyle and behaviour, including physical inactivity, unhealthy diets, high intake of salt, and tobacco and alcohol use. However, genetics and social/environmental factors such as poverty, stress, and racism also play an important role. Researchers studying the behavioural and environmental factors associated with these "intermediate risk factors" need access to high quality and detailed information on diet and physical activity. However, missing data are a pervasive problem in clinical and public health research, affecting both randomized trials and observational studies. Reasons for missing data can vary substantially across studies because of loss to follow-up, missed study visits, refusal to answer survey questions, or an unrecorded measurement during an office visit. One method of handling missing values is to simply delete observations for which there is missingness (called Complete Case Analysis). This is rarely used as deleting the data point containing missing data (List wise deletion) results in a smaller number of samples and thus affects accuracy. Additional methods of handling missing data exists, such as summarizing the variables with its observed values (Available Case Analysis). Motivated by the pervasiveness of missing data in the NHANES dataset, we will conduct an analysis of imputation methods under different simulated patterns of missing data. We will then apply these imputation methods to create a complete dataset upon which we can use ordinary least squares to predict blood pressure from diet and physical activity.
Planning Multiple Epidemic Interventions with Reinforcement Learning
Jan 30, 2023Combating an epidemic entails finding a plan that describes when and how to apply different interventions, such as mask-wearing mandates, vaccinations, school or workplace closures. An optimal plan will curb an epidemic with minimal loss of life, disease burden, and economic cost. Finding an optimal plan is an intractable computational problem in realistic settings. Policy-makers, however, would greatly benefit from tools that can efficiently search for plans that minimize disease and economic costs especially when considering multiple possible interventions over a continuous and complex action space given a continuous and equally complex state space. We formulate this problem as a Markov decision process. Our formulation is unique in its ability to represent multiple continuous interventions over any disease model defined by ordinary differential equations. We illustrate how to effectively apply state-of-the-art actor-critic reinforcement learning algorithms (PPO and SAC) to search for plans that minimize overall costs. We empirically evaluate the learning performance of these algorithms and compare their performance to hand-crafted baselines that mimic plans constructed by policy-makers. Our method outperforms baselines. Our work confirms the viability of a computational approach to support policy-makers
Prediction of drug effectiveness in rheumatoid arthritis patients based on machine learning algorithms
Oct 18, 2022
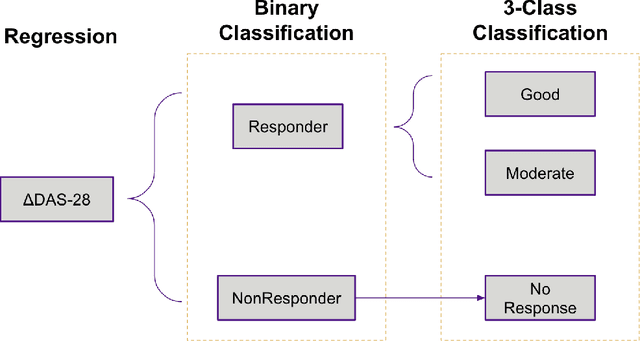

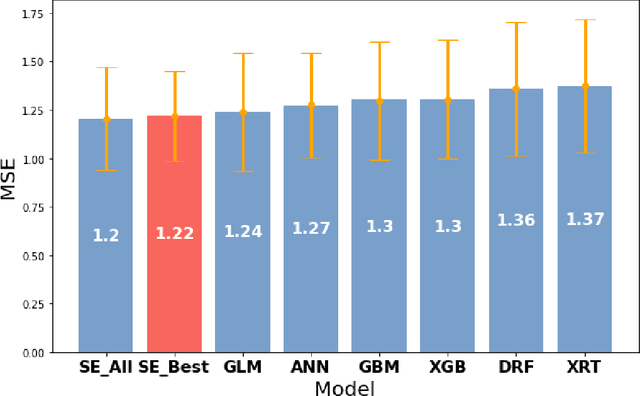
Rheumatoid arthritis (RA) is an autoimmune condition caused when patients' immune system mistakenly targets their own tissue. Machine learning (ML) has the potential to identify patterns in patient electronic health records (EHR) to forecast the best clinical treatment to improve patient outcomes. This study introduced a Drug Response Prediction (DRP) framework with two main goals: 1) design a data processing pipeline to extract information from tabular clinical data, and then preprocess it for functional use, and 2) predict RA patient's responses to drugs and evaluate classification models' performance. We propose a novel two-stage ML framework based on European Alliance of Associations for Rheumatology (EULAR) criteria cutoffs to model drug effectiveness. Our model Stacked-Ensemble DRP was developed and cross-validated using data from 425 RA patients. The evaluation used a subset of 124 patients (30%) from the same data source. In the evaluation of the test set, two-stage DRP leads to improved classification accuracy over other end-to-end classification models for binary classification. Our proposed method provides a complete pipeline to predict disease activity scores and identify the group that does not respond well to anti-TNF treatments, thus showing promise in supporting clinical decisions based on EHR information.