 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Layer-Wise Precision in Deep Neural Networks
Jul 03, 2018

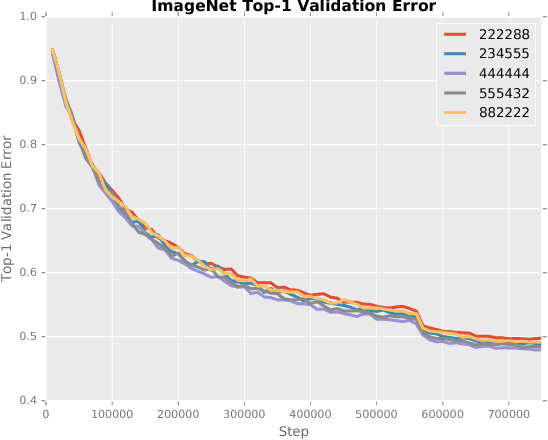

Low precision weights, activations, and gradients have been proposed as a way to improve the computational efficiency and memory footprint of deep neural networks. Recently, low precision networks have even shown to be more robust to adversarial attacks. However, typical implementations of low precision DNNs use uniform precision across all layers of the network. In this work, we explore whether a heterogeneous allocation of precision across a network leads to improved performance, and introduce a learning scheme where a DNN stochastically explores multiple precision configurations through learning. This permits a network to learn an optimal precision configuration. We show on convolutional neural networks trained on MNIST and ILSVRC12 that even though these nets learn a uniform or near-uniform allocation strategy respectively, stochastic precision leads to a favourable regularization effect improving generalization.
Caffeinated FPGAs: FPGA Framework For Convolutional Neural Networks
Sep 30, 2016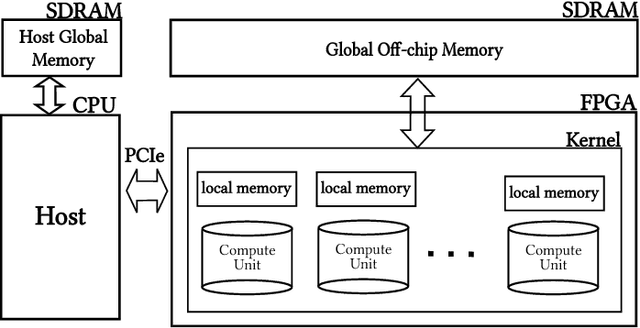
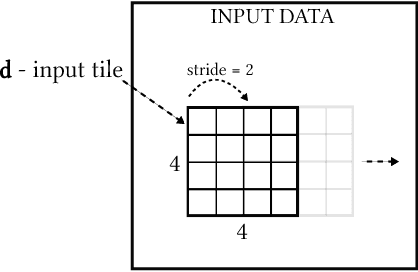

