 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Thermal Modality to Enhance Reconstruction in Low-Light Conditions
Mar 21, 2024



Neural Radiance Fields (NeRF) accomplishes photo-realistic novel view synthesis by learning the implicit volumetric representation of a scene from multi-view images, which faithfully convey the colorimetric information. However, sensor noises will contaminate low-value pixel signals, and the lossy camera image signal processor will further remove near-zero intensities in extremely dark situations, deteriorating the synthesis performance. Existing approaches reconstruct low-light scenes from raw images but struggle to recover texture and boundary details in dark regions. Additionally, they are unsuitable for high-speed models relying on explicit representations. To address these issues, we present Thermal-NeRF, which takes thermal and visible raw images as inputs, considering the thermal camera is robust to the illumination variation and raw images preserve any possible clues in the dark, to accomplish visible and thermal view synthesis simultaneously. Also, the first multi-view thermal and visible dataset (MVTV) is established to support the research on multimodal NeRF. Thermal-NeRF achieves the best trade-off between detail preservation and noise smoothing and provides better synthesis performance than previous work. Finally, we demonstrate that both modalities are beneficial to each other in 3D reconstruction.
CapsFlow: Optical Flow Estimation with Capsule Networks
Apr 01, 2023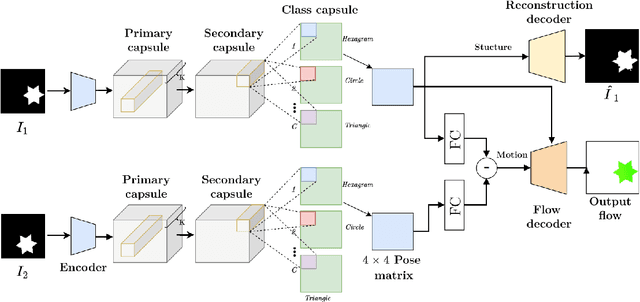



We present a framework to use recently introduced Capsule Networks for solving the problem of Optical Flow, one of the fundamental computer vision tasks. Most of the existing state of the art deep architectures either uses a correlation oepration to match features from them. While correlation layer is sensitive to the choice of hyperparameters and does not put a prior on the underlying structure of the object, spatio temporal features will be limited by the network's receptive field. Also, we as humans look at moving objects as whole, something which cannot be encoded by correlation or spatio temporal features. Capsules, on the other hand, are specialized to model seperate entities and their pose as a continuous matrix. Thus, we show that a simpler linear operation over poses of the objects detected by the capsules in enough to model flow. We show reslts on a small toy dataset where we outperform FlowNetC and PWC-Net models.