 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Reasoning Explainability
Sep 01, 2020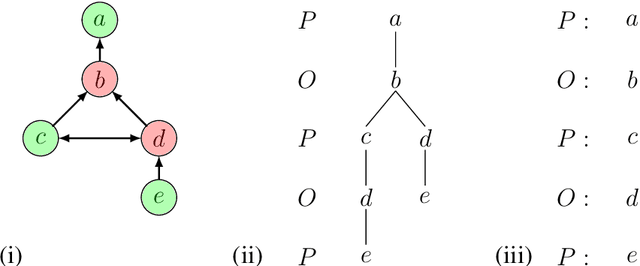
As a field of AI, Machine Reasoning (MR) uses largely symbolic means to formalize and emulate abstract reasoning. Studies in early MR have notably started inquiries into Explainable AI (XAI) -- arguably one of the biggest concerns today for the AI community. Work on explainable MR as well as on MR approaches to explainability in other areas of AI has continued ever since. It is especially potent in modern MR branches, such as argumentation, constraint and logic programming, planning. We hereby aim to provide a selective overview of MR explainability techniques and studies in hopes that insights from this long track of research will complement well the current XAI landscape. This document reports our work in-progress on MR explainability.
Antifragility for Intelligent Autonomous Systems
Feb 26, 2018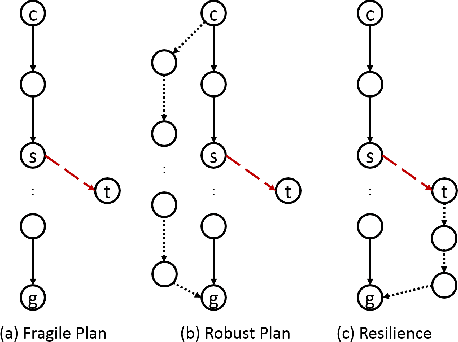

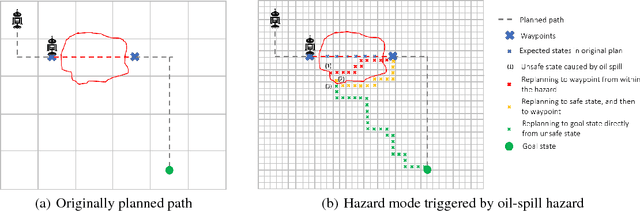
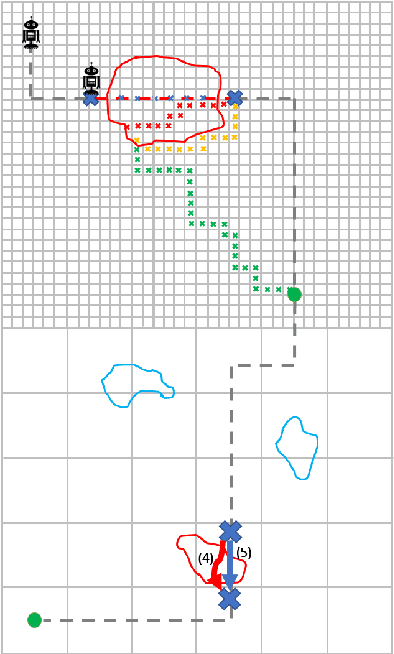
Antifragile systems grow measurably better in the presence of hazards. This is in contrast to fragile systems which break down in the presence of hazards, robust systems that tolerate hazards up to a certain degree, and resilient systems that -- like self-healing systems -- revert to their earlier expected behavior after a period of convalescence. The notion of antifragility was introduced by Taleb for economics systems, but its applicability has been illustrated in biological and engineering domains as well. In this paper, we propose an architecture that imparts antifragility to intelligent autonomous systems, specifically those that are goal-driven and based on AI-planning. We argue that this architecture allows the system to self-improve by uncovering new capabilities obtained either through the hazards themselves (opportunistic) or through deliberation (strategic). An AI planning-based case study of an autonomous wheeled robot is presented. We show that with the proposed architecture, the robot develops antifragile behaviour with respect to an oil spill hazard.