 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen to restart? Exploring escalating restarts on convergence
Mar 04, 2026Learning rate scheduling plays a critical role in the optimization of deep neural networks, directly influencing convergence speed, stability, and generalization. While existing schedulers such as cosine annealing, cyclical learning rates, and warm restarts have shown promise, they often rely on fixed or periodic triggers that are agnostic to the training dynamics, such as stagnation or convergence behavior. In this work, we propose a simple yet effective strategy, which we call Stochastic Gradient Descent with Escalating Restarts (SGD-ER). It adaptively increases the learning rate upon convergence. Our method monitors training progress and triggers restarts when stagnation is detected, linearly escalating the learning rate to escape sharp local minima and explore flatter regions of the loss landscape. We evaluate SGD-ER across CIFAR-10, CIFAR-100, and TinyImageNet on a range of architectures including ResNet-18/34/50, VGG-16, and DenseNet-101. Compared to standard schedulers, SGD-ER improves test accuracy by 0.5-4.5%, demonstrating the benefit of convergence-aware escalating restarts for better local optima.
Numeric Reward Machines
Apr 30, 2024
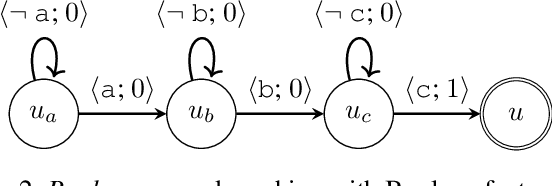
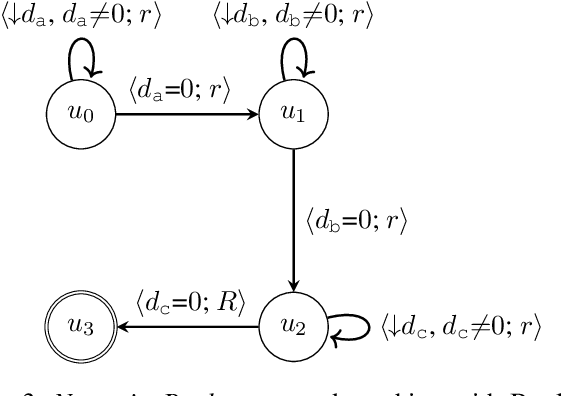
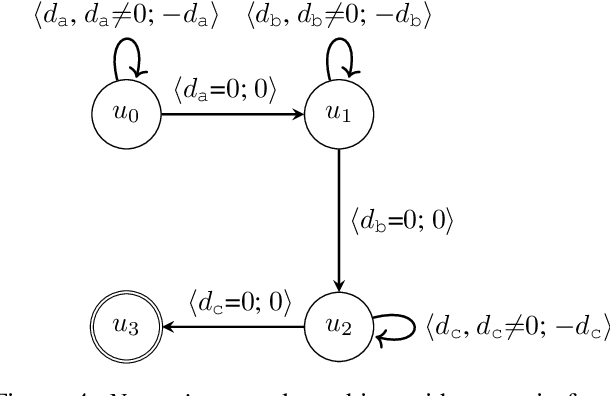
Reward machines inform reinforcement learning agents about the reward structure of the environment and often drastically speed up the learning process. However, reward machines only accept Boolean features such as robot-reached-gold. Consequently, many inherently numeric tasks cannot profit from the guidance offered by reward machines. To address this gap, we aim to extend reward machines with numeric features such as distance-to-gold. For this, we present two types of reward machines: numeric-Boolean and numeric. In a numeric-Boolean reward machine, distance-to-gold is emulated by two Boolean features distance-to-gold-decreased and robot-reached-gold. In a numeric reward machine, distance-to-gold is used directly alongside the Boolean feature robot-reached-gold. We compare our new approaches to a baseline reward machine in the Craft domain, where the numeric feature is the agent-to-target distance. We use cross-product Q-learning, Q-learning with counter-factual experiences, and the options framework for learning. Our experimental results show that our new approaches significantly outperform the baseline approach. Extending reward machines with numeric features opens up new possibilities of using reward machines in inherently numeric tasks.
