 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElimiNet: A Model for Eliminating Options for Reading Comprehension with Multiple Choice Questions
Paper and Code

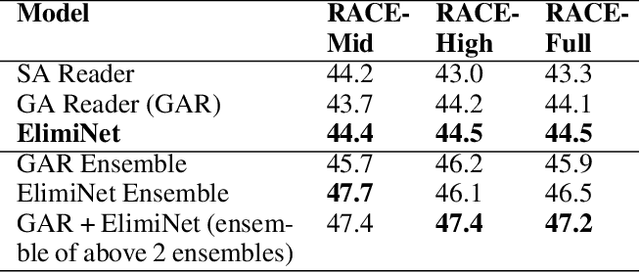
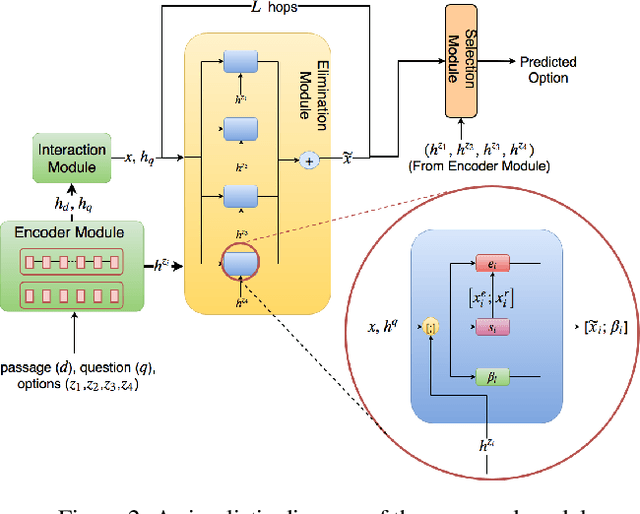
The task of Reading Comprehension with Multiple Choice Questions, requires a human (or machine) to read a given passage, question pair and select one of the n given options. The current state of the art model for this task first computes a question-aware representation for the passage and then selects the option which has the maximum similarity with this representation. However, when humans perform this task they do not just focus on option selection but use a combination of elimination and selection. Specifically, a human would first try to eliminate the most irrelevant option and then read the passage again in the light of this new information (and perhaps ignore portions corresponding to the eliminated option). This process could be repeated multiple times till the reader is finally ready to select the correct option. We propose ElimiNet, a neural network-based model which tries to mimic this process. Specifically, it has gates which decide whether an option can be eliminated given the passage, question pair and if so it tries to make the passage representation orthogonal to this eliminated option (akin to ignoring portions of the passage corresponding to the eliminated option). The model makes multiple rounds of partial elimination to refine the passage representation and finally uses a selection module to pick the best option. We evaluate our model on the recently released large scale RACE dataset and show that it outperforms the current state of the art model on 7 out of the $13$ question types in this dataset. Further, we show that taking an ensemble of our elimination-selection based method with a selection based method gives us an improvement of 3.1% over the best-reported performance on this dataset.