Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheano-MPI: a Theano-based Distributed Training Framework
Paper and Code
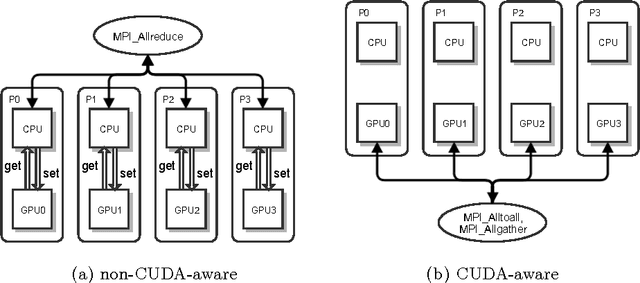
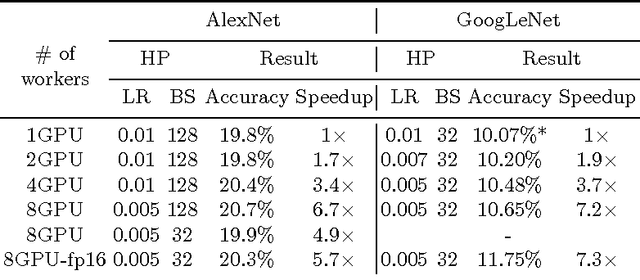
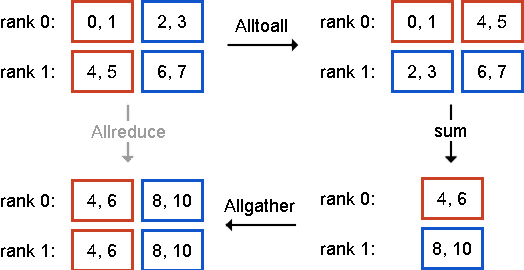
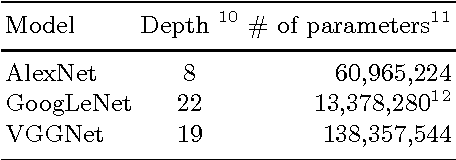
We develop a scalable and extendable training framework that can utilize GPUs across nodes in a cluster and accelerate the training of deep learning models based on data parallelism. Both synchronous and asynchronous training are implemented in our framework, where parameter exchange among GPUs is based on CUDA-aware MPI. In this report, we analyze the convergence and capability of the framework to reduce training time when scaling the synchronous training of AlexNet and GoogLeNet from 2 GPUs to 8 GPUs. In addition, we explore novel ways to reduce the communication overhead caused by exchanging parameters. Finally, we release the framework as open-source for further research on distributed deep learning
View paper on