 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHand Pose Estimation through Semi-Supervised and Weakly-Supervised Learning
Sep 15, 2017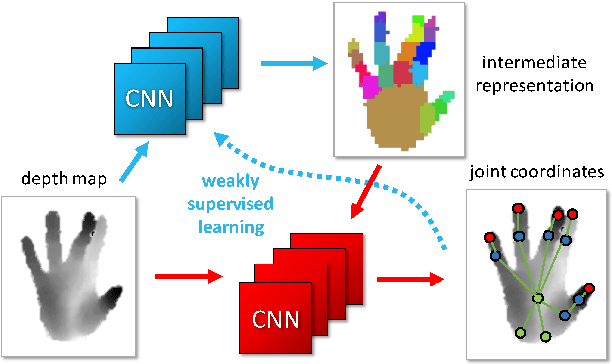
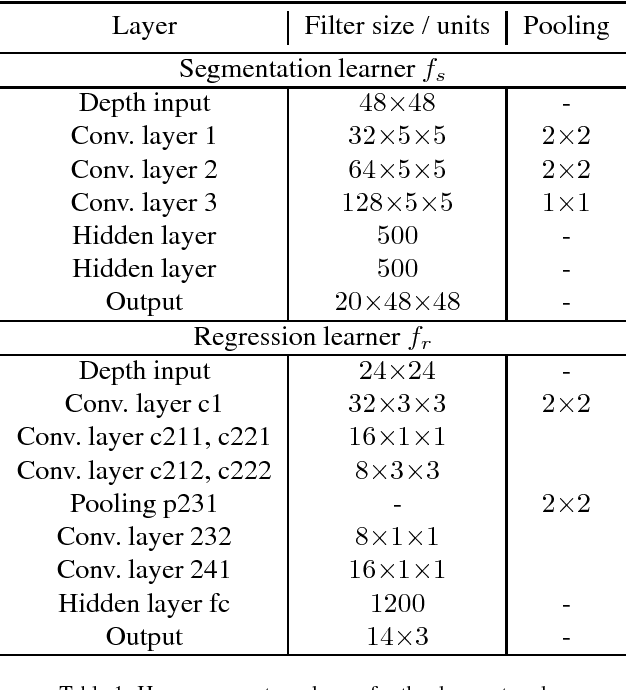
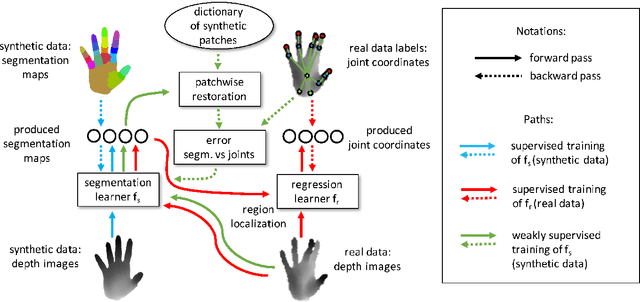

We propose a method for hand pose estimation based on a deep regressor trained on two different kinds of input. Raw depth data is fused with an intermediate representation in the form of a segmentation of the hand into parts. This intermediate representation contains important topological information and provides useful cues for reasoning about joint locations. The mapping from raw depth to segmentation maps is learned in a semi/weakly-supervised way from two different datasets: (i) a synthetic dataset created through a rendering pipeline including densely labeled ground truth (pixelwise segmentations); and (ii) a dataset with real images for which ground truth joint positions are available, but not dense segmentations. Loss for training on real images is generated from a patch-wise restoration process, which aligns tentative segmentation maps with a large dictionary of synthetic poses. The underlying premise is that the domain shift between synthetic and real data is smaller in the intermediate representation, where labels carry geometric and topological meaning, than in the raw input domain. Experiments on the NYU dataset show that the proposed training method decreases error on joints over direct regression of joints from depth data by 15.7%.
