 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTapeAgents: a Holistic Framework for Agent Development and Optimization
Dec 11, 2024



We present TapeAgents, an agent framework built around a granular, structured log tape of the agent session that also plays the role of the session's resumable state. In TapeAgents we leverage tapes to facilitate all stages of the LLM Agent development lifecycle. The agent reasons by processing the tape and the LLM output to produce new thought and action steps and append them to the tape. The environment then reacts to the agent's actions by likewise appending observation steps to the tape. By virtue of this tape-centred design, TapeAgents can provide AI practitioners with holistic end-to-end support. At the development stage, tapes facilitate session persistence, agent auditing, and step-by-step debugging. Post-deployment, one can reuse tapes for evaluation, fine-tuning, and prompt-tuning; crucially, one can adapt tapes from other agents or use revised historical tapes. In this report, we explain the TapeAgents design in detail. We demonstrate possible applications of TapeAgents with several concrete examples of building monolithic agents and multi-agent teams, of optimizing agent prompts and finetuning the agent's LLM. We present tooling prototypes and report a case study where we use TapeAgents to finetune a Llama-3.1-8B form-filling assistant to perform as well as GPT-4o while being orders of magnitude cheaper. Lastly, our comparative analysis shows that TapeAgents's advantages over prior frameworks stem from our novel design of the LLM agent as a resumable, modular state machine with a structured configuration, that generates granular, structured logs and that can transform these logs into training text -- a unique combination of features absent in previous work.
Exploring Zero and Few-shot Techniques for Intent Classification
May 11, 2023
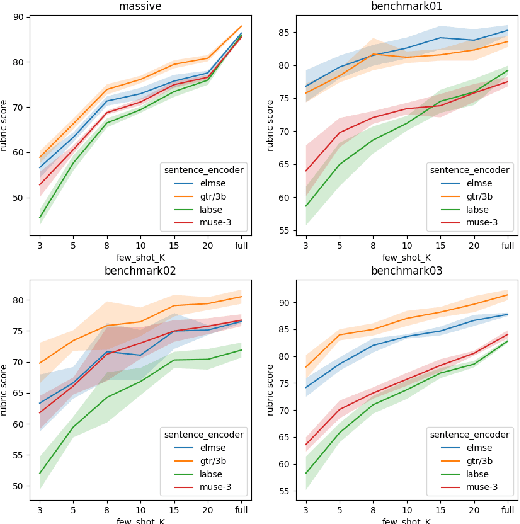
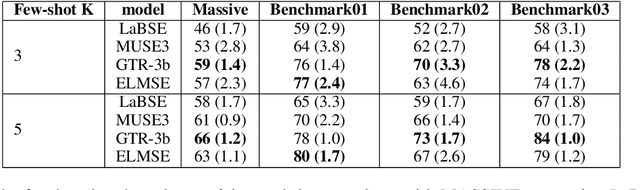
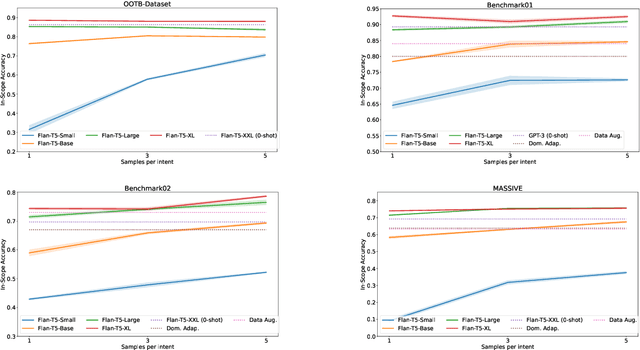
Conversational NLU providers often need to scale to thousands of intent-classification models where new customers often face the cold-start problem. Scaling to so many customers puts a constraint on storage space as well. In this paper, we explore four different zero and few-shot intent classification approaches with this low-resource constraint: 1) domain adaptation, 2) data augmentation, 3) zero-shot intent classification using descriptions large language models (LLMs), and 4) parameter-efficient fine-tuning of instruction-finetuned language models. Our results show that all these approaches are effective to different degrees in low-resource settings. Parameter-efficient fine-tuning using T-few recipe (Liu et al., 2022) on Flan-T5 (Chang et al., 2022) yields the best performance even with just one sample per intent. We also show that the zero-shot method of prompting LLMs using intent descriptions
Automated Utterance Generation
Apr 08, 2020



Conversational AI assistants are becoming popular and question-answering is an important part of any conversational assistant. Using relevant utterances as features in question-answering has shown to improve both the precision and recall for retrieving the right answer by a conversational assistant. Hence, utterance generation has become an important problem with the goal of generating relevant utterances (sentences or phrases) from a knowledge base article that consists of a title and a description. However, generating good utterances usually requires a lot of manual effort, creating the need for an automated utterance generation. In this paper, we propose an utterance generation system which 1) uses extractive summarization to extract important sentences from the description, 2) uses multiple paraphrasing techniques to generate a diverse set of paraphrases of the title and summary sentences, and 3) selects good candidate paraphrases with the help of a novel candidate selection algorithm.
