 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapsFlow: Optical Flow Estimation with Capsule Networks
Paper and Code
Apr 01, 2023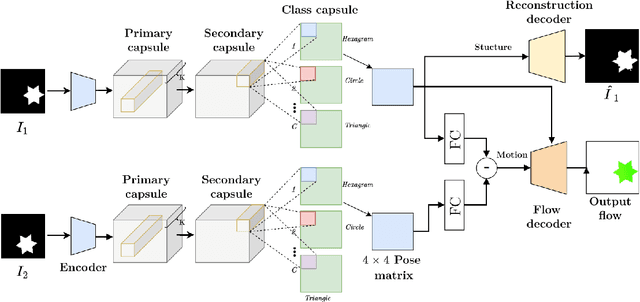



We present a framework to use recently introduced Capsule Networks for solving the problem of Optical Flow, one of the fundamental computer vision tasks. Most of the existing state of the art deep architectures either uses a correlation oepration to match features from them. While correlation layer is sensitive to the choice of hyperparameters and does not put a prior on the underlying structure of the object, spatio temporal features will be limited by the network's receptive field. Also, we as humans look at moving objects as whole, something which cannot be encoded by correlation or spatio temporal features. Capsules, on the other hand, are specialized to model seperate entities and their pose as a continuous matrix. Thus, we show that a simpler linear operation over poses of the objects detected by the capsules in enough to model flow. We show reslts on a small toy dataset where we outperform FlowNetC and PWC-Net models.