 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX$^3$KD: Knowledge Distillation Across Modalities, Tasks and Stages for Multi-Camera 3D Object Detection
Mar 03, 2023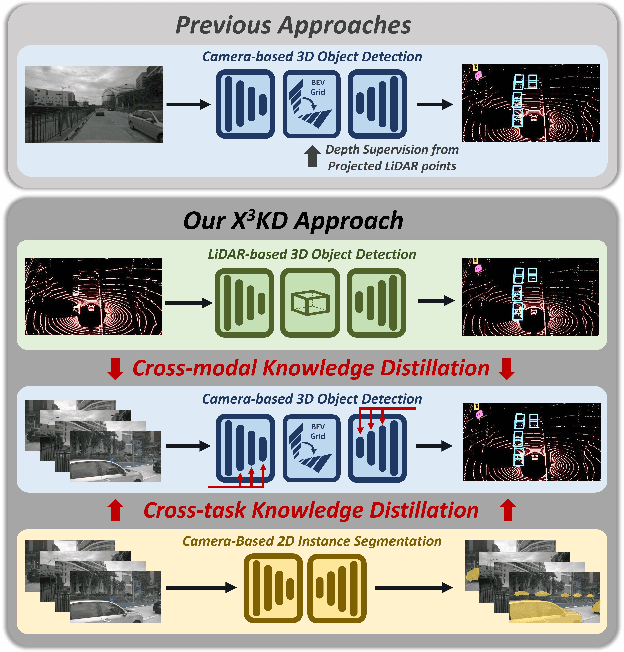
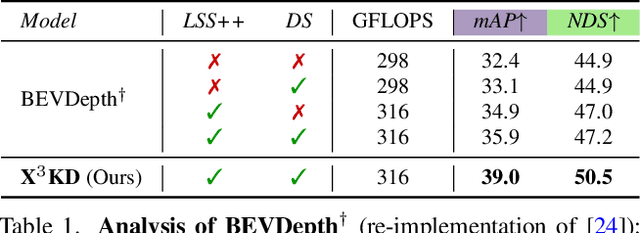
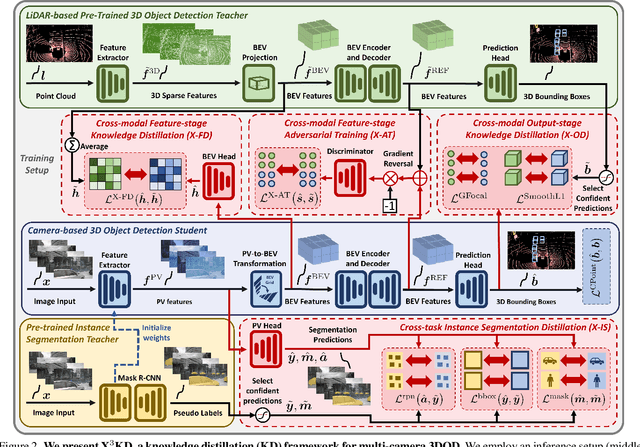
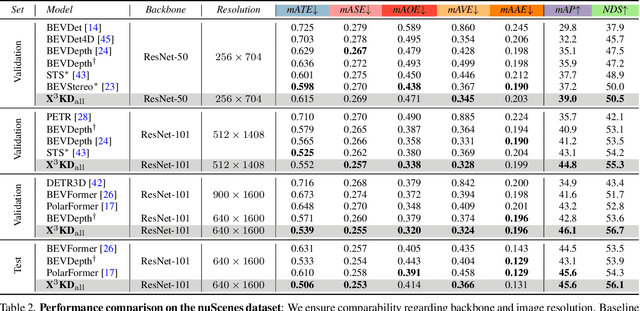
Recent advances in 3D object detection (3DOD) have obtained remarkably strong results for LiDAR-based models. In contrast, surround-view 3DOD models based on multiple camera images underperform due to the necessary view transformation of features from perspective view (PV) to a 3D world representation which is ambiguous due to missing depth information. This paper introduces X$^3$KD, a comprehensive knowledge distillation framework across different modalities, tasks, and stages for multi-camera 3DOD. Specifically, we propose cross-task distillation from an instance segmentation teacher (X-IS) in the PV feature extraction stage providing supervision without ambiguous error backpropagation through the view transformation. After the transformation, we apply cross-modal feature distillation (X-FD) and adversarial training (X-AT) to improve the 3D world representation of multi-camera features through the information contained in a LiDAR-based 3DOD teacher. Finally, we also employ this teacher for cross-modal output distillation (X-OD), providing dense supervision at the prediction stage. We perform extensive ablations of knowledge distillation at different stages of multi-camera 3DOD. Our final X$^3$KD model outperforms previous state-of-the-art approaches on the nuScenes and Waymo datasets and generalizes to RADAR-based 3DOD. Qualitative results video at https://youtu.be/1do9DPFmr38.
