 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Text Style Transfer via Style Masked Language Models
Oct 12, 2022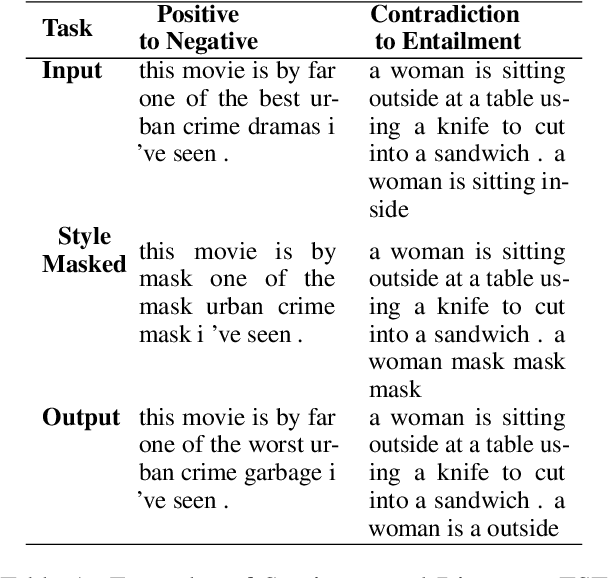
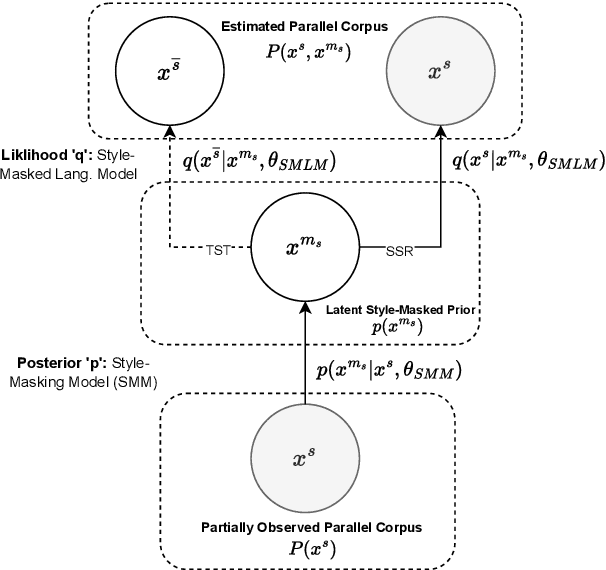

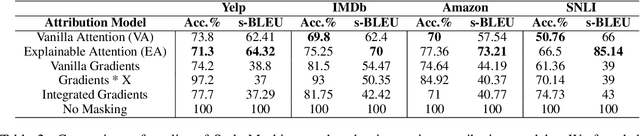
Text Style Transfer (TST) is performable through approaches such as latent space disentanglement, cycle-consistency losses, prototype editing etc. The prototype editing approach, which is known to be quite successful in TST, involves two key phases a) Masking of source style-associated tokens and b) Reconstruction of this source-style masked sentence conditioned with the target style. We follow a similar transduction method, in which we transpose the more difficult direct source to target TST task to a simpler Style-Masked Language Model (SMLM) Task, wherein, similar to BERT \cite{bert}, the goal of our model is now to reconstruct the source sentence from its style-masked version. We arrive at the SMLM mechanism naturally by formulating prototype editing/ transduction methods in a probabilistic framework, where TST resolves into estimating a hypothetical parallel dataset from a partially observed parallel dataset, wherein each domain is assumed to have a common latent style-masked prior. To generate this style-masked prior, we use "Explainable Attention" as our choice of attribution for a more precise style-masking step and also introduce a cost-effective and accurate "Attribution-Surplus" method of determining the position of masks from any arbitrary attribution model in O(1) time. We empirically show that this non-generational approach well suites the "content preserving" criteria for a task like TST, even for a complex style like Discourse Manipulation. Our model, the Style MLM, outperforms strong TST baselines and is on par with state-of-the-art TST models, which use complex architectures and orders of more parameters.
