 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on the Integration of Generative AI for Critical Thinking in Mobile Networks
Apr 10, 2024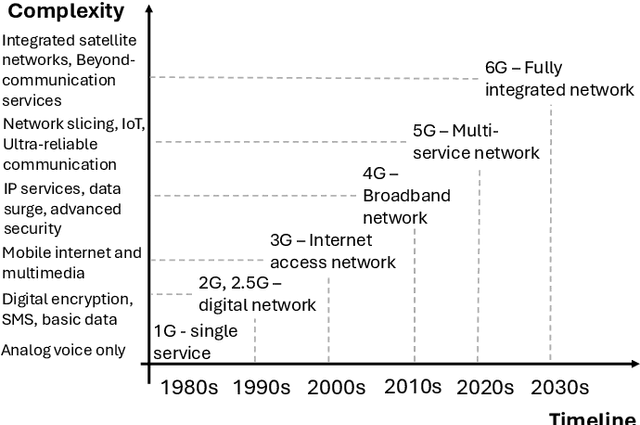
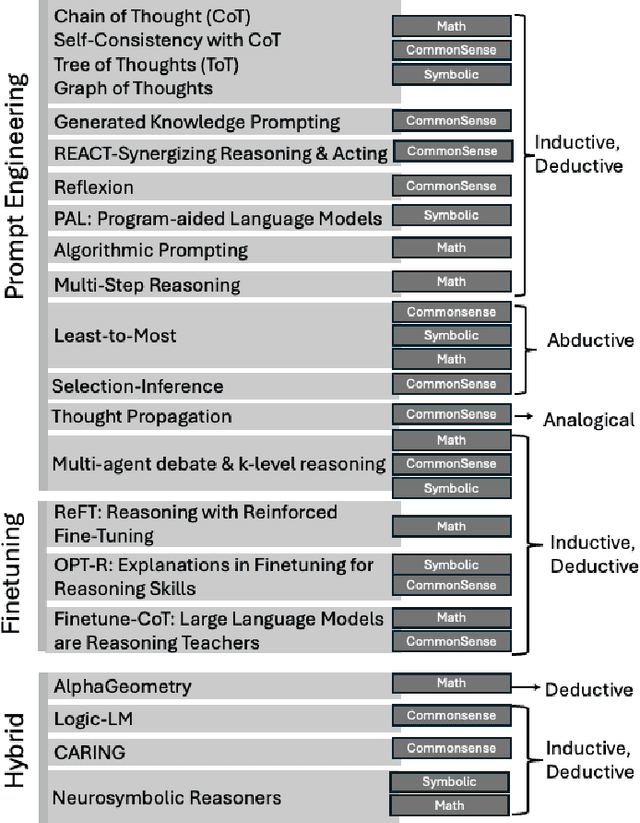
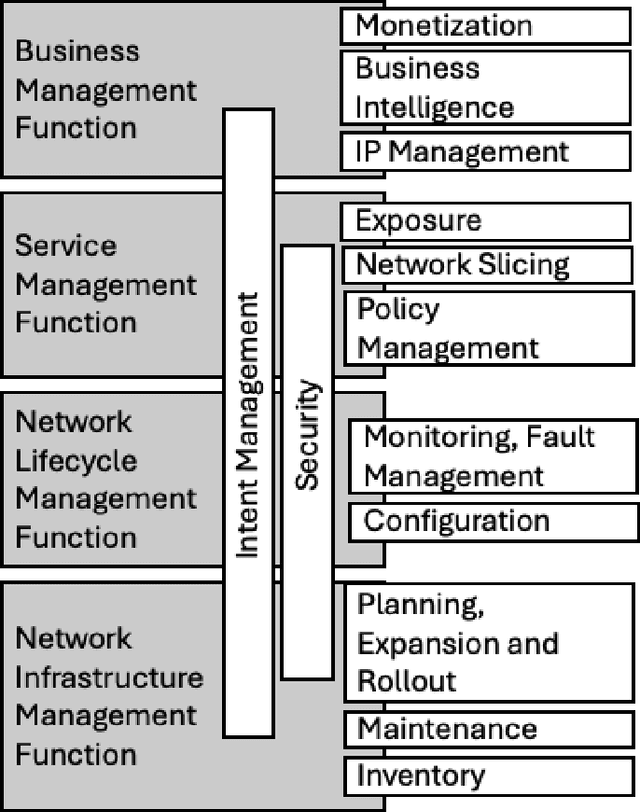
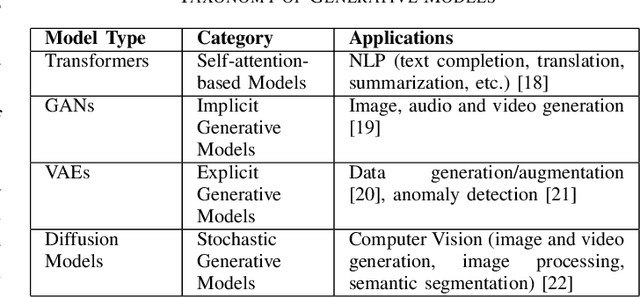
In the near future, mobile networks are expected to broaden their services and coverage to accommodate a larger user base and diverse user needs. Thus, they will increasingly rely on artificial intelligence (AI) to manage network operation and control costs, undertaking complex decision-making roles. This shift will necessitate the application of techniques that incorporate critical thinking abilities, including reasoning and planning. Symbolic AI techniques already facilitate critical thinking based on existing knowledge. Yet, their use in telecommunications is hindered by the high cost of mostly manual curation of this knowledge and high computational complexity of reasoning tasks. At the same time, there is a spurt of innovations in industries such as telecommunications due to Generative AI (GenAI) technologies, operating independently of human-curated knowledge. However, their capacity for critical thinking remains uncertain. This paper aims to address this gap by examining the current status of GenAI algorithms with critical thinking capabilities and investigating their potential applications in telecom networks. Specifically, the aim of this study is to offer an introduction to the potential utilization of GenAI for critical thinking techniques in mobile networks, while also establishing a foundation for future research.
