 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Cold-Start Gap: LLM-Powered Synthetic Data Generation for Natural Language Search at Airbnb
May 20, 2026Deploying natural language search systems presents a critical cold-start challenge: no real user queries to learn linguistic patterns, and no relevance labels to train ranking models. We present a framework for generating synthetic queries and labels using large language models (LLMs), powering model training and evaluation for Airbnb's natural language search. For query generation, we combine contrastive listing pairs from booking sessions with seed queries from user research to balance realism and diversity, enabling a cold-to-warm start transition as real user data becomes available. For label generation, we introduce contrastive generation that produces topicality labels by construction, and Virtual Judge (VJ) labeling for broader coverage. We compare our approach against a no-seed contrastive baseline and an InPars-style baseline. For query length, the InPars baseline produces verbose queries with KL divergence of 12.03 vs. real users; our seed-guided approach achieves 0.66, a 7.5x improvement. For attribute type distributions, our approach achieves the lowest KL divergence (0.04), outperforming even seed queries (0.09). Experiments show our approach produces harder evaluation examples than the no-seed baseline (79% vs. 97% pairwise accuracy), providing discriminative signal for model improvement. We deploy production pipelines generating synthetic examples daily for embedding-based retrieval and ranking evaluation.
High Precision Audience Expansion via Extreme Classification in a Two-Sided Marketplace
Feb 16, 2026Airbnb search must balance a worldwide, highly varied supply of homes with guests whose location, amenity, style, and price expectations differ widely. Meeting those expectations hinges on an efficient retrieval stage that surfaces only the listings a guest might realistically book, before resource intensive ranking models are applied to determine the best results. Unlike many recommendation engines, our system faces a distinctive challenge, location retrieval, that sits upstream of ranking and determines which geographic areas are queried in order to filter inventory to a candidate set. The preexisting approach employs a deep bayesian bandit based system to predict a rectangular retrieval bounds area that can be used for filtering. The purpose of this paper is to demonstrate the methodology, challenges, and impact of rearchitecting search to retrieve from the subset of most bookable high precision rectangular map cells defined by dividing the world into 25M uniform cells.
Applying Embedding-Based Retrieval to Airbnb Search
Jan 11, 2026The goal of Airbnb search is to match guests with the ideal accommodation that fits their travel needs. This is a challenging problem, as popular search locations can have around a hundred thousand available homes, and guests themselves have a wide variety of preferences. Furthermore, the launch of new product features, such as \textit{flexible date search,} significantly increased the number of eligible homes per search query. As such, there is a need for a sophisticated retrieval system which can provide high-quality candidates with low latency in a way that integrates with the overall ranking stack. This paper details our journey to build an efficient and high-quality retrieval system for Airbnb search. We describe the key unique challenges we encountered when implementing an Embedding-Based Retrieval (EBR) system for a two sided marketplace like Airbnb -- such as the dynamic nature of the inventory, a lengthy user funnel with multiple stages, and a variety of product surfaces. We cover unique insights when modeling the retrieval problem, how to build robust evaluation systems, and design choices for online serving. The EBR system was launched to production and powers several use-cases such as regular search, flexible date and promotional emails for marketing campaigns. The system demonstrated statistically-significant improvements in key metrics, such as booking conversion, via A/B testing.
Harnessing the Power of Interleaving and Counterfactual Evaluation for Airbnb Search Ranking
Aug 01, 2025Evaluation plays a crucial role in the development of ranking algorithms on search and recommender systems. It enables online platforms to create user-friendly features that drive commercial success in a steady and effective manner. The online environment is particularly conducive to applying causal inference techniques, such as randomized controlled experiments (known as A/B test), which are often more challenging to implement in fields like medicine and public policy. However, businesses face unique challenges when it comes to effective A/B test. Specifically, achieving sufficient statistical power for conversion-based metrics can be time-consuming, especially for significant purchases like booking accommodations. While offline evaluations are quicker and more cost-effective, they often lack accuracy and are inadequate for selecting candidates for A/B test. To address these challenges, we developed interleaving and counterfactual evaluation methods to facilitate rapid online assessments for identifying the most promising candidates for A/B tests. Our approach not only increased the sensitivity of experiments by a factor of up to 100 (depending on the approach and metrics) compared to traditional A/B testing but also streamlined the experimental process. The practical insights gained from usage in production can also benefit organizations with similar interests.
