 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge360Brew: A Decoder-only Foundation Model for Personalized Ranking and Recommendation
Jan 27, 2025



Ranking and recommendation systems are the foundation for numerous online experiences, ranging from search results to personalized content delivery. These systems have evolved into complex, multilayered architectures that leverage vast datasets and often incorporate thousands of predictive models. The maintenance and enhancement of these models is a labor intensive process that requires extensive feature engineering. This approach not only exacerbates technical debt but also hampers innovation in extending these systems to emerging problem domains. In this report, we present our research to address these challenges by utilizing a large foundation model with a textual interface for ranking and recommendation tasks. We illustrate several key advantages of our approach: (1) a single model can manage multiple predictive tasks involved in ranking and recommendation, (2) decoder models with textual interface due to their comprehension of reasoning capabilities, can generalize to new recommendation surfaces and out-of-domain problems, and (3) by employing natural language interfaces for task definitions and verbalizing member behaviors and their social connections, we eliminate the need for feature engineering and the maintenance of complex directed acyclic graphs of model dependencies. We introduce our research pre-production model, 360Brew V1.0, a 150B parameter, decoder-only model that has been trained and fine-tuned on LinkedIn's data and tasks. This model is capable of solving over 30 predictive tasks across various segments of the LinkedIn platform, achieving performance levels comparable to or exceeding those of current production systems based on offline metrics, without task-specific fine-tuning. Notably, each of these tasks is conventionally addressed by dedicated models that have been developed and maintained over multiple years by teams of a similar or larger size than our own.
Control LLM: Controlled Evolution for Intelligence Retention in LLM
Jan 19, 2025



Large Language Models (LLMs) demand significant computational resources, making it essential to enhance their capabilities without retraining from scratch. A key challenge in this domain is \textit{catastrophic forgetting} (CF), which hampers performance during Continuous Pre-training (CPT) and Continuous Supervised Fine-Tuning (CSFT). We propose \textbf{Control LLM}, a novel approach that leverages parallel pre-trained and expanded transformer blocks, aligning their hidden-states through interpolation strategies This method effectively preserves performance on existing tasks while seamlessly integrating new knowledge. Extensive experiments demonstrate the effectiveness of Control LLM in both CPT and CSFT. On Llama3.1-8B-Instruct, it achieves significant improvements in mathematical reasoning ($+14.4\%$ on Math-Hard) and coding performance ($+10\%$ on MBPP-PLUS). On Llama3.1-8B, it enhances multilingual capabilities ($+10.6\%$ on C-Eval, $+6.8\%$ on CMMLU, and $+30.2\%$ on CMMLU-0shot-CoT). It surpasses existing methods and achieves SOTA among open-source models tuned from the same base model, using substantially less data and compute. Crucially, these gains are realized while preserving strong original capabilities, with minimal degradation ($<4.3\% \text{on MMLU}$) compared to $>35\%$ in open-source Math and Coding models. This approach has been successfully deployed in LinkedIn's GenAI-powered job seeker and Ads unit products. To support further research, we release the training and evaluation code (\url{https://github.com/linkedin/ControlLLM}) along with models trained on public datasets (\url{ https://huggingface.co/ControlLLM}) to the community.
CUR from a Sparse Optimization Viewpoint
Nov 01, 2010
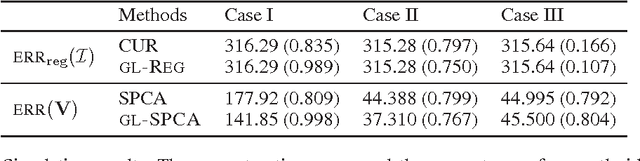

The CUR decomposition provides an approximation of a matrix $X$ that has low reconstruction error and that is sparse in the sense that the resulting approximation lies in the span of only a few columns of $X$. In this regard, it appears to be similar to many sparse PCA methods. However, CUR takes a randomized algorithmic approach, whereas most sparse PCA methods are framed as convex optimization problems. In this paper, we try to understand CUR from a sparse optimization viewpoint. We show that CUR is implicitly optimizing a sparse regression objective and, furthermore, cannot be directly cast as a sparse PCA method. We also observe that the sparsity attained by CUR possesses an interesting structure, which leads us to formulate a sparse PCA method that achieves a CUR-like sparsity.