A Survey on the Integration of Generative AI for Critical Thinking in Mobile Networks
Apr 10, 2024
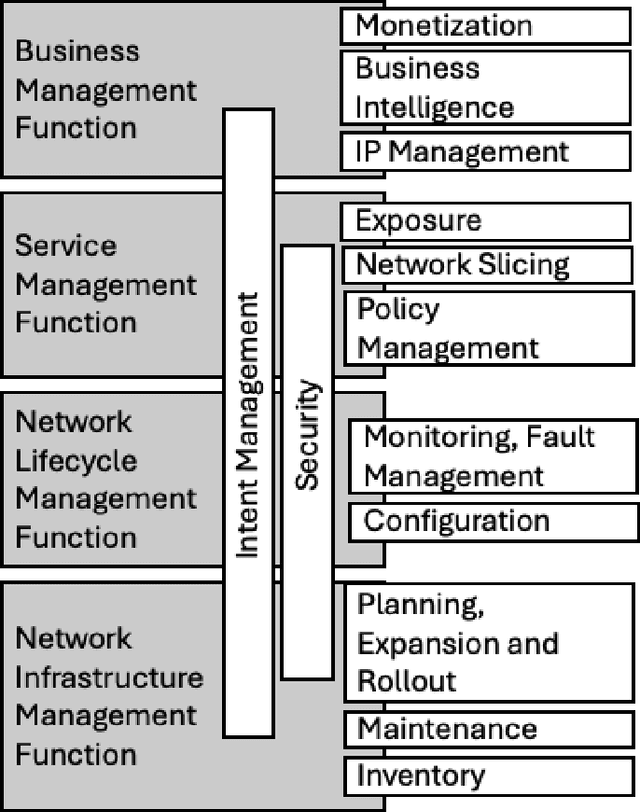
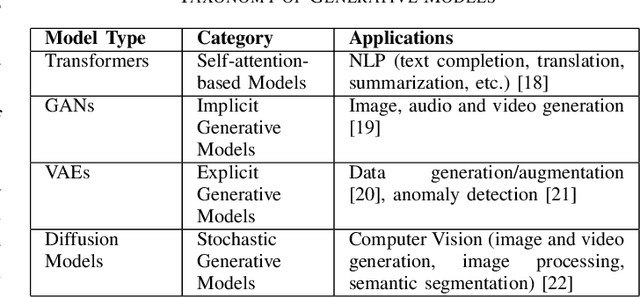
In the near future, mobile networks are expected to broaden their services and coverage to accommodate a larger user base and diverse user needs. Thus, they will increasingly rely on artificial intelligence (AI) to manage network operation and control costs, undertaking complex decision-making roles. This shift will necessitate the application of techniques that incorporate critical thinking abilities, including reasoning and planning. Symbolic AI techniques already facilitate critical thinking based on existing knowledge. Yet, their use in telecommunications is hindered by the high cost of mostly manual curation of this knowledge and high computational complexity of reasoning tasks. At the same time, there is a spurt of innovations in industries such as telecommunications due to Generative AI (GenAI) technologies, operating independently of human-curated knowledge. However, their capacity for critical thinking remains uncertain. This paper aims to address this gap by examining the current status of GenAI algorithms with critical thinking capabilities and investigating their potential applications in telecom networks. Specifically, the aim of this study is to offer an introduction to the potential utilization of GenAI for critical thinking techniques in mobile networks, while also establishing a foundation for future research.
Multi-agent transformer-accelerated RL for satisfaction of STL specifications
Mar 23, 2024One of the main challenges in multi-agent reinforcement learning is scalability as the number of agents increases. This issue is further exacerbated if the problem considered is temporally dependent. State-of-the-art solutions today mainly follow centralized training with decentralized execution paradigm in order to handle the scalability concerns. In this paper, we propose time-dependent multi-agent transformers which can solve the temporally dependent multi-agent problem efficiently with a centralized approach via the use of transformers that proficiently handle the large input. We highlight the efficacy of this method on two problems and use tools from statistics to verify the probability that the trajectories generated under the policy satisfy the task. The experiments show that our approach has superior performance against the literature baseline algorithms in both cases.
