 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamical Deep Generative Latent Modeling of 3D Skeletal Motion
Jun 18, 2021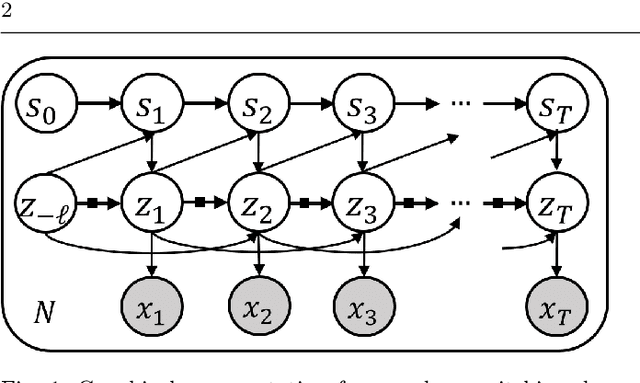
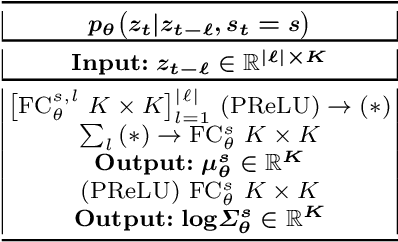
In this paper, we propose a Bayesian switching dynamical model for segmentation of 3D pose data over time that uncovers interpretable patterns in the data and is generative. Our model decomposes highly correlated skeleton data into a set of few spatial basis of switching temporal processes in a low-dimensional latent framework. We parameterize these temporal processes with regard to a switching deep vector autoregressive prior in order to accommodate both multimodal and higher-order nonlinear inter-dependencies. This results in a dynamical deep generative latent model that parses the meaningful intrinsic states in the dynamics of 3D pose data using approximate variational inference, and enables a realistic low-level dynamical generation and segmentation of complex skeleton movements. Our experiments on four biological motion data containing bat flight, salsa dance, walking, and golf datasets substantiate superior performance of our model in comparison with the state-of-the-art methods.
Deep Switching Auto-Regressive Factorization:Application to Time Series Forecasting
Sep 10, 2020