Frustratingly Poor Performance of Reading Comprehension Models on Non-adversarial Examples
Apr 04, 2019
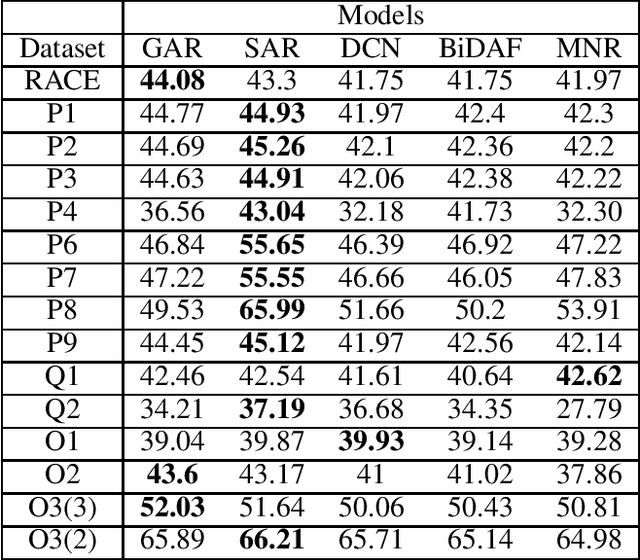

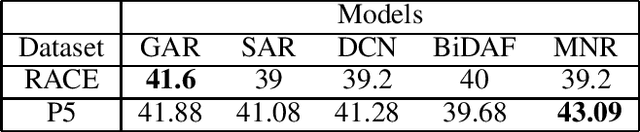
When humans learn to perform a difficult task (say, reading comprehension (RC) over longer passages), it is typically the case that their performance improves significantly on an easier version of this task (say, RC over shorter passages). Ideally, we would want an intelligent agent to also exhibit such a behavior. However, on experimenting with state of the art RC models using the standard RACE dataset, we observe that this is not true. Specifically, we see counter-intuitive results wherein even when we show frustratingly easy examples to the model at test time, there is hardly any improvement in its performance. We refer to this as non-adversarial evaluation as opposed to adversarial evaluation. Such non-adversarial examples allow us to assess the utility of specialized neural components. For example, we show that even for easy examples where the answer is clearly embedded in the passage, the neural components designed for paying attention to relevant portions of the passage fail to serve their intended purpose. We believe that the non-adversarial dataset created as a part of this work would complement the research on adversarial evaluation and give a more realistic assessment of the ability of RC models. All the datasets and codes developed as a part of this work will be made publicly available.
