 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Falsification of Neural Networks using Property Directed Testing
Paper and Code
Apr 26, 2021
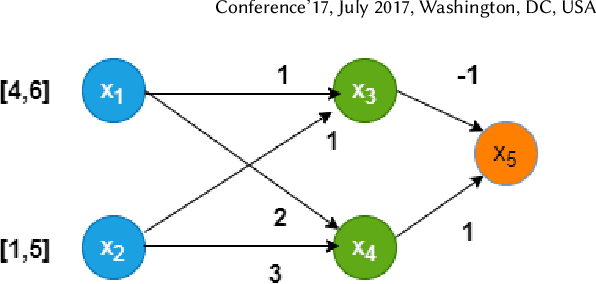
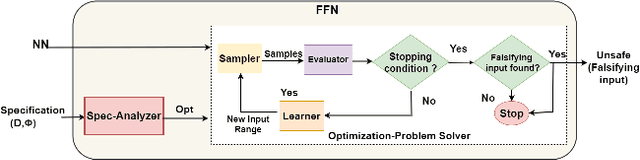
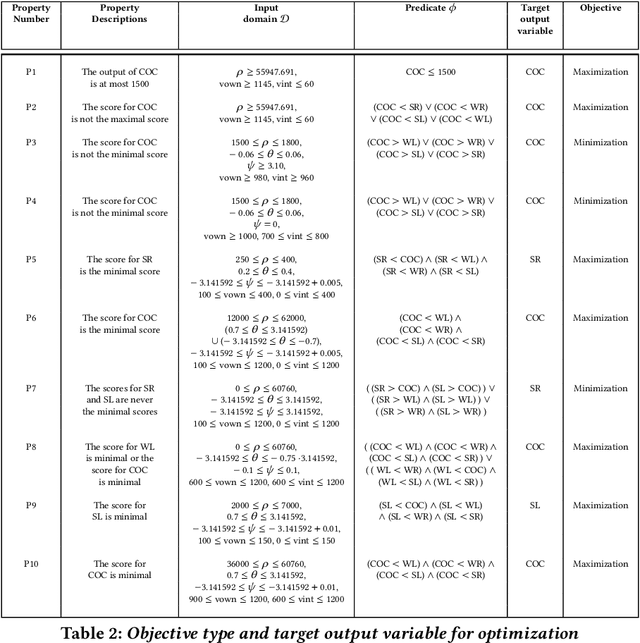
Neural networks are now extensively used in perception, prediction and control of autonomous systems. Their deployment in safety-critical systems brings forth the need for verification techniques for such networks. As an alternative to exhaustive and costly verification algorithms, lightweight falsification algorithms have been heavily used to search for an input to the system that produces an unsafe output, i.e., a counterexample to the safety of the system. In this work, we propose a falsification algorithm for neural networks that directs the search for a counterexample, guided by a safety property specification. Our algorithm uses a derivative-free sampling-based optimization method. We evaluate our algorithm on 45 trained neural network benchmarks of the ACAS Xu system against 10 safety properties. We show that our falsification procedure detects all the unsafe instances that other verification tools also report as unsafe. Moreover, in terms of performance, our falsification procedure identifies most of the unsafe instances faster, in comparison to the state-of-the-art verification tools for feed-forward neural networks such as NNENUM and Neurify and in many instances, by orders of magnitude.