Deep Markov Spatio-Temporal Factorization
Mar 22, 2020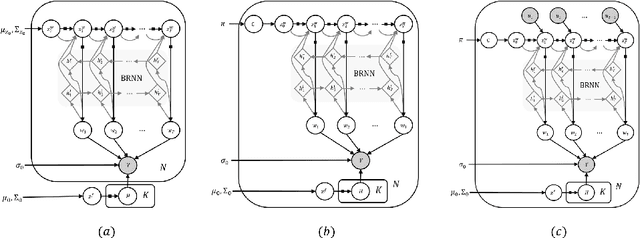

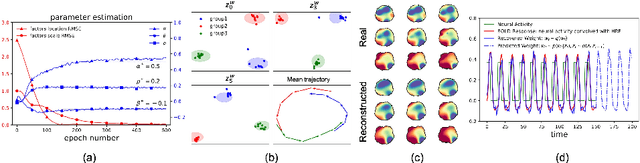

We introduce deep Markov spatio-temporal factorization (DMSTF), a deep generative model for spatio-temporal data. Like other factor analysis methods, DMSTF approximates high-dimensional data by a product between time-dependent weights and spatially dependent factors. These weights and factors are in turn represented in terms of lower-dimensional latent variables that we infer using stochastic variational inference. The innovation in DMSTF is that we parameterize weights in terms of a deep Markovian prior, which is able to characterize nonlinear temporal dynamics. We parameterize the corresponding variational distribution using a bidirectional recurrent network. This results in a flexible family of hierarchical deep generative factor analysis models that can be extended to perform time series clustering, or perform factor analysis in the presence of a control signal. Our experiments, which consider simulated data, fMRI data, and traffic data, demonstrate that DMSTF outperforms related methods in terms of reconstruction accuracy and can perform forecasting in a variety domains with nonlinear temporal transitions.
G-LBM:Generative Low-dimensional Background Model Estimation from Video Sequences
Mar 16, 2020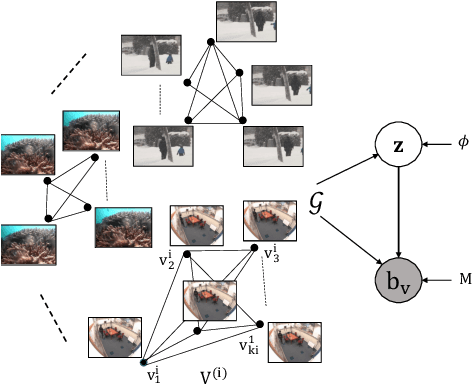
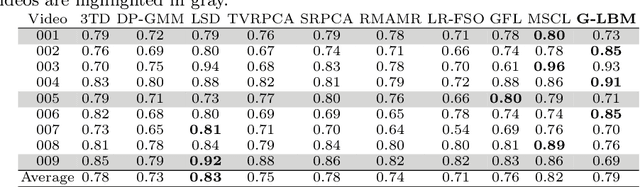
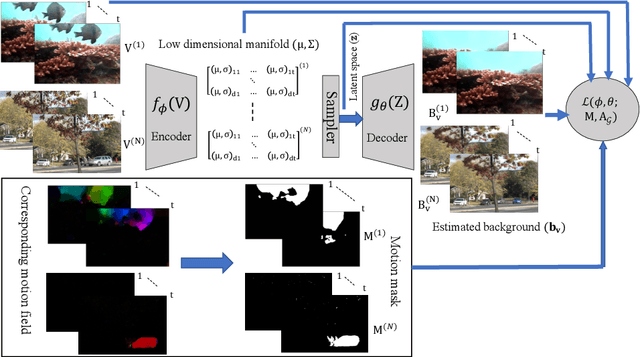
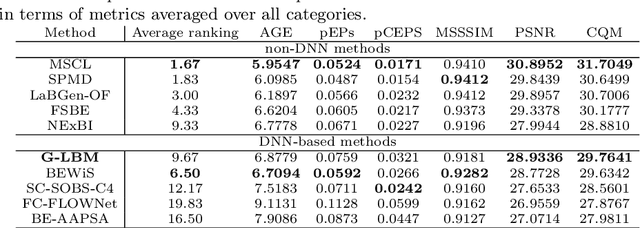
In this paper, we propose a computationally tractable and theoretically supported non-linear low-dimensional generative model to represent real-world data in the presence of noise and sparse outliers. The non-linear low-dimensional manifold discovery of data is done through describing a joint distribution over observations, and their low-dimensional representations (i.e. manifold coordinates). Our model, called generative low-dimensional background model (G-LBM) admits variational operations on the distribution of the manifold coordinates and simultaneously generates a low-rank structure of the latent manifold given the data. Therefore, our probabilistic model contains the intuition of the non-probabilistic low-dimensional manifold learning. G-LBM selects the intrinsic dimensionality of the underling manifold of the observations, and its probabilistic nature models the noise in