 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounded Token Initialization for New Vocabulary in LMs for Generative Recommendation
Apr 02, 2026Language models (LMs) are increasingly extended with new learnable vocabulary tokens for domain-specific tasks, such as Semantic-ID tokens in generative recommendation. The standard practice initializes these new tokens as the mean of existing vocabulary embeddings, then relies on supervised fine-tuning to learn their representations. We present a systematic analysis of this strategy: through spectral and geometric diagnostics, we show that mean initialization collapses all new tokens into a degenerate subspace, erasing inter-token distinctions that subsequent fine-tuning struggles to fully recover. These findings suggest that \emph{token initialization} is a key bottleneck when extending LMs with new vocabularies. Motivated by this diagnosis, we propose the \emph{Grounded Token Initialization Hypothesis}: linguistically grounding novel tokens in the pretrained embedding space before fine-tuning better enables the model to leverage its general-purpose knowledge for novel-token domains. We operationalize this hypothesis as GTI (Grounded Token Initialization), a lightweight grounding stage that, prior to fine-tuning, maps new tokens to distinct, semantically meaningful locations in the pretrained embedding space using only paired linguistic supervision. Despite its simplicity, GTI outperforms both mean initialization and existing auxiliary-task adaptation methods in the majority of evaluation settings across multiple generative recommendation benchmarks, including industry-scale and public datasets. Further analyses show that grounded embeddings produce richer inter-token structure that persists through fine-tuning, corroborating the hypothesis that initialization quality is a key bottleneck in vocabulary extension.
Efficient AI in Practice: Training and Deployment of Efficient LLMs for Industry Applications
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable performance across a wide range of industrial applications, from search and recommendations to generative tasks. Although scaling laws indicate that larger models generally yield better generalization and performance, their substantial computational requirements often render them impractical for many real-world scenarios at scale. In this paper, we present methods and insights for training small language models (SLMs) that deliver high performance and efficiency in deployment. We focus on two key techniques: (1) knowledge distillation and (2) model compression via quantization and pruning. These approaches enable SLMs to retain much of the quality of their larger counterparts while significantly reducing training, serving costs, and latency. We detail the impact of these techniques on a variety of use cases at a large professional social network platform and share deployment lessons - including hardware optimization strategies that enhance speed and throughput for both predictive and reasoning-based applications.
Control LLM: Controlled Evolution for Intelligence Retention in LLM
Jan 19, 2025



Large Language Models (LLMs) demand significant computational resources, making it essential to enhance their capabilities without retraining from scratch. A key challenge in this domain is \textit{catastrophic forgetting} (CF), which hampers performance during Continuous Pre-training (CPT) and Continuous Supervised Fine-Tuning (CSFT). We propose \textbf{Control LLM}, a novel approach that leverages parallel pre-trained and expanded transformer blocks, aligning their hidden-states through interpolation strategies This method effectively preserves performance on existing tasks while seamlessly integrating new knowledge. Extensive experiments demonstrate the effectiveness of Control LLM in both CPT and CSFT. On Llama3.1-8B-Instruct, it achieves significant improvements in mathematical reasoning ($+14.4\%$ on Math-Hard) and coding performance ($+10\%$ on MBPP-PLUS). On Llama3.1-8B, it enhances multilingual capabilities ($+10.6\%$ on C-Eval, $+6.8\%$ on CMMLU, and $+30.2\%$ on CMMLU-0shot-CoT). It surpasses existing methods and achieves SOTA among open-source models tuned from the same base model, using substantially less data and compute. Crucially, these gains are realized while preserving strong original capabilities, with minimal degradation ($<4.3\% \text{on MMLU}$) compared to $>35\%$ in open-source Math and Coding models. This approach has been successfully deployed in LinkedIn's GenAI-powered job seeker and Ads unit products. To support further research, we release the training and evaluation code (\url{https://github.com/linkedin/ControlLLM}) along with models trained on public datasets (\url{ https://huggingface.co/ControlLLM}) to the community.
Deep Natural Language Processing for LinkedIn Search
Aug 16, 2021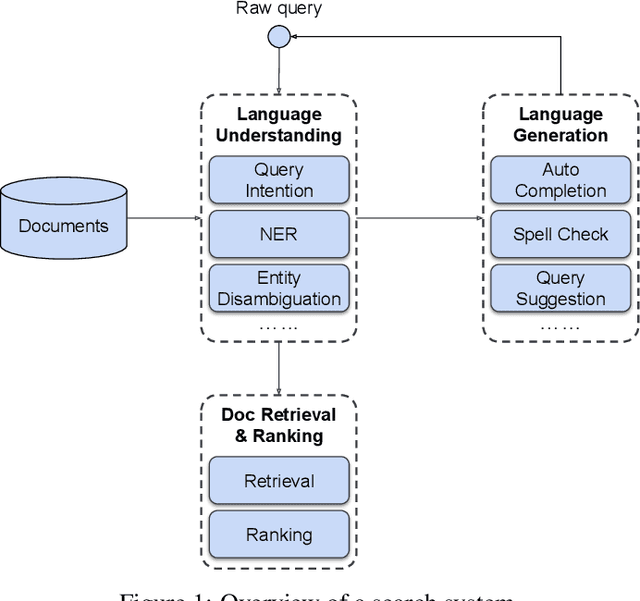