Safe RAN control: A Symbolic Reinforcement Learning Approach
Jun 03, 2021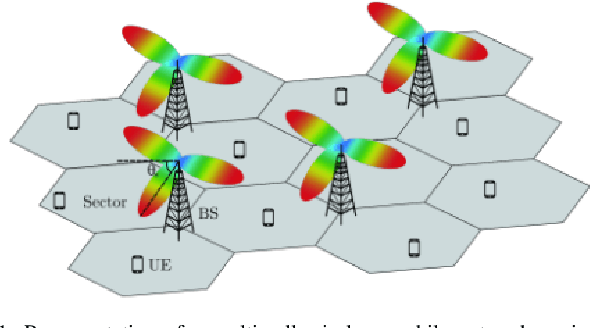
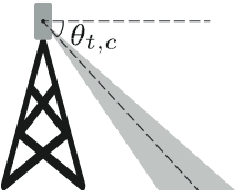
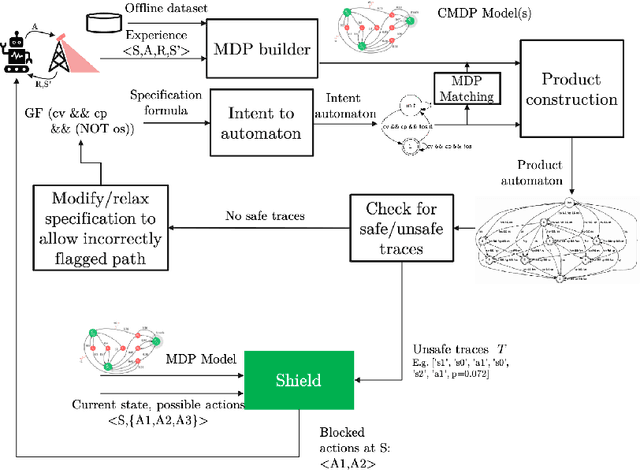
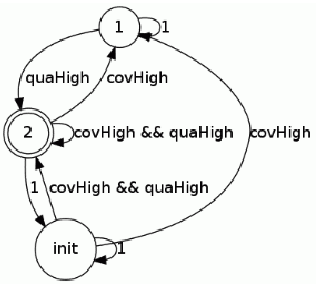
In this paper, we present a Symbolic Reinforcement Learning (SRL) based architecture for safety control of Radio Access Network (RAN) applications. In particular, we provide a purely automated procedure in which a user can specify high-level logical safety specifications for a given cellular network topology in order for the latter to execute optimal safe performance which is measured through certain Key Performance Indicators (KPIs). The network consists of a set of fixed Base Stations (BS) which are equipped with antennas, which one can control by adjusting their vertical tilt angle. The aforementioned process is called Remote Electrical Tilt (RET) optimization. Recent research has focused on performing this RET optimization by employing Reinforcement Learning (RL) strategies due to the fact that they have self-learning capabilities to adapt in uncertain environments. The term safety refers to particular constraints bounds of the network KPIs in order to guarantee that when the algorithms are deployed in a live network, the performance is maintained. In our proposed architecture the safety is ensured through model-checking techniques over combined discrete system models (automata) that are abstracted through the learning process. We introduce a user interface (UI) developed to help a user set intent specifications to the system, and inspect the difference in agent proposed actions, and those that are allowed and blocked according to the safety specification.