the observation data. G-LBM has direct application in the background scenes model estimation from video sequences and we have evaluated its performance on SBMnet-2016 and BMC2012 datasets, where it achieved a performance higher or comparable to other state-of-the-art methods while being agnostic to the background scenes in videos. Besides, in challenges such as camera jitter and background motion, G-LBM is able to robustly estimate the background by effectively modeling the uncertainties in video observations in these scenarios.
Target-Specific Action Classification for Automated Assessment of Human Motor Behavior from Video
Sep 20, 2019
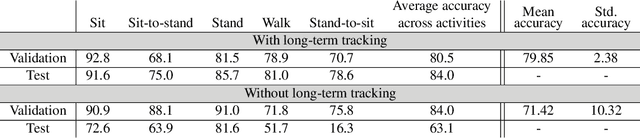
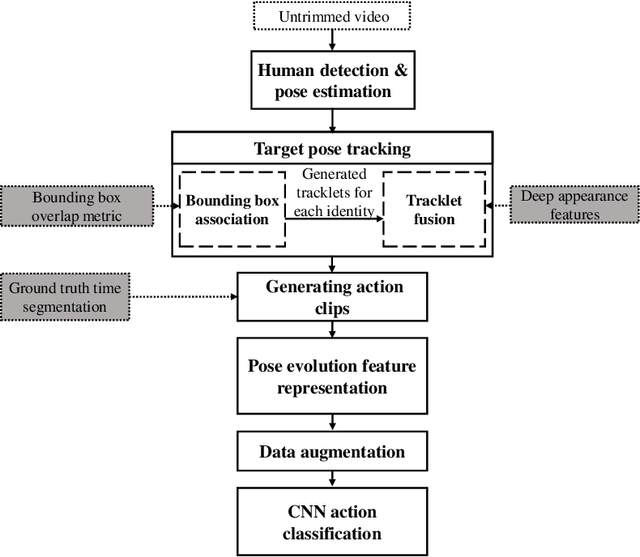
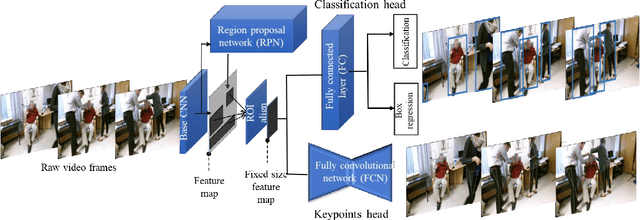
Objective monitoring and assessment of human motor behavior can improve the diagnosis and management of several medical conditions. Over the past decade, significant advances have been made in the use of wearable technology for continuously monitoring human motor behavior in free-living conditions. However, wearable technology remains ill-suited for applications which require monitoring and interpretation of complex motor behaviors (e.g. involving interactions with the environment). Recent advances in computer vision and deep learning have opened up new possibilities for extracting information from video recordings. In this paper, we present a hierarchical vision-based behavior phenotyping method for classification of basic human actions in video recordings performed using a single RGB camera. Our method addresses challenges associated with tracking multiple human actors and classification of actions in videos recorded in changing environments with different fields of view. We implement a cascaded pose tracker that uses temporal relationships between detections for short-term tracking and appearance-based tracklet fusion for long-term tracking. Furthermore, for action classification, we use pose evolution maps derived from the cascaded pose tracker as low-dimensional and interpretable representations of the movement sequences for training a convolutional neural network. The cascaded pose tracker achieves an average accuracy of 88\% in tracking the target human actor in our video recordings, and overall system achieves average test accuracy of 84\% for target-specific action classification in untrimmed video recordings.
