 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Feasibility of Implementing Large-Scale Transformers on Multi-FPGA Platforms
Apr 24, 2024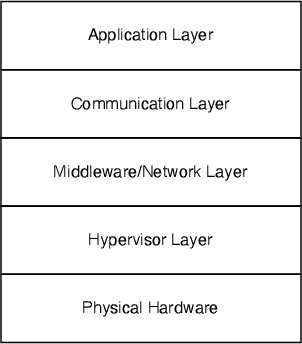

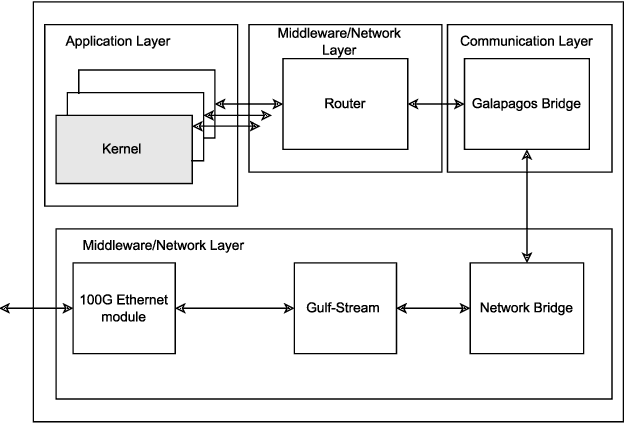

FPGAs are rarely mentioned when discussing the implementation of large machine learning applications, such as Large Language Models (LLMs), in the data center. There has been much evidence showing that single FPGAs can be competitive with GPUs in performance for some computations, especially for low latency, and often much more efficient when power is considered. This suggests that there is merit to exploring the use of multiple FPGAs for large machine learning applications. The challenge with using multiple FPGAs is that there is no commonly-accepted flow for developing and deploying multi-FPGA applications, i.e., there are no tools to describe a large application, map it to multiple FPGAs and then deploy the application on a multi-FPGA platform. In this paper, we explore the feasibility of implementing large transformers using multiple FPGAs by developing a scalable multi-FPGA platform and some tools to map large applications to the platform. We validate our approach by designing an efficient multi-FPGA version of the I-BERT transformer and implement one encoder using six FPGAs as a working proof-of-concept to show that our platform and tools work. Based on our proof-of-concept prototype and the estimations of performance using the latest FPGAs compared to GPUs, we conclude that there can be a place for FPGAs in the world of large machine learning applications. We demonstrate a promising first step that shows that with the right infrastructure and tools it is reasonable to continue to explore the possible benefits of using FPGAs for applications such as LLMs.
Caffeinated FPGAs: FPGA Framework For Convolutional Neural Networks
Sep 30, 2016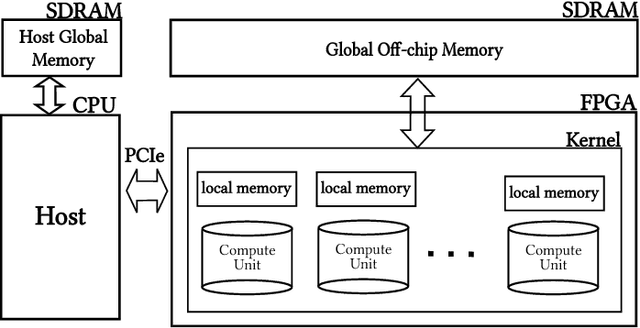
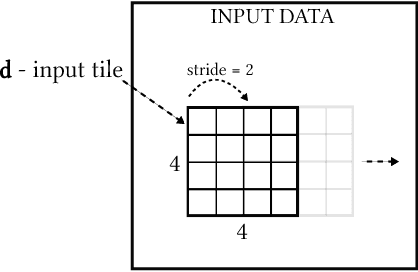

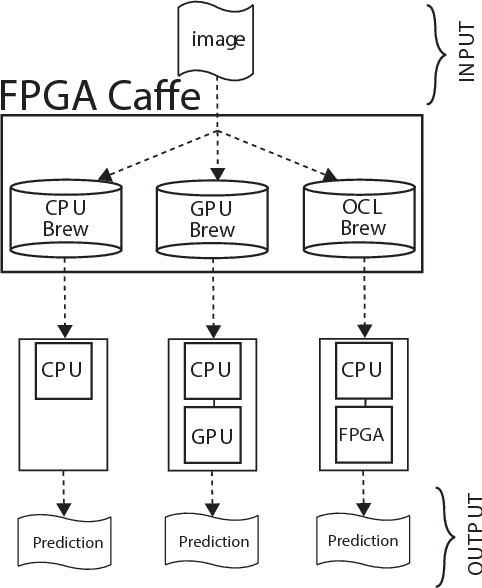
Convolutional Neural Networks (CNNs) have gained significant traction in the field of machine learning, particularly due to their high accuracy in visual recognition. Recent works have pushed the performance of GPU implementations of CNNs to significantly improve their classification and training times. With these improvements, many frameworks have become available for implementing CNNs on both CPUs and GPUs, with no support for FPGA implementations. In this work we present a modified version of the popular CNN framework Caffe, with FPGA support. This allows for classification using CNN models and specialized FPGA implementations with the flexibility of reprogramming the device when necessary, seamless memory transactions between host and device, simple-to-use test benches, and the ability to create pipelined layer implementations. To validate the framework, we use the Xilinx SDAccel environment to implement an FPGA-based Winograd convolution engine and show that the FPGA layer can be used alongside other layers running on a host processor to run several popular CNNs (AlexNet, GoogleNet, VGG A, Overfeat). The results show that our framework achieves 50 GFLOPS across 3x3 convolutions in the benchmarks. This is achieved within a practical framework, which will aid in future development of FPGA-based CNNs.