Distributed Learning in Wireless Networks: Recent Progress and Future Challenges
Apr 05, 2021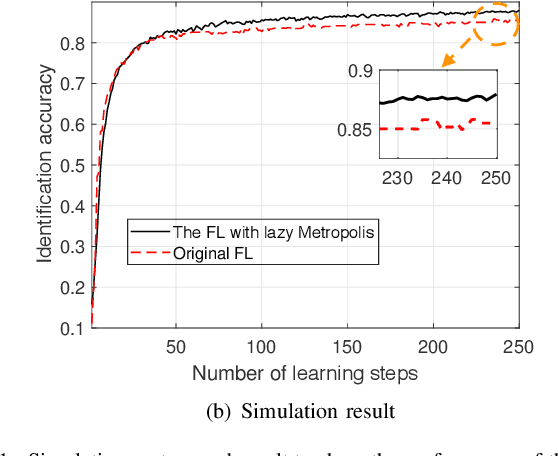
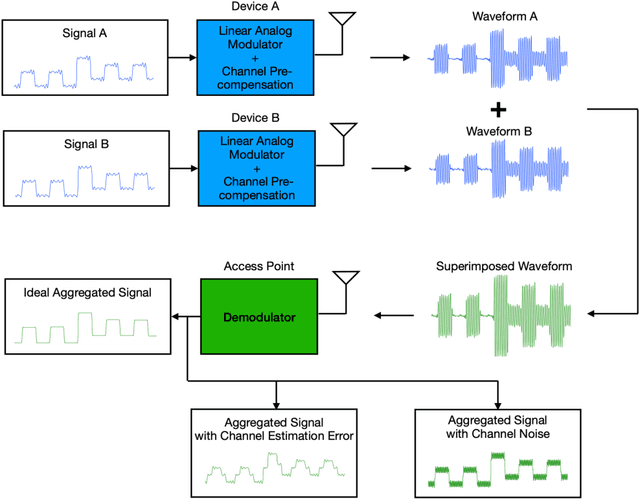
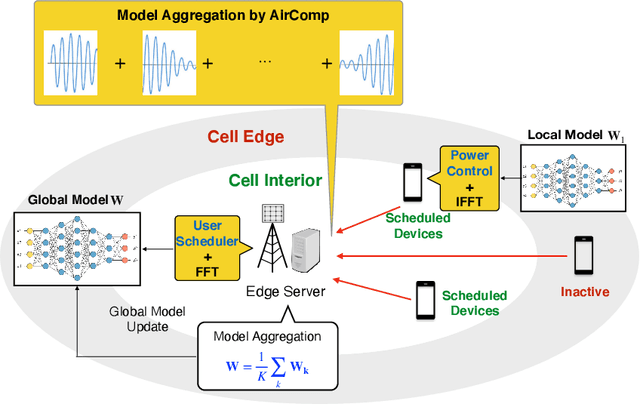
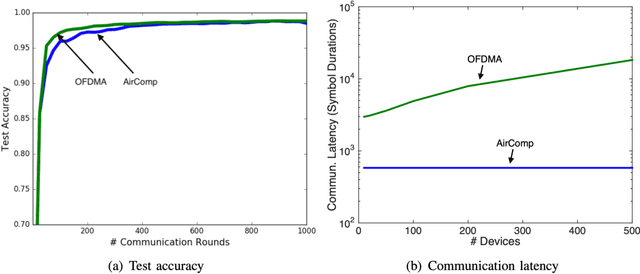
The next-generation of wireless networks will enable many machine learning (ML) tools and applications to efficiently analyze various types of data collected by edge devices for inference, autonomy, and decision making purposes. However, due to resource constraints, delay limitations, and privacy challenges, edge devices cannot offload their entire collected datasets to a cloud server for centrally training their ML models or inference purposes. To overcome these challenges, distributed learning and inference techniques have been proposed as a means to enable edge devices to collaboratively train ML models without raw data exchanges, thus reducing the communication overhead and latency as well as improving data privacy. However, deploying distributed learning over wireless networks faces several challenges including the uncertain wireless environment, limited wireless resources (e.g., transmit power and radio spectrum), and hardware resources. This paper provides a comprehensive study of how distributed learning can be efficiently and effectively deployed over wireless edge networks. We present a detailed overview of several emerging distributed learning paradigms, including federated learning, federated distillation, distributed inference, and multi-agent reinforcement learning. For each learning framework, we first introduce the motivation for deploying it over wireless networks. Then, we present a detailed literature review on the use of communication techniques for its efficient deployment. We then introduce an illustrative example to show how to optimize wireless networks to improve its performance. Finally, we introduce future research opportunities. In a nutshell, this paper provides a holistic set of guidelines on how to deploy a broad range of distributed learning frameworks over real-world wireless communication networks.