* 10 pages
Beyond Pairwise Learning-To-Rank At Airbnb
May 14, 2025There are three fundamental asks from a ranking algorithm: it should scale to handle a large number of items, sort items accurately by their utility, and impose a total order on the items for logical consistency. But here's the catch-no algorithm can achieve all three at the same time. We call this limitation the SAT theorem for ranking algorithms. Given the dilemma, how can we design a practical system that meets user needs? Our current work at Airbnb provides an answer, with a working solution deployed at scale. We start with pairwise learning-to-rank (LTR) models-the bedrock of search ranking tech stacks today. They scale linearly with the number of items ranked and perform strongly on metrics like NDCG by learning from pairwise comparisons. They are at a sweet spot of performance vs. cost, making them an ideal choice for several industrial applications. However, they have a drawback-by ignoring interactions between items, they compromise on accuracy. To improve accuracy, we create a "true" pairwise LTR model-one that captures interactions between items during pairwise comparisons. But accuracy comes at the expense of scalability and total order, and we discuss strategies to counter these challenges. For greater accuracy, we take each item in the search result, and compare it against the rest of the items along two dimensions: (1) Superiority: How strongly do searchers prefer the given item over the remaining ones? (2) Similarity: How similar is the given item to all the other items? This forms the basis of our "all-pairwise" LTR framework, which factors in interactions across all items at once. Looking at items on the search result page all together-superiority and similarity combined-gives us a deeper understanding of what searchers truly want. We quantify the resulting improvements in searcher experience through offline and online experiments at Airbnb.
Predicting Potential Customer Support Needs and Optimizing Search Ranking in a Two-Sided Marketplace
Mar 21, 2025Airbnb is an online marketplace that connects hosts and guests to unique stays and experiences. When guests stay at homes booked on Airbnb, there are a small fraction of stays that lead to support needed from Airbnb's Customer Support (CS), which may cause inconvenience to guests and hosts and require Airbnb resources to resolve. In this work, we show that instances where CS support is needed may be predicted based on hosts and guests behavior. We build a model to predict the likelihood of CS support needs for each match of guest and host. The model score is incorporated into Airbnb's search ranking algorithm as one of the many factors. The change promotes more reliable matches in search results and significantly reduces bookings that require CS support.
Transforming Location Retrieval at Airbnb: A Journey from Heuristics to Reinforcement Learning
Aug 23, 2024



The Airbnb search system grapples with many unique challenges as it continues to evolve. We oversee a marketplace that is nuanced by geography, diversity of homes, and guests with a variety of preferences. Crafting an efficient search system that can accommodate diverse guest needs, while showcasing relevant homes lies at the heart of Airbnb's success. Airbnb search has many challenges that parallel other recommendation and search systems but it has a unique information retrieval problem, upstream of ranking, called location retrieval. It requires defining a topological map area that is relevant to the searched query for homes listing retrieval. The purpose of this paper is to demonstrate the methodology, challenges, and impact of building a machine learning based location retrieval product from the ground up. Despite the lack of suitable, prevalent machine learning based approaches, we tackle cold start, generalization, differentiation and algorithmic bias. We detail the efficacy of heuristics, statistics, machine learning, and reinforcement learning approaches to solve these challenges, particularly for systems that are often unexplored by current literature.
Multi-objective Learning to Rank by Model Distillation
Jul 09, 2024



In online marketplaces, search ranking's objective is not only to purchase or conversion (primary objective), but to also the purchase outcomes(secondary objectives), e.g. order cancellation(or return), review rating, customer service inquiries, platform long term growth. Multi-objective learning to rank has been widely studied to balance primary and secondary objectives. But traditional approaches in industry face some challenges including expensive parameter tuning leads to sub-optimal solution, suffering from imbalanced data sparsity issue, and being not compatible with ad-hoc objective. In this paper, we propose a distillation-based ranking solution for multi-objective ranking, which optimizes the end-to-end ranking system at Airbnb across multiple ranking models on different objectives along with various considerations to optimize training and serving efficiency to meet industry standards. We found it performs much better than traditional approaches, it doesn't only significantly increases primary objective by a large margin but also meet secondary objectives constraints and improve model stability. We also demonstrated the proposed system could be further simplified by model self-distillation. Besides this, we did additional simulations to show that this approach could also help us efficiently inject ad-hoc non-differentiable business objective into the ranking system while enabling us to balance our optimization objectives.