ModDrop: adaptive multi-modal gesture recognition
Jun 06, 2015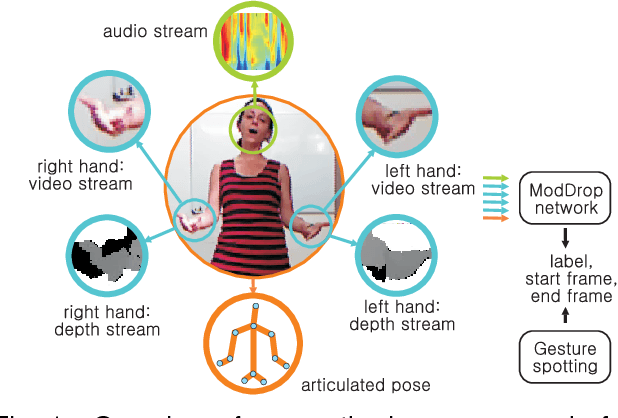
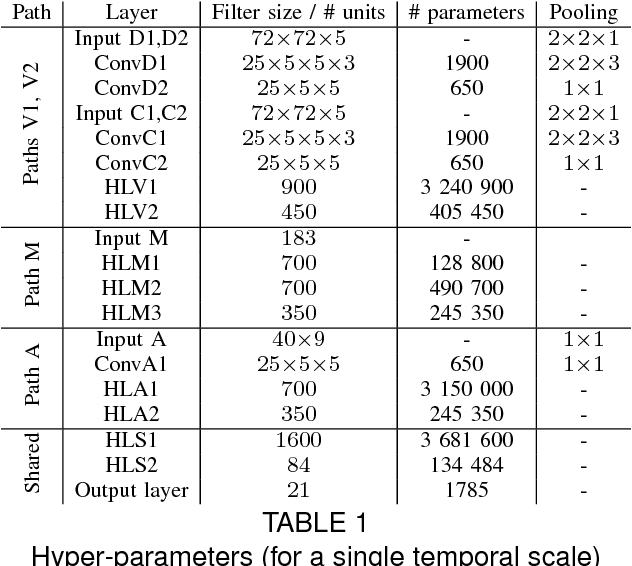
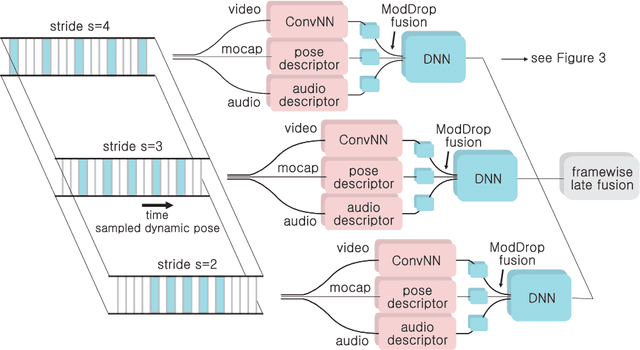
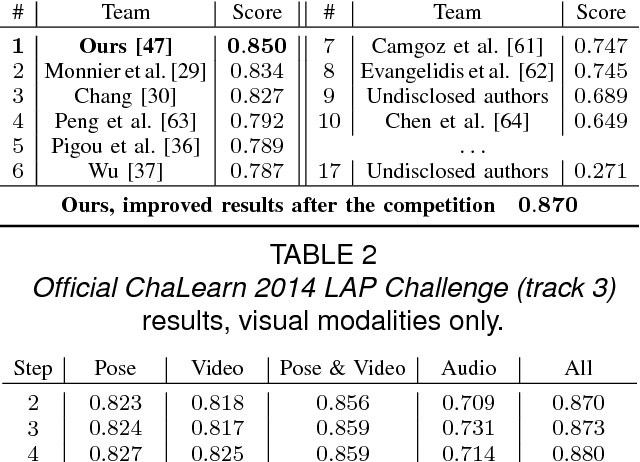
We present a method for gesture detection and localisation based on multi-scale and multi-modal deep learning. Each visual modality captures spatial information at a particular spatial scale (such as motion of the upper body or a hand), and the whole system operates at three temporal scales. Key to our technique is a training strategy which exploits: i) careful initialization of individual modalities; and ii) gradual fusion involving random dropping of separate channels (dubbed ModDrop) for learning cross-modality correlations while preserving uniqueness of each modality-specific representation. We present experiments on the ChaLearn 2014 Looking at People Challenge gesture recognition track, in which we placed first out of 17 teams. Fusing multiple modalities at several spatial and temporal scales leads to a significant increase in recognition rates, allowing the model to compensate for errors of the individual classifiers as well as noise in the separate channels. Futhermore, the proposed ModDrop training technique ensures robustness of the classifier to missing signals in one or several channels to produce meaningful predictions from any number of available modalities. In addition, we demonstrate the applicability of the proposed fusion scheme to modalities of arbitrary nature by experiments on the same dataset augmented with audio.