 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Text Style Transfer via Style Masked Language Models
Oct 12, 2022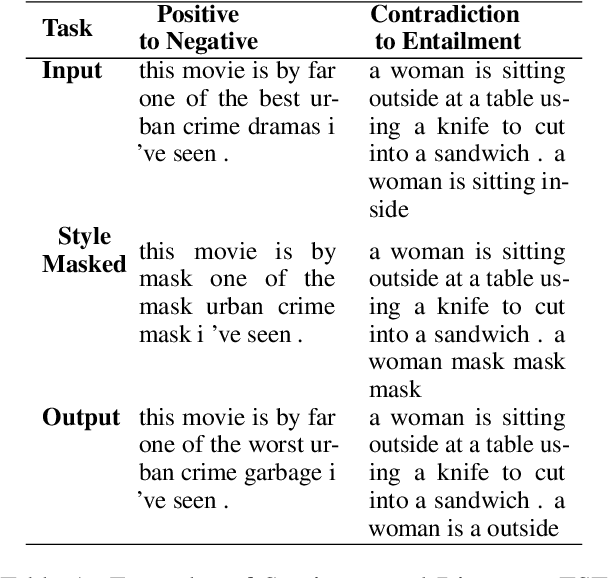
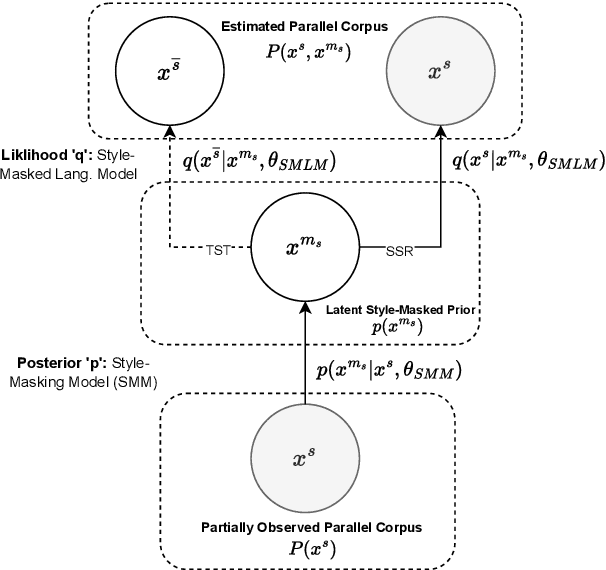

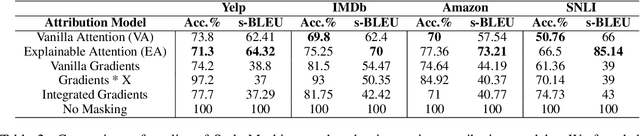
Text Style Transfer (TST) is performable through approaches such as latent space disentanglement, cycle-consistency losses, prototype editing etc. The prototype editing approach, which is known to be quite successful in TST, involves two key phases a) Masking of source style-associated tokens and b) Reconstruction of this source-style masked sentence conditioned with the target style. We follow a similar transduction method, in which we transpose the more difficult direct source to target TST task to a simpler Style-Masked Language Model (SMLM) Task, wherein, similar to BERT \cite{bert}, the goal of our model is now to reconstruct the source sentence from its style-masked version. We arrive at the SMLM mechanism naturally by formulating prototype editing/ transduction methods in a probabilistic framework, where TST resolves into estimating a hypothetical parallel dataset from a partially observed parallel dataset, wherein each domain is assumed to have a common latent style-masked prior. To generate this style-masked prior, we use "Explainable Attention" as our choice of attribution for a more precise style-masking step and also introduce a cost-effective and accurate "Attribution-Surplus" method of determining the position of masks from any arbitrary attribution model in O(1) time. We empirically show that this non-generational approach well suites the "content preserving" criteria for a task like TST, even for a complex style like Discourse Manipulation. Our model, the Style MLM, outperforms strong TST baselines and is on par with state-of-the-art TST models, which use complex architectures and orders of more parameters.