 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Layer-Wise Precision in Deep Neural Networks
Paper and Code
Jul 03, 2018

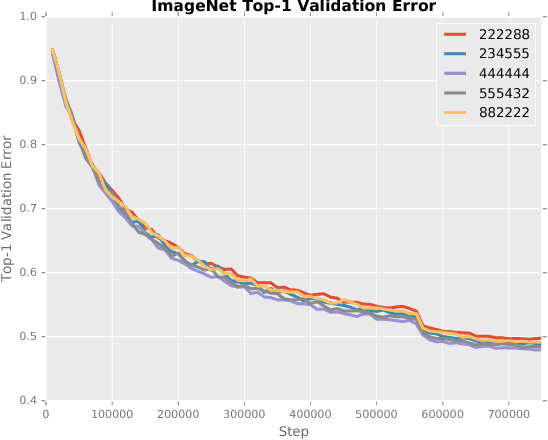

Low precision weights, activations, and gradients have been proposed as a way to improve the computational efficiency and memory footprint of deep neural networks. Recently, low precision networks have even shown to be more robust to adversarial attacks. However, typical implementations of low precision DNNs use uniform precision across all layers of the network. In this work, we explore whether a heterogeneous allocation of precision across a network leads to improved performance, and introduce a learning scheme where a DNN stochastically explores multiple precision configurations through learning. This permits a network to learn an optimal precision configuration. We show on convolutional neural networks trained on MNIST and ILSVRC12 that even though these nets learn a uniform or near-uniform allocation strategy respectively, stochastic precision leads to a favourable regularization effect improving generalization.