DeepPBM: Deep Probabilistic Background Model Estimation from Video Sequences
Feb 03, 2019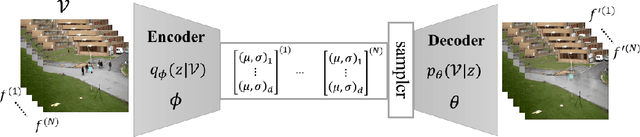
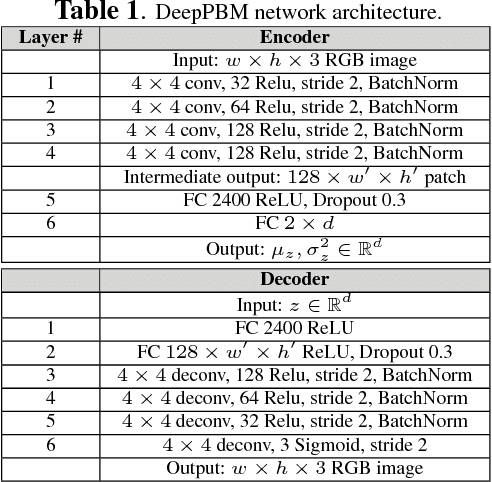
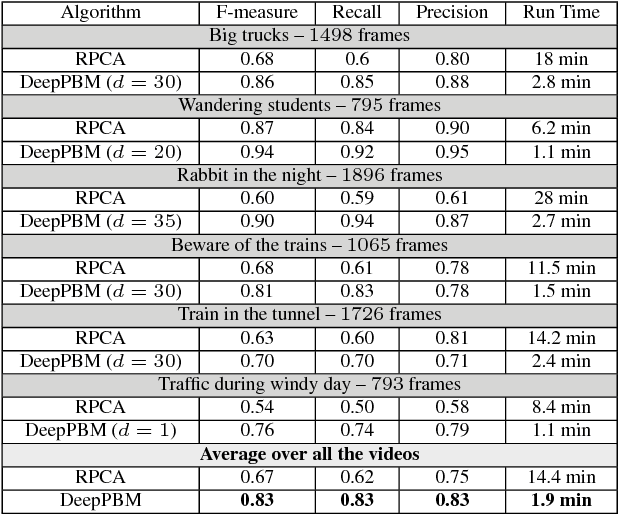

This paper presents a novel unsupervised probabilistic model estimation of visual background in video sequences using a variational autoencoder framework. Due to the redundant nature of the backgrounds in surveillance videos, visual information of the background can be compressed into a low-dimensional subspace in the encoder part of the variational autoencoder, while the highly variant information of its moving foreground gets filtered throughout its encoding-decoding process. Our deep probabilistic background model (DeepPBM) estimation approach is enabled by the power of deep neural networks in learning compressed representations of video frames and reconstructing them back to the original domain. We evaluated the performance of our DeepPBM in background subtraction on 9 surveillance videos from the background model challenge (BMC2012) dataset, and compared that with a standard subspace learning technique, robust principle component analysis (RPCA), which similarly estimates a deterministic low dimensional representation of the background in videos and is widely used for this application. Our method outperforms RPCA on BMC2012 dataset with 23% in average in F-measure score, emphasizing that background subtraction using the trained model can be done in more than 10 times faster.