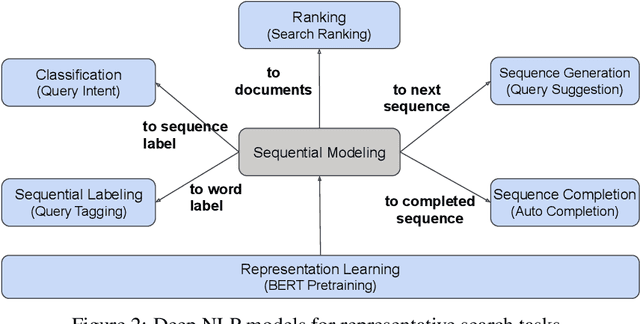

Many search systems work with large amounts of natural language data, e.g., search queries, user profiles, and documents. Building a successful search system requires a thorough understanding of textual data semantics, where deep learning based natural language processing techniques (deep NLP) can be of great help. In this paper, we introduce a comprehensive study for applying deep NLP techniques to five representative tasks in search systems: query intent prediction (classification), query tagging (sequential tagging), document ranking (ranking), query auto completion (language modeling), and query suggestion (sequence to sequence). We also introduce BERT pre-training as a sixth task that can be applied to many of the other tasks. Through the model design and experiments of the six tasks, readers can find answers to four important questions: (1). When is deep NLP helpful/not helpful in search systems? (2). How to address latency challenges? (3). How to ensure model robustness? This work builds on existing efforts of LinkedIn search, and is tested at scale on LinkedIn's commercial search engines. We believe our experiences can provide useful insights for the industry and research communities.
Deep Natural Language Processing for LinkedIn Search Systems
Jul 30, 2021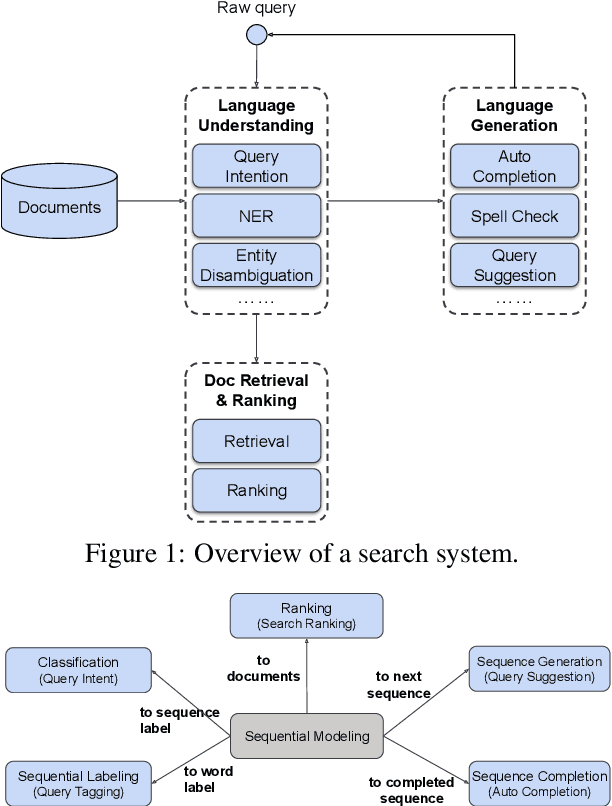
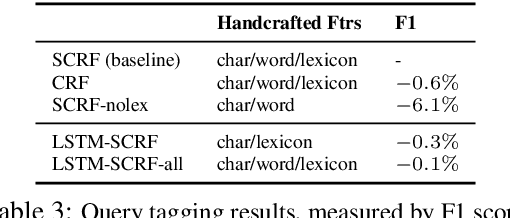
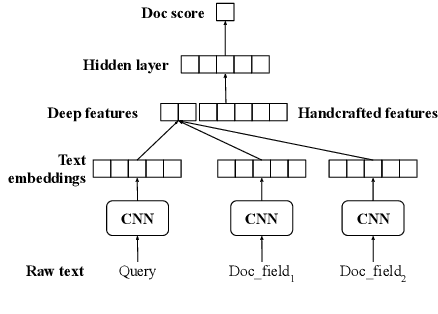
Many search systems work with large amounts of natural language data, e.g., search queries, user profiles and documents, where deep learning based natural language processing techniques (deep NLP) can be of great help. In this paper, we introduce a comprehensive study of applying deep NLP techniques to five representative tasks in search engines. Through the model design and experiments of the five tasks, readers can find answers to three important questions: (1) When is deep NLP helpful/not helpful in search systems? (2) How to address latency challenges? (3) How to ensure model robustness? This work builds on existing efforts of LinkedIn search, and is tested at scale on a commercial search engine. We believe our experiences can provide useful insights for the industry and research communities.