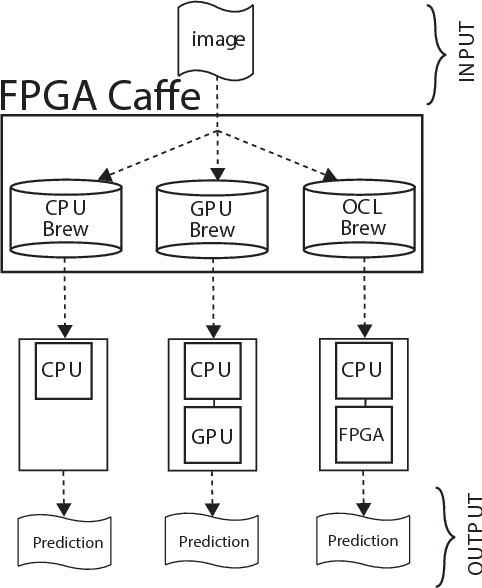
Convolutional Neural Networks (CNNs) have gained significant traction in the field of machine learning, particularly due to their high accuracy in visual recognition. Recent works have pushed the performance of GPU implementations of CNNs to significantly improve their classification and training times. With these improvements, many frameworks have become available for implementing CNNs on both CPUs and GPUs, with no support for FPGA implementations. In this work we present a modified version of the popular CNN framework Caffe, with FPGA support. This allows for classification using CNN models and specialized FPGA implementations with the flexibility of reprogramming the device when necessary, seamless memory transactions between host and device, simple-to-use test benches, and the ability to create pipelined layer implementations. To validate the framework, we use the Xilinx SDAccel environment to implement an FPGA-based Winograd convolution engine and show that the FPGA layer can be used alongside other layers running on a host processor to run several popular CNNs (AlexNet, GoogleNet, VGG A, Overfeat). The results show that our framework achieves 50 GFLOPS across 3x3 convolutions in the benchmarks. This is achieved within a practical framework, which will aid in future development of FPGA-based CNNs.
Learning Human Identity from Motion Patterns
Apr 21, 2016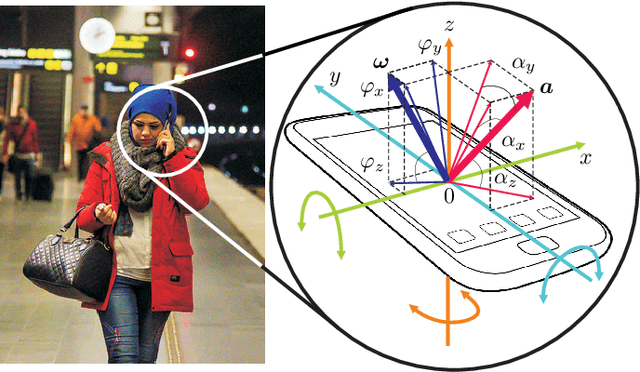
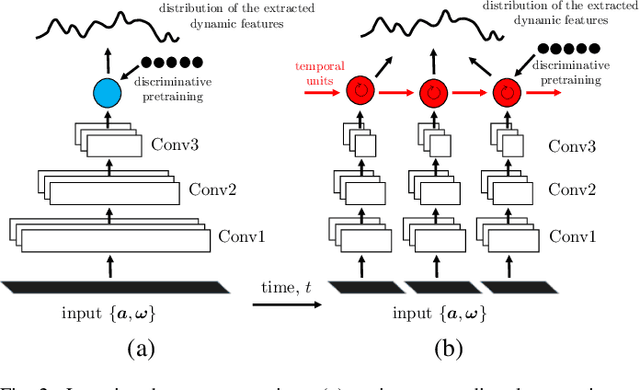
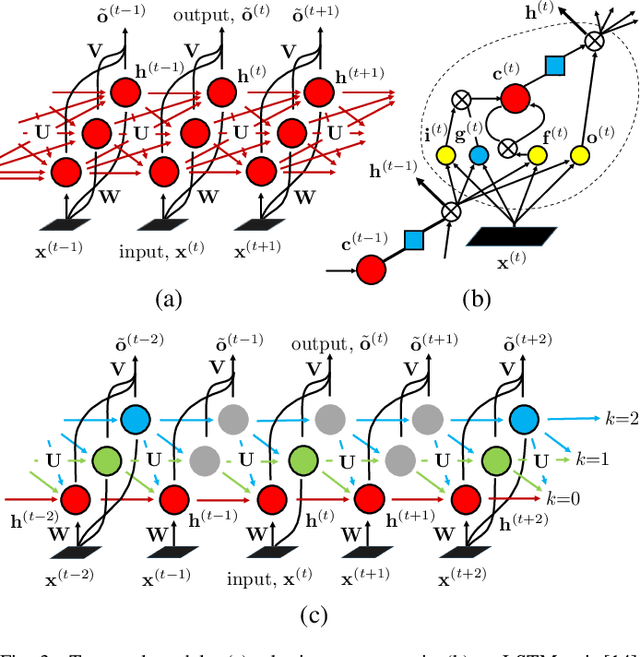
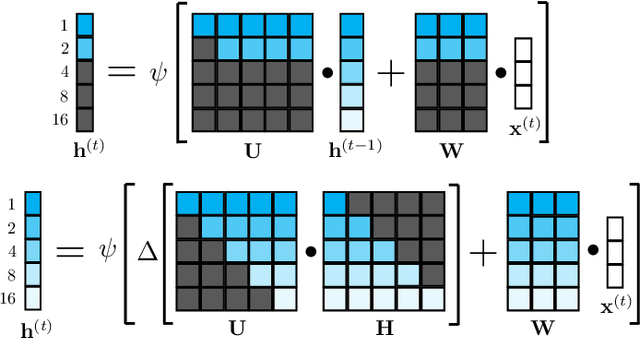
We present a large-scale study exploring the capability of temporal deep neural networks to interpret natural human kinematics and introduce the first method for active biometric authentication with mobile inertial sensors. At Google, we have created a first-of-its-kind dataset of human movements, passively collected by 1500 volunteers using their smartphones daily over several months. We (1) compare several neural architectures for efficient learning of temporal multi-modal data representations, (2) propose an optimized shift-invariant dense convolutional mechanism (DCWRNN), and (3) incorporate the discriminatively-trained dynamic features in a probabilistic generative framework taking into account temporal characteristics. Our results demonstrate that human kinematics convey important information about user identity and can serve as a valuable component of multi-modal authentication systems.
Deep Learning on FPGAs: Past, Present, and Future
Feb 13, 2016



The rapid growth of data size and accessibility in recent years has instigated a shift of philosophy in algorithm design for artificial intelligence. Instead of engineering algorithms by hand, the ability to learn composable systems automatically from massive amounts of data has led to ground-breaking performance in important domains such as computer vision, speech recognition, and natural language processing. The most popular class of techniques used in these domains is called deep learning, and is seeing significant attention from industry. However, these models require incredible amounts of data and compute power to train, and are limited by the need for better hardware acceleration to accommodate scaling beyond current data and model sizes. While the current solution has been to use clusters of graphics processing units (GPU) as general purpose processors (GPGPU), the use of field programmable gate arrays (FPGA) provide an interesting alternative. Current trends in design tools for FPGAs have made them more compatible with the high-level software practices typically practiced in the deep learning community, making FPGAs more accessible to those who build and deploy models. Since FPGA architectures are flexible, this could also allow researchers the ability to explore model-level optimizations beyond what is possible on fixed architectures such as GPUs. As well, FPGAs tend to provide high performance per watt of power consumption, which is of particular importance for application scientists interested in large scale server-based deployment or resource-limited embedded applications. This review takes a look at deep learning and FPGAs from a hardware acceleration perspective, identifying trends and innovations that make these technologies a natural fit, and motivates a discussion on how FPGAs may best serve the needs of the deep learning community moving forward.