Symbolic Reinforcement Learning for Safe RAN Control
Mar 11, 2021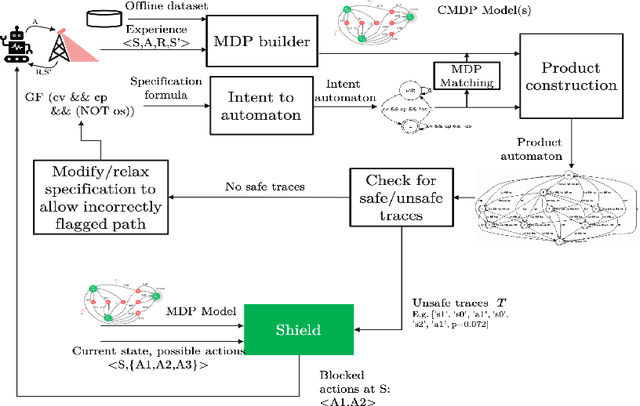
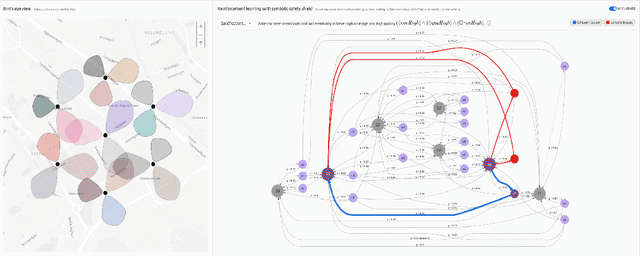
In this paper, we demonstrate a Symbolic Reinforcement Learning (SRL) architecture for safe control in Radio Access Network (RAN) applications. In our automated tool, a user can select a high-level safety specifications expressed in Linear Temporal Logic (LTL) to shield an RL agent running in a given cellular network with aim of optimizing network performance, as measured through certain Key Performance Indicators (KPIs). In the proposed architecture, network safety shielding is ensured through model-checking techniques over combined discrete system models (automata) that are abstracted through reinforcement learning. We demonstrate the user interface (UI) helping the user set intent specifications to the architecture and inspect the difference in allowed and blocked actions.
Machine Reasoning Explainability
Sep 01, 2020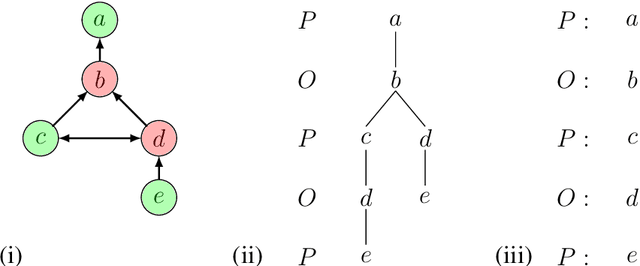
As a field of AI, Machine Reasoning (MR) uses largely symbolic means to formalize and emulate abstract reasoning. Studies in early MR have notably started inquiries into Explainable AI (XAI) -- arguably one of the biggest concerns today for the AI community. Work on explainable MR as well as on MR approaches to explainability in other areas of AI has continued ever since. It is especially potent in modern MR branches, such as argumentation, constraint and logic programming, planning. We hereby aim to provide a selective overview of MR explainability techniques and studies in hopes that insights from this long track of research will complement well the current XAI landscape. This document reports our work in-progress on MR explainability.
