 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Prunability of Attention Heads in Multilingual BERT
Paper and Code

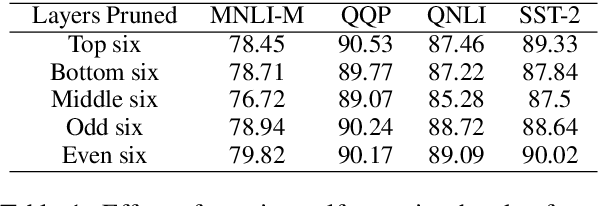
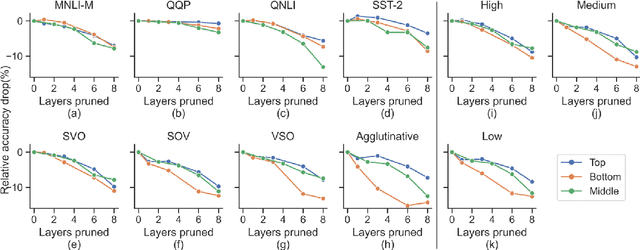

Large multilingual models, such as mBERT, have shown promise in crosslingual transfer. In this work, we employ pruning to quantify the robustness and interpret layer-wise importance of mBERT. On four GLUE tasks, the relative drops in accuracy due to pruning have almost identical results on mBERT and BERT suggesting that the reduced attention capacity of the multilingual models does not affect robustness to pruning. For the crosslingual task XNLI, we report higher drops in accuracy with pruning indicating lower robustness in crosslingual transfer. Also, the importance of the encoder layers sensitively depends on the language family and the pre-training corpus size. The top layers, which are relatively more influenced by fine-tuning, encode important information for languages similar to English (SVO) while the bottom layers, which are relatively less influenced by fine-tuning, are particularly important for agglutinative and low-resource languages.