 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Prunability of Attention Heads in Multilingual BERT
Sep 26, 2021
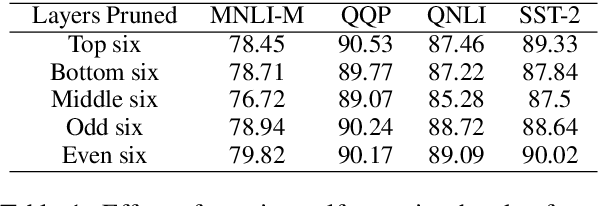
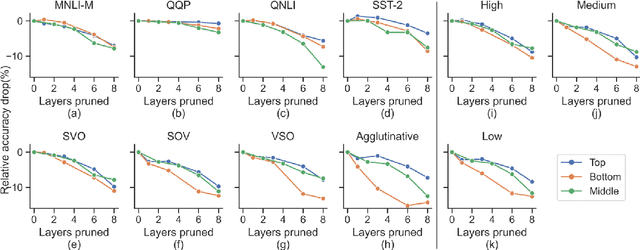

Large multilingual models, such as mBERT, have shown promise in crosslingual transfer. In this work, we employ pruning to quantify the robustness and interpret layer-wise importance of mBERT. On four GLUE tasks, the relative drops in accuracy due to pruning have almost identical results on mBERT and BERT suggesting that the reduced attention capacity of the multilingual models does not affect robustness to pruning. For the crosslingual task XNLI, we report higher drops in accuracy with pruning indicating lower robustness in crosslingual transfer. Also, the importance of the encoder layers sensitively depends on the language family and the pre-training corpus size. The top layers, which are relatively more influenced by fine-tuning, encode important information for languages similar to English (SVO) while the bottom layers, which are relatively less influenced by fine-tuning, are particularly important for agglutinative and low-resource languages.
The heads hypothesis: A unifying statistical approach towards understanding multi-headed attention in BERT
Jan 22, 2021
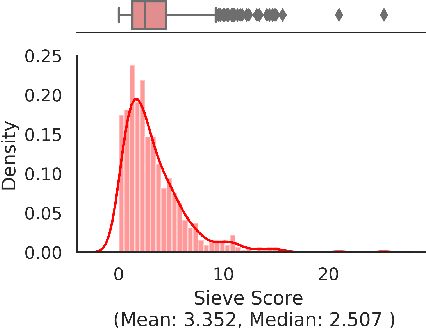
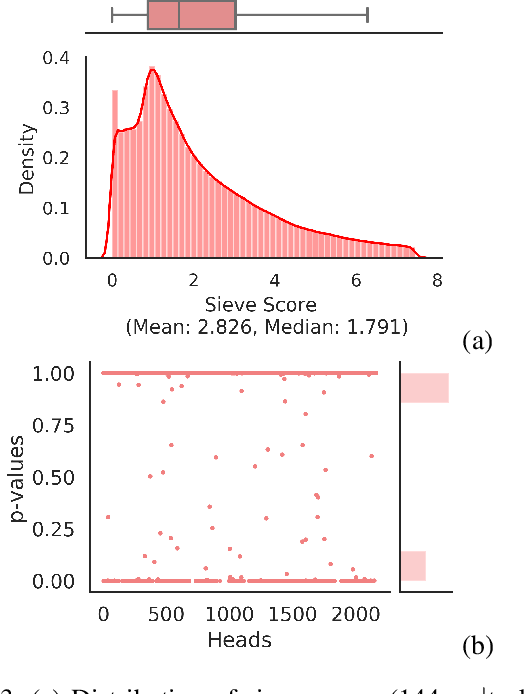
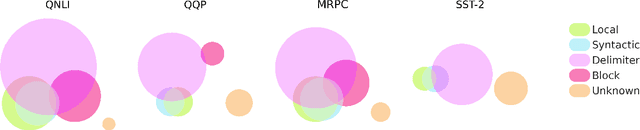
Multi-headed attention heads are a mainstay in transformer-based models. Different methods have been proposed to classify the role of each attention head based on the relations between tokens which have high pair-wise attention. These roles include syntactic (tokens with some syntactic relation), local (nearby tokens), block (tokens in the same sentence) and delimiter (the special [CLS], [SEP] tokens). There are two main challenges with existing methods for classification: (a) there are no standard scores across studies or across functional roles, and (b) these scores are often average quantities measured across sentences without capturing statistical significance. In this work, we formalize a simple yet effective score that generalizes to all the roles of attention heads and employs hypothesis testing on this score for robust inference. This provides us the right lens to systematically analyze attention heads and confidently comment on many commonly posed questions on analyzing the BERT model. In particular, we comment on the co-location of multiple functional roles in the same attention head, the distribution of attention heads across layers, and effect of fine-tuning for specific NLP tasks on these functional roles.
On the Importance of Local Information in Transformer Based Models
Aug 13, 2020


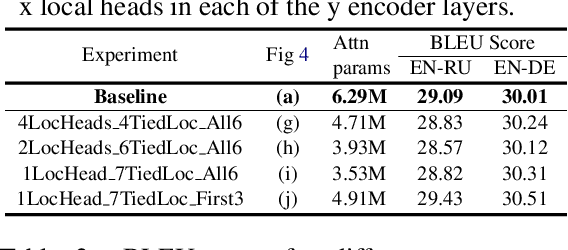
The self-attention module is a key component of Transformer-based models, wherein each token pays attention to every other token. Recent studies have shown that these heads exhibit syntactic, semantic, or local behaviour. Some studies have also identified promise in restricting this attention to be local, i.e., a token attending to other tokens only in a small neighbourhood around it. However, no conclusive evidence exists that such local attention alone is sufficient to achieve high accuracy on multiple NLP tasks. In this work, we systematically analyse the role of locality information in learnt models and contrast it with the role of syntactic information. More specifically, we first do a sensitivity analysis and show that, at every layer, the representation of a token is much more sensitive to tokens in a small neighborhood around it than to tokens which are syntactically related to it. We then define an attention bias metric to determine whether a head pays more attention to local tokens or to syntactically related tokens. We show that a larger fraction of heads have a locality bias as compared to a syntactic bias. Having established the importance of local attention heads, we train and evaluate models where varying fractions of the attention heads are constrained to be local. Such models would be more efficient as they would have fewer computations in the attention layer. We evaluate these models on 4 GLUE datasets (QQP, SST-2, MRPC, QNLI) and 2 MT datasets (En-De, En-Ru) and clearly demonstrate that such constrained models have comparable performance to the unconstrained models. Through this systematic evaluation we establish that attention in Transformer-based models can be constrained to be local without affecting performance.