Background Subtraction via Fast Robust Matrix Completion
Nov 03, 2017
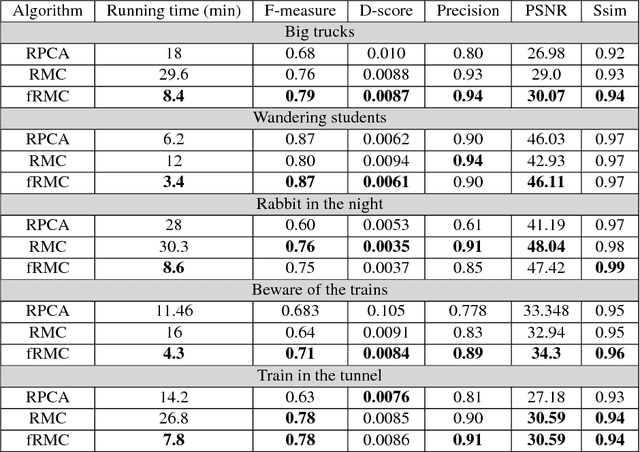

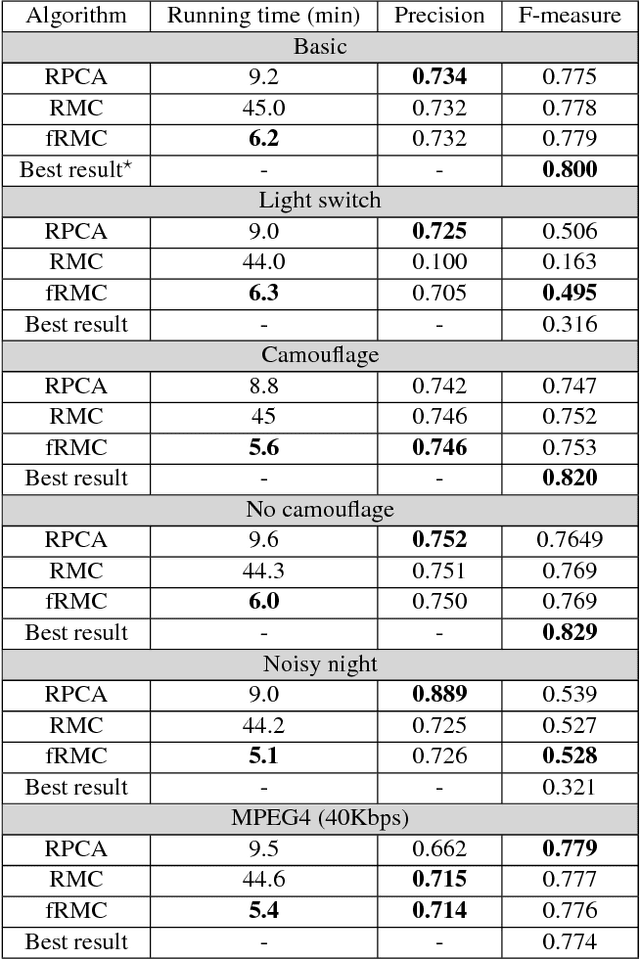
Background subtraction is the primary task of the majority of video inspection systems. The most important part of the background subtraction which is common among different algorithms is background modeling. In this regard, our paper addresses the problem of background modeling in a computationally efficient way, which is important for current eruption of "big data" processing coming from high resolution multi-channel videos. Our model is based on the assumption that background in natural images lies on a low-dimensional subspace. We formulated and solved this problem in a low-rank matrix completion framework. In modeling the background, we benefited from the in-face extended Frank-Wolfe algorithm for solving a defined convex optimization problem. We evaluated our fast robust matrix completion (fRMC) method on both background models challenge (BMC) and Stuttgart artificial background subtraction (SABS) datasets. The results were compared with the robust principle component analysis (RPCA) and low-rank robust matrix completion (RMC) methods, both solved by inexact augmented Lagrangian multiplier (IALM). The results showed faster computation, at least twice as when IALM solver is used, while having a comparable accuracy even better in some challenges, in subtracting the backgrounds in order to detect moving objects in the scene.
