 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for Virtual Human Gesture Selection
Mar 18, 2025Co-speech gestures convey a wide variety of meanings and play an important role in face-to-face human interactions. These gestures significantly influence the addressee's engagement, recall, comprehension, and attitudes toward the speaker. Similarly, they impact interactions between humans and embodied virtual agents. The process of selecting and animating meaningful gestures has thus become a key focus in the design of these agents. However, automating this gesture selection process poses a significant challenge. Prior gesture generation techniques have varied from fully automated, data-driven methods, which often struggle to produce contextually meaningful gestures, to more manual approaches that require crafting specific gesture expertise and are time-consuming and lack generalizability. In this paper, we leverage the semantic capabilities of Large Language Models to develop a gesture selection approach that suggests meaningful, appropriate co-speech gestures. We first describe how information on gestures is encoded into GPT-4. Then, we conduct a study to evaluate alternative prompting approaches for their ability to select meaningful, contextually relevant gestures and to align them appropriately with the co-speech utterance. Finally, we detail and demonstrate how this approach has been implemented within a virtual agent system, automating the selection and subsequent animation of the selected gestures for enhanced human-agent interactions.
Using Virtual Humans to Understand Real Ones
Jun 13, 2016
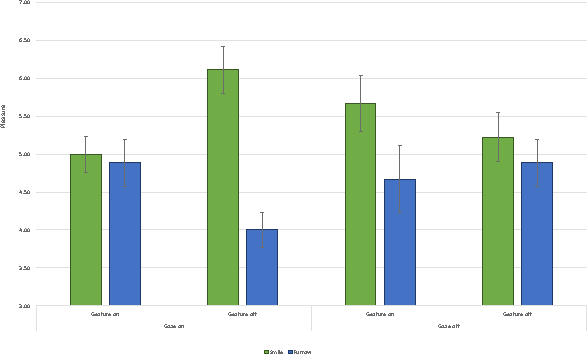
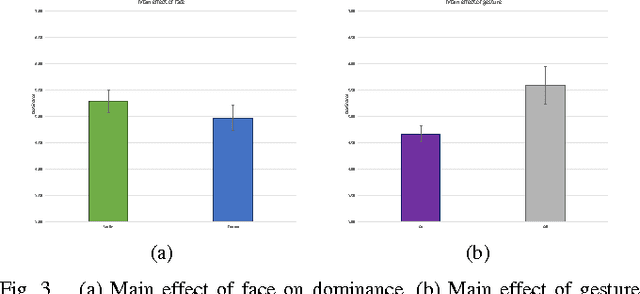
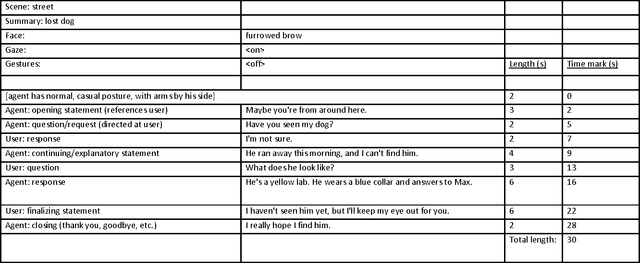
Human interactions are characterized by explicit as well as implicit channels of communication. While the explicit channel transmits overt messages, the implicit ones transmit hidden messages about the communicator (e.g., his/her intentions and attitudes). There is a growing consensus that providing a computer with the ability to manipulate implicit affective cues should allow for a more meaningful and natural way of studying particular non-verbal signals of human-human communications by human-computer interactions. In this pilot study, we created a non-dynamic human-computer interaction while manipulating three specific non-verbal channels of communication: gaze pattern, facial expression, and gesture. Participants rated the virtual agent on affective dimensional scales (pleasure, arousal, and dominance) while their physiological signal (electrodermal activity, EDA) was captured during the interaction. Assessment of the behavioral data revealed a significant and complex three-way interaction between gaze, gesture, and facial configuration on the dimension of pleasure, as well as a main effect of gesture on the dimension of dominance. These results suggest a complex relationship between different non-verbal cues and the social context in which they are interpreted. Qualifying considerations as well as possible next steps are further discussed in light of these exploratory findings.