Towards Robust and Semantically Organised Latent Representations for Unsupervised Text Style Transfer
May 04, 2022

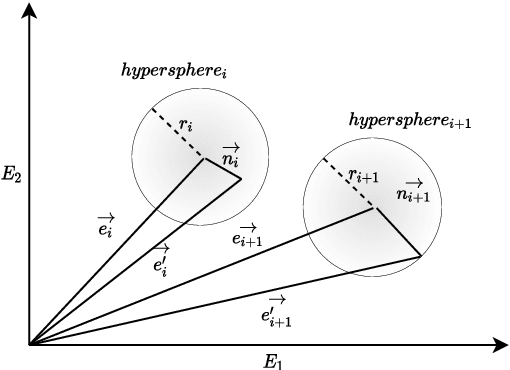
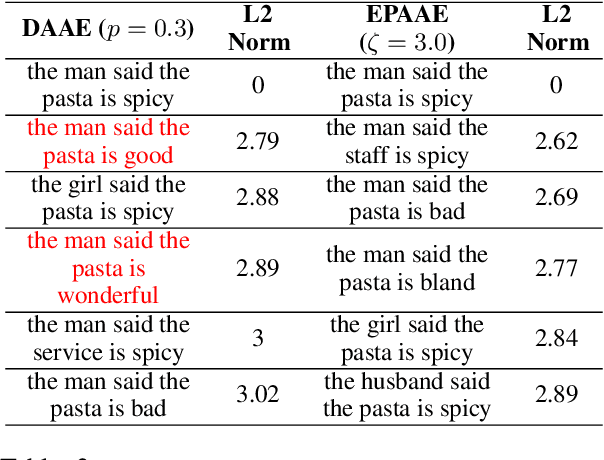
Recent studies show that auto-encoder based approaches successfully perform language generation, smooth sentence interpolation, and style transfer over unseen attributes using unlabelled datasets in a zero-shot manner. The latent space geometry of such models is organised well enough to perform on datasets where the style is "coarse-grained" i.e. a small fraction of words alone in a sentence are enough to determine the overall style label. A recent study uses a discrete token-based perturbation approach to map "similar" sentences ("similar" defined by low Levenshtein distance/ high word overlap) close by in latent space. This definition of "similarity" does not look into the underlying nuances of the constituent words while mapping latent space neighbourhoods and therefore fails to recognise sentences with different style-based semantics while mapping latent neighbourhoods. We introduce EPAAEs (Embedding Perturbed Adversarial AutoEncoders) which completes this perturbation model, by adding a finely adjustable noise component on the continuous embeddings space. We empirically show that this (a) produces a better organised latent space that clusters stylistically similar sentences together, (b) performs best on a diverse set of text style transfer tasks than similar denoising-inspired baselines, and (c) is capable of fine-grained control of Style Transfer strength. We also extend the text style transfer tasks to NLI datasets and show that these more complex definitions of style are learned best by EPAAE. To the best of our knowledge, extending style transfer to NLI tasks has not been explored before.
Towards Transparent and Explainable Attention Models
Apr 29, 2020
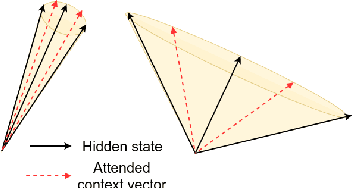
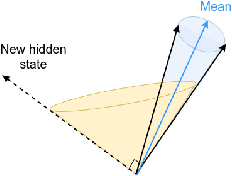
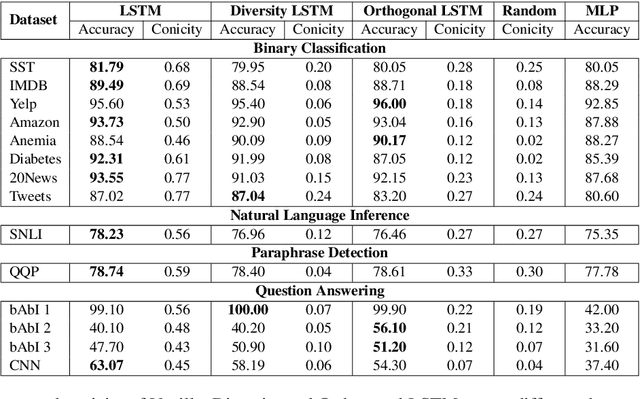
Recent studies on interpretability of attention distributions have led to notions of faithful and plausible explanations for a model's predictions. Attention distributions can be considered a faithful explanation if a higher attention weight implies a greater impact on the model's prediction. They can be considered a plausible explanation if they provide a human-understandable justification for the model's predictions. In this work, we first explain why current attention mechanisms in LSTM based encoders can neither provide a faithful nor a plausible explanation of the model's predictions. We observe that in LSTM based encoders the hidden representations at different time-steps are very similar to each other (high conicity) and attention weights in these situations do not carry much meaning because even a random permutation of the attention weights does not affect the model's predictions. Based on experiments on a wide variety of tasks and datasets, we observe attention distributions often attribute the model's predictions to unimportant words such as punctuation and fail to offer a plausible explanation for the predictions. To make attention mechanisms more faithful and plausible, we propose a modified LSTM cell with a diversity-driven training objective that ensures that the hidden representations learned at different time steps are diverse. We show that the resulting attention distributions offer more transparency as they (i) provide a more precise importance ranking of the hidden states (ii) are better indicative of words important for the model's predictions (iii) correlate better with gradient-based attribution methods. Human evaluations indicate that the attention distributions learned by our model offer a plausible explanation of the model's predictions. Our code has been made publicly available at https://github.com/akashkm99/Interpretable-Attention