 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAEB: Massive Audio Embedding Benchmark
Feb 17, 2026We introduce the Massive Audio Embedding Benchmark (MAEB), a large-scale benchmark covering 30 tasks across speech, music, environmental sounds, and cross-modal audio-text reasoning in 100+ languages. We evaluate 50+ models and find that no single model dominates across all tasks: contrastive audio-text models excel at environmental sound classification (e.g., ESC50) but score near random on multilingual speech tasks (e.g., SIB-FLEURS), while speech-pretrained models show the opposite pattern. Clustering remains challenging for all models, with even the best-performing model achieving only modest results. We observe that models excelling on acoustic understanding often perform poorly on linguistic tasks, and vice versa. We also show that the performance of audio encoders on MAEB correlates highly with their performance when used in audio large language models. MAEB is derived from MAEB+, a collection of 98 tasks. MAEB is designed to maintain task diversity while reducing evaluation cost, and it integrates into the MTEB ecosystem for unified evaluation across text, image, and audio modalities. We release MAEB and all 98 tasks along with code and a leaderboard at https://github.com/embeddings-benchmark/mteb.
DSFormer: Effective Compression of Text-Transformers by Dense-Sparse Weight Factorization
Dec 20, 2023With the tremendous success of large transformer models in natural language understanding, down-sizing them for cost-effective deployments has become critical. Recent studies have explored the low-rank weight factorization techniques which are efficient to train, and apply out-of-the-box to any transformer architecture. Unfortunately, the low-rank assumption tends to be over-restrictive and hinders the expressiveness of the compressed model. This paper proposes, DSFormer, a simple alternative factorization scheme which expresses a target weight matrix as the product of a small dense and a semi-structured sparse matrix. The resulting approximation is more faithful to the weight distribution in transformers and therefore achieves a stronger efficiency-accuracy trade-off. Another concern with existing factorizers is their dependence on a task-unaware initialization step which degrades the accuracy of the resulting model. DSFormer addresses this issue through a novel Straight-Through Factorizer (STF) algorithm that jointly learns all the weight factorizations to directly maximize the final task accuracy. Extensive experiments on multiple natural language understanding benchmarks demonstrate that DSFormer obtains up to 40% better compression than the state-of-the-art low-rank factorizers, leading semi-structured sparsity baselines and popular knowledge distillation approaches. Our approach is also orthogonal to mainstream compressors and offers up to 50% additional compression when added to popular distilled, layer-shared and quantized transformers. We empirically evaluate the benefits of STF over conventional optimization practices.
CapsFlow: Optical Flow Estimation with Capsule Networks
Apr 01, 2023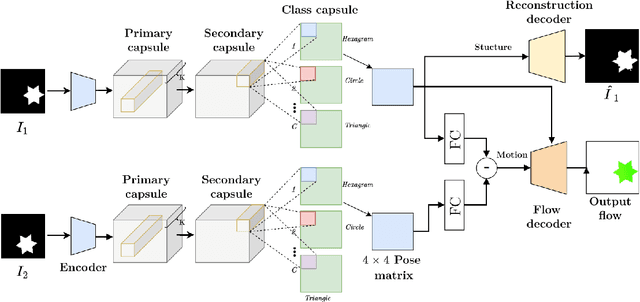



We present a framework to use recently introduced Capsule Networks for solving the problem of Optical Flow, one of the fundamental computer vision tasks. Most of the existing state of the art deep architectures either uses a correlation oepration to match features from them. While correlation layer is sensitive to the choice of hyperparameters and does not put a prior on the underlying structure of the object, spatio temporal features will be limited by the network's receptive field. Also, we as humans look at moving objects as whole, something which cannot be encoded by correlation or spatio temporal features. Capsules, on the other hand, are specialized to model seperate entities and their pose as a continuous matrix. Thus, we show that a simpler linear operation over poses of the objects detected by the capsules in enough to model flow. We show reslts on a small toy dataset where we outperform FlowNetC and PWC-Net models.