 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrustratingly Poor Performance of Reading Comprehension Models on Non-adversarial Examples
Paper and Code
Apr 04, 2019
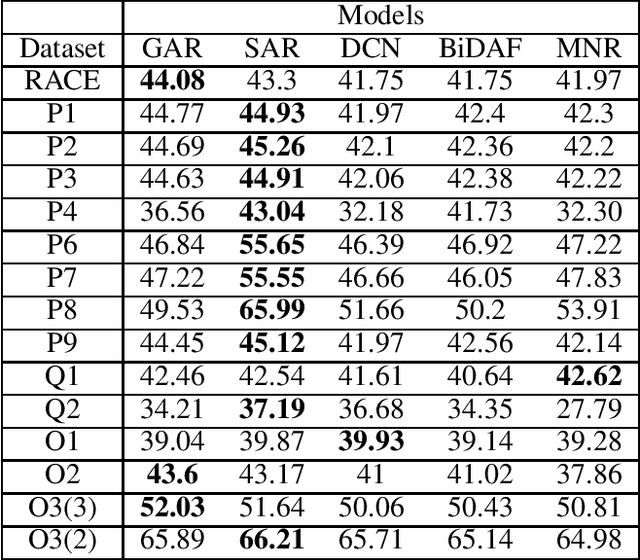

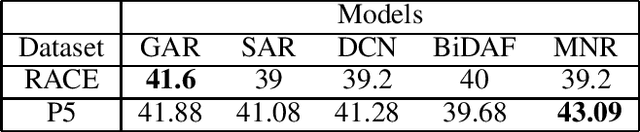
When humans learn to perform a difficult task (say, reading comprehension (RC) over longer passages), it is typically the case that their performance improves significantly on an easier version of this task (say, RC over shorter passages). Ideally, we would want an intelligent agent to also exhibit such a behavior. However, on experimenting with state of the art RC models using the standard RACE dataset, we observe that this is not true. Specifically, we see counter-intuitive results wherein even when we show frustratingly easy examples to the model at test time, there is hardly any improvement in its performance. We refer to this as non-adversarial evaluation as opposed to adversarial evaluation. Such non-adversarial examples allow us to assess the utility of specialized neural components. For example, we show that even for easy examples where the answer is clearly embedded in the passage, the neural components designed for paying attention to relevant portions of the passage fail to serve their intended purpose. We believe that the non-adversarial dataset created as a part of this work would complement the research on adversarial evaluation and give a more realistic assessment of the ability of RC models. All the datasets and codes developed as a part of this work will be made publicly available.