Using Virtual Humans to Understand Real Ones
Jun 13, 2016
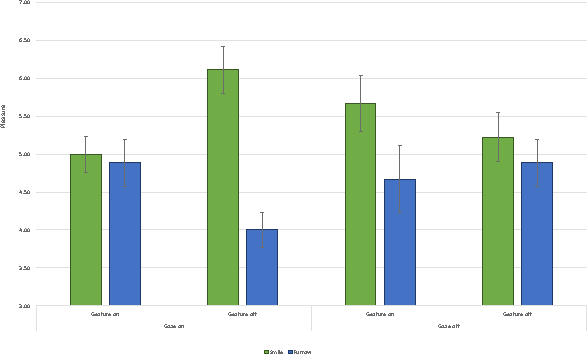
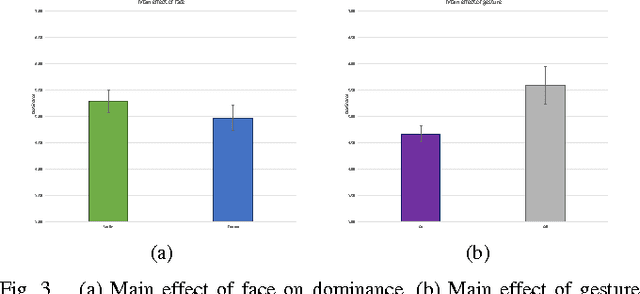
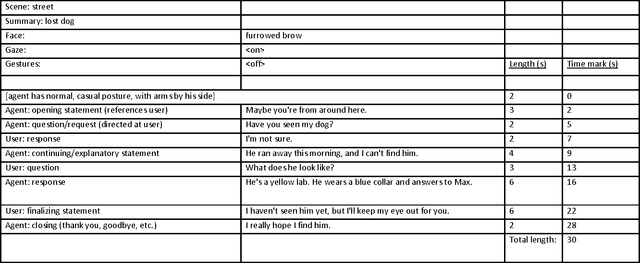
Human interactions are characterized by explicit as well as implicit channels of communication. While the explicit channel transmits overt messages, the implicit ones transmit hidden messages about the communicator (e.g., his/her intentions and attitudes). There is a growing consensus that providing a computer with the ability to manipulate implicit affective cues should allow for a more meaningful and natural way of studying particular non-verbal signals of human-human communications by human-computer interactions. In this pilot study, we created a non-dynamic human-computer interaction while manipulating three specific non-verbal channels of communication: gaze pattern, facial expression, and gesture. Participants rated the virtual agent on affective dimensional scales (pleasure, arousal, and dominance) while their physiological signal (electrodermal activity, EDA) was captured during the interaction. Assessment of the behavioral data revealed a significant and complex three-way interaction between gaze, gesture, and facial configuration on the dimension of pleasure, as well as a main effect of gesture on the dimension of dominance. These results suggest a complex relationship between different non-verbal cues and the social context in which they are interpreted. Qualifying considerations as well as possible next steps are further discussed in light of these exploratory findings.