ElimiNet: A Model for Eliminating Options for Reading Comprehension with Multiple Choice Questions
Apr 04, 2019
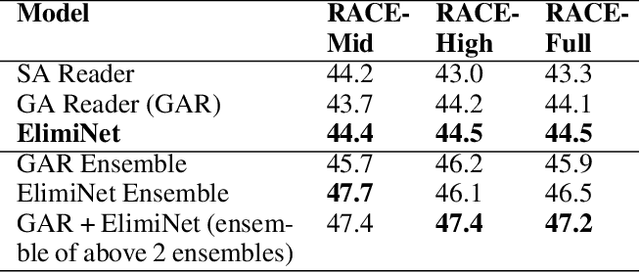
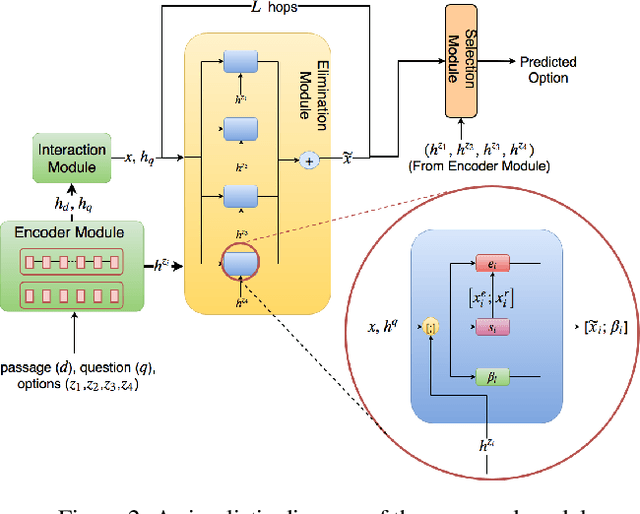
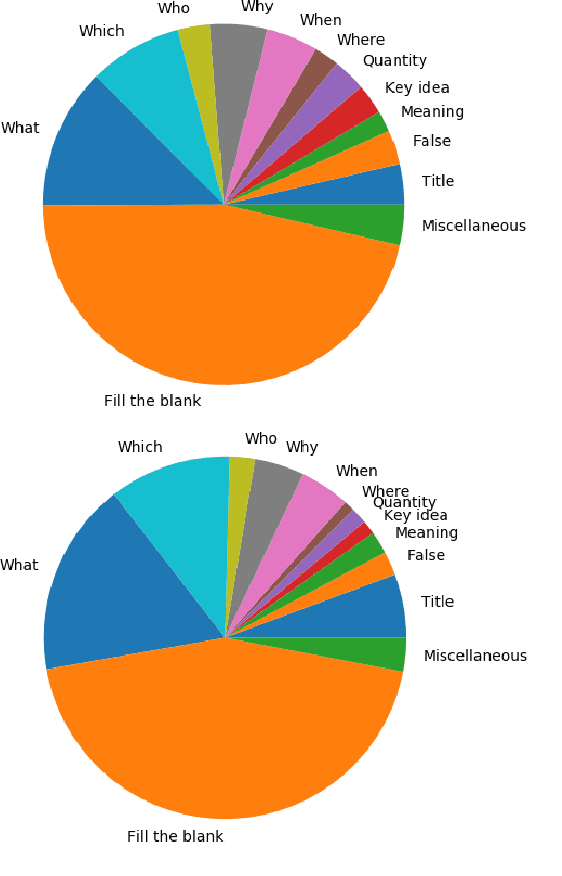
The task of Reading Comprehension with Multiple Choice Questions, requires a human (or machine) to read a given passage, question pair and select one of the n given options. The current state of the art model for this task first computes a question-aware representation for the passage and then selects the option which has the maximum similarity with this representation. However, when humans perform this task they do not just focus on option selection but use a combination of elimination and selection. Specifically, a human would first try to eliminate the most irrelevant option and then read the passage again in the light of this new information (and perhaps ignore portions corresponding to the eliminated option). This process could be repeated multiple times till the reader is finally ready to select the correct option. We propose ElimiNet, a neural network-based model which tries to mimic this process. Specifically, it has gates which decide whether an option can be eliminated given the passage, question pair and if so it tries to make the passage representation orthogonal to this eliminated option (akin to ignoring portions of the passage corresponding to the eliminated option). The model makes multiple rounds of partial elimination to refine the passage representation and finally uses a selection module to pick the best option. We evaluate our model on the recently released large scale RACE dataset and show that it outperforms the current state of the art model on 7 out of the $13$ question types in this dataset. Further, we show that taking an ensemble of our elimination-selection based method with a selection based method gives us an improvement of 3.1% over the best-reported performance on this dataset.
* IJCAI-18