Fast Falsification of Neural Networks using Property Directed Testing
Apr 26, 2021
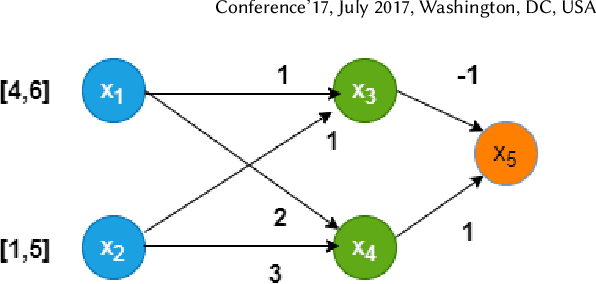
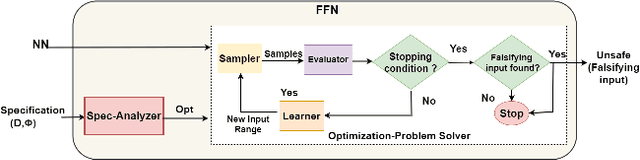
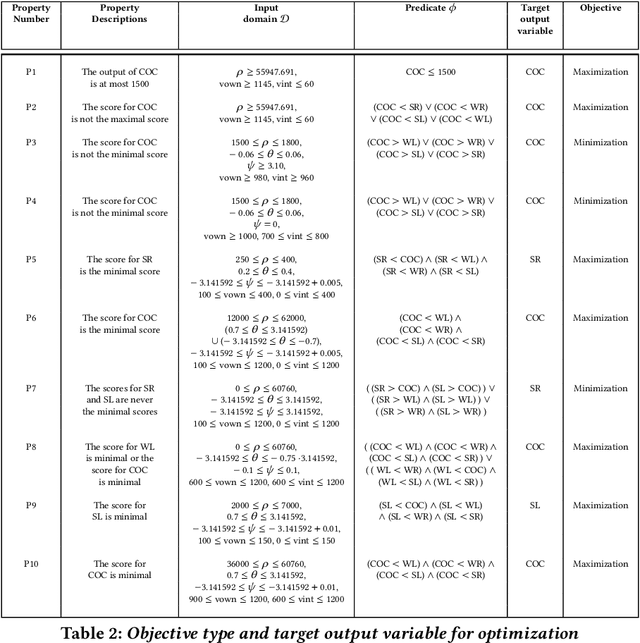
Neural networks are now extensively used in perception, prediction and control of autonomous systems. Their deployment in safety-critical systems brings forth the need for verification techniques for such networks. As an alternative to exhaustive and costly verification algorithms, lightweight falsification algorithms have been heavily used to search for an input to the system that produces an unsafe output, i.e., a counterexample to the safety of the system. In this work, we propose a falsification algorithm for neural networks that directs the search for a counterexample, guided by a safety property specification. Our algorithm uses a derivative-free sampling-based optimization method. We evaluate our algorithm on 45 trained neural network benchmarks of the ACAS Xu system against 10 safety properties. We show that our falsification procedure detects all the unsafe instances that other verification tools also report as unsafe. Moreover, in terms of performance, our falsification procedure identifies most of the unsafe instances faster, in comparison to the state-of-the-art verification tools for feed-forward neural networks such as NNENUM and Neurify and in many instances, by orders of magnitude.