A Framework for Knowledge Management and Automated Reasoning Applied on Intelligent Transport Systems
Jan 11, 2017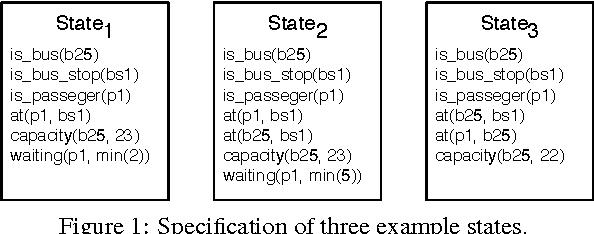
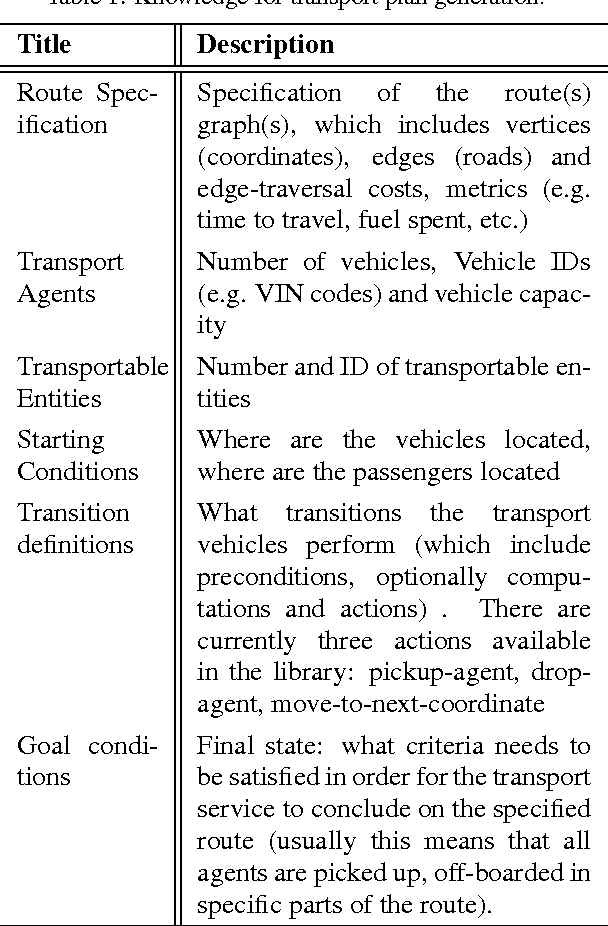
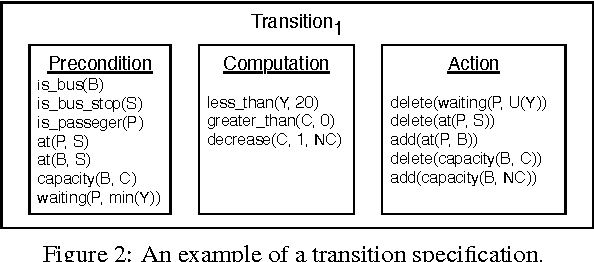
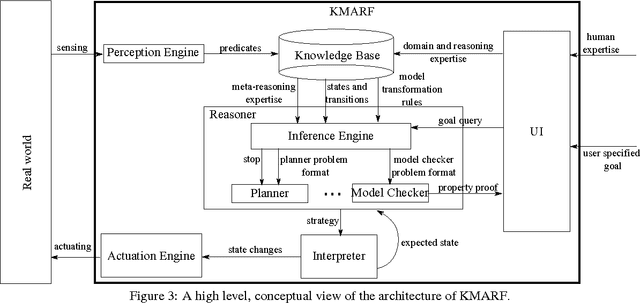
Cyber-Physical Systems in general, and Intelligent Transport Systems (ITS) in particular use heterogeneous data sources combined with problem solving expertise in order to make critical decisions that may lead to some form of actions e.g., driver notifications, change of traffic light signals and braking to prevent an accident. Currently, a major part of the decision process is done by human domain experts, which is time-consuming, tedious and error-prone. Additionally, due to the intrinsic nature of knowledge possession this decision process cannot be easily replicated or reused. Therefore, there is a need for automating the reasoning processes by providing computational systems a formal representation of the domain knowledge and a set of methods to process that knowledge. In this paper, we propose a knowledge model that can be used to express both declarative knowledge about the systems' components, their relations and their current state, as well as procedural knowledge representing possible system behavior. In addition, we introduce a framework for knowledge management and automated reasoning (KMARF). The idea behind KMARF is to automatically select an appropriate problem solver based on formalized reasoning expertise in the knowledge base, and convert a problem definition to the corresponding format. This approach automates reasoning, thus reducing operational costs, and enables reusability of knowledge and methods across different domains. We illustrate the approach on a transportation planning use case.