Learning to Rank for Maps at Airbnb
Jun 25, 2024



As a two-sided marketplace, Airbnb brings together hosts who own listings for rent with prospective guests from around the globe. Results from a guest's search for listings are displayed primarily through two interfaces: (1) as a list of rectangular cards that contain on them the listing image, price, rating, and other details, referred to as list-results (2) as oval pins on a map showing the listing price, called map-results. Both these interfaces, since their inception, have used the same ranking algorithm that orders listings by their booking probabilities and selects the top listings for display. But some of the basic assumptions underlying ranking, built for a world where search results are presented as lists, simply break down for maps. This paper describes how we rebuilt ranking for maps by revising the mathematical foundations of how users interact with search results. Our iterative and experiment-driven approach led us through a path full of twists and turns, ending in a unified theory for the two interfaces. Our journey shows how assumptions taken for granted when designing machine learning algorithms may not apply equally across all user interfaces, and how they can be adapted. The net impact was one of the largest improvements in user experience for Airbnb which we discuss as a series of experimental validations.
Optimizing Airbnb Search Journey with Multi-task Learning
May 28, 2023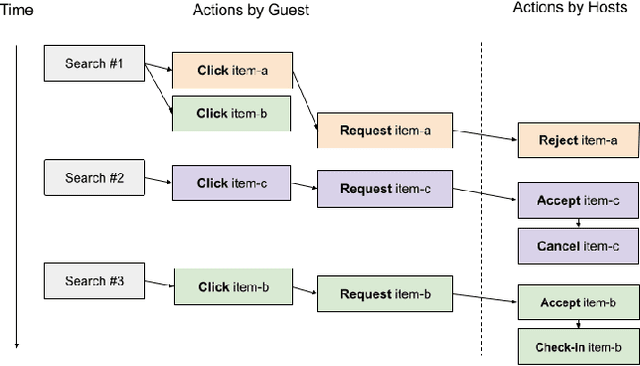
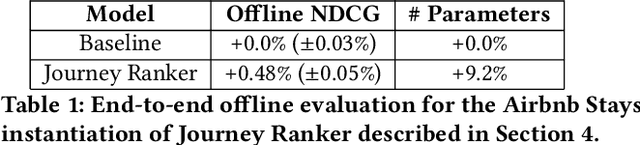
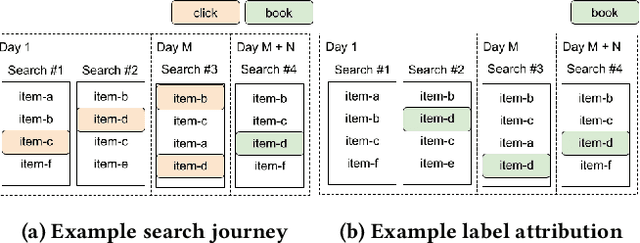
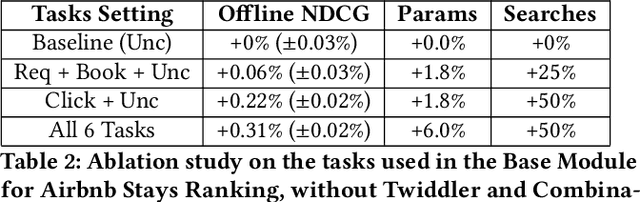
At Airbnb, an online marketplace for stays and experiences, guests often spend weeks exploring and comparing multiple items before making a final reservation request. Each reservation request may then potentially be rejected or cancelled by the host prior to check-in. The long and exploratory nature of the search journey, as well as the need to balance both guest and host preferences, present unique challenges for Airbnb search ranking. In this paper, we present Journey Ranker, a new multi-task deep learning model architecture that addresses these challenges. Journey Ranker leverages intermediate guest actions as milestones, both positive and negative, to better progress the guest towards a successful booking. It also uses contextual information such as guest state and search query to balance guest and host preferences. Its modular and extensible design, consisting of four modules with clear separation of concerns, allows for easy application to use cases beyond the Airbnb search ranking context. We conducted offline and online testing of the Journey Ranker and successfully deployed it in production to four different Airbnb products with significant business metrics improvements.