HAMMER: Multi-Level Coordination of Reinforcement Learning Agents via Learned Messaging
Jan 18, 2021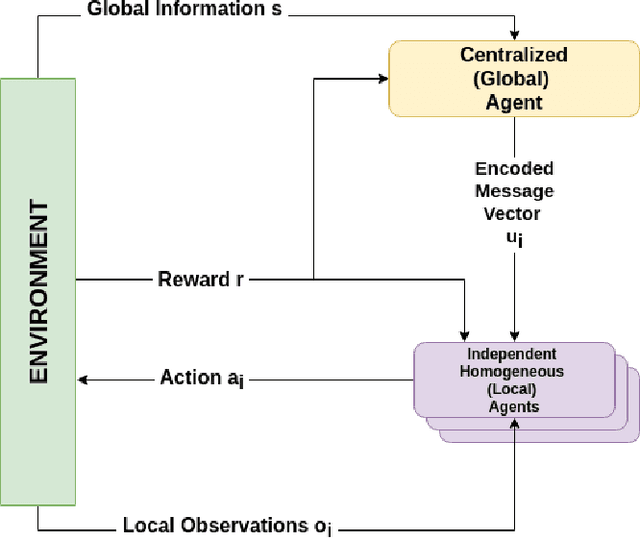
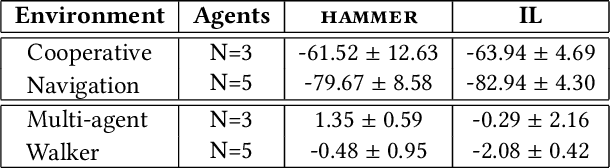


Cooperative multi-agent reinforcement learning (MARL) has achieved significant results, most notably by leveraging the representation learning abilities of deep neural networks. However, large centralized approaches quickly become infeasible as the number of agents scale, and fully decentralized approaches can miss important opportunities for information sharing and coordination. Furthermore, not all agents are equal - in some cases, individual agents may not even have the ability to send communication to other agents or explicitly model other agents. This paper considers the case where there is a single, powerful, central agent that can observe the entire observation space, and there are multiple, low powered, local agents that can only receive local observations and cannot communicate with each other. The job of the central agent is to learn what message to send to different local agents, based on the global observations, not by centrally solving the entire problem and sending action commands, but by determining what additional information an individual agent should receive so that it can make a better decision. After explaining our MARL algorithm, hammer, and where it would be most applicable, we implement it in the cooperative navigation and multi-agent walker domains. Empirical results show that 1) learned communication does indeed improve system performance, 2) results generalize to multiple numbers of agents, and 3) results generalize to different reward structures.
Machine Reasoning Explainability
Sep 01, 2020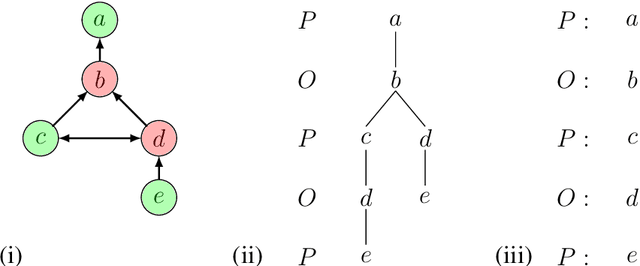
As a field of AI, Machine Reasoning (MR) uses largely symbolic means to formalize and emulate abstract reasoning. Studies in early MR have notably started inquiries into Explainable AI (XAI) -- arguably one of the biggest concerns today for the AI community. Work on explainable MR as well as on MR approaches to explainability in other areas of AI has continued ever since. It is especially potent in modern MR branches, such as argumentation, constraint and logic programming, planning. We hereby aim to provide a selective overview of MR explainability techniques and studies in hopes that insights from this long track of research will complement well the current XAI landscape. This document reports our work in-progress on MR explainability.
Antifragility for Intelligent Autonomous Systems
Feb 26, 2018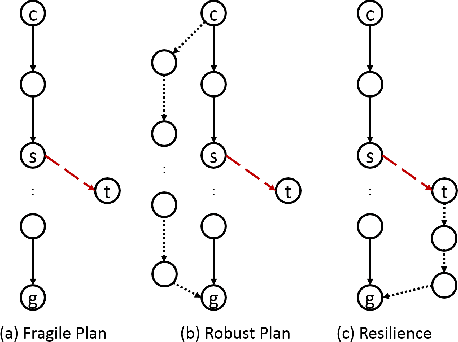

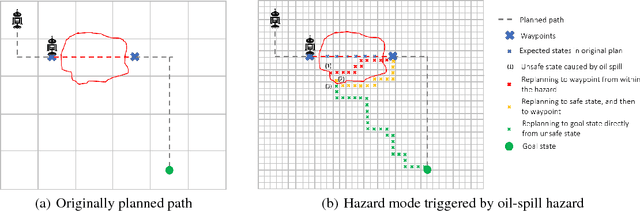
Antifragile systems grow measurably better in the presence of hazards. This is in contrast to fragile systems which break down in the presence of hazards, robust systems that tolerate hazards up to a certain degree, and resilient systems that -- like self-healing systems -- revert to their earlier expected behavior after a period of convalescence. The notion of antifragility was introduced by Taleb for economics systems, but its applicability has been illustrated in biological and engineering domains as well. In this paper, we propose an architecture that imparts antifragility to intelligent autonomous systems, specifically those that are goal-driven and based on AI-planning. We argue that this architecture allows the system to self-improve by uncovering new capabilities obtained either through the hazards themselves (opportunistic) or through deliberation (strategic). An AI planning-based case study of an autonomous wheeled robot is presented. We show that with the proposed architecture, the robot develops antifragile behaviour with respect to an oil spill hazard.