Decoding Emotional Experience through Physiological Signal Processing
Jun 01, 2016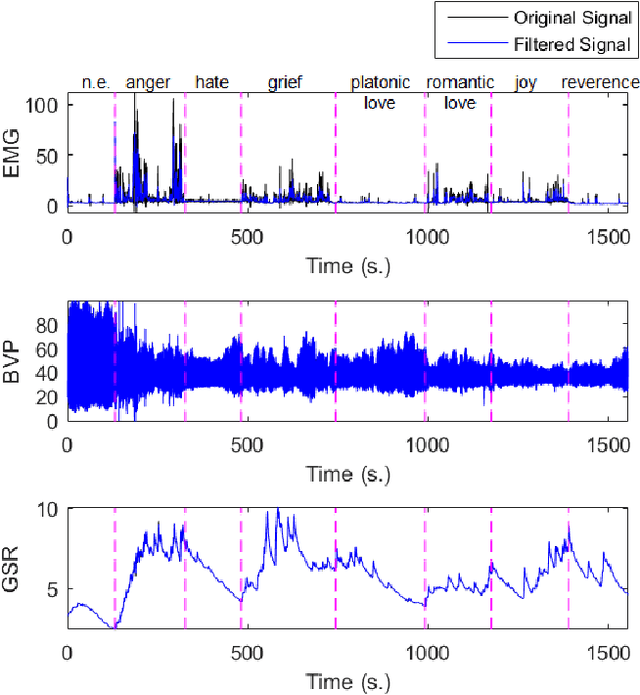
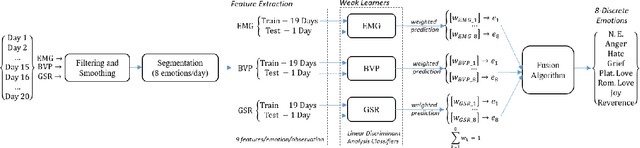
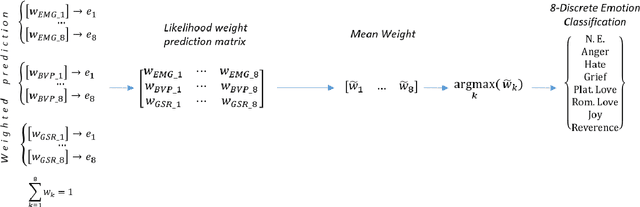
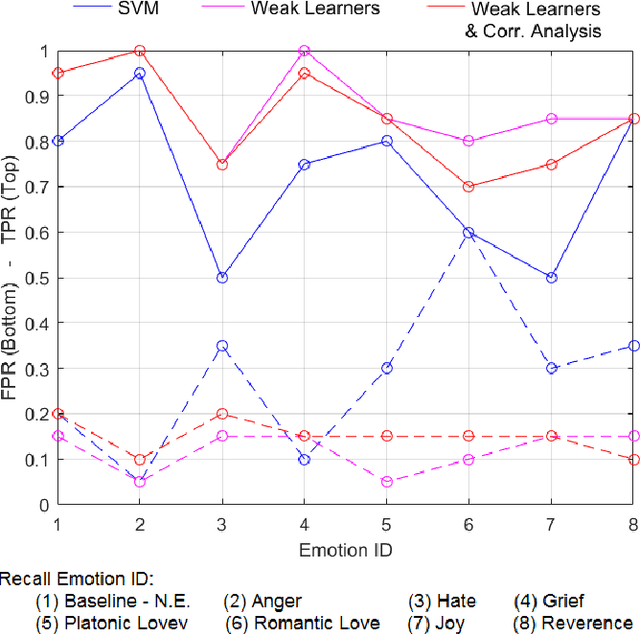
There is an increasing consensus among re- searchers that making a computer emotionally intelligent with the ability to decode human affective states would allow a more meaningful and natural way of human-computer interactions (HCIs). One unobtrusive and non-invasive way of recognizing human affective states entails the exploration of how physiological signals vary under different emotional experiences. In particular, this paper explores the correlation between autonomically-mediated changes in multimodal body signals and discrete emotional states. In order to fully exploit the information in each modality, we have provided an innovative classification approach for three specific physiological signals including Electromyogram (EMG), Blood Volume Pressure (BVP) and Galvanic Skin Response (GSR). These signals are analyzed as inputs to an emotion recognition paradigm based on fusion of a series of weak learners. Our proposed classification approach showed 88.1% recognition accuracy, which outperformed the conventional Support Vector Machine (SVM) classifier with 17% accuracy improvement. Furthermore, in order to avoid information redundancy and the resultant over-fitting, a feature reduction method is proposed based on a correlation analysis to optimize the number of features required for training and validating each weak learner. Results showed that despite the feature space dimensionality reduction from 27 to 18 features, our methodology preserved the recognition accuracy of about 85.0%. This reduction in complexity will get us one step closer towards embedding this human emotion encoder in the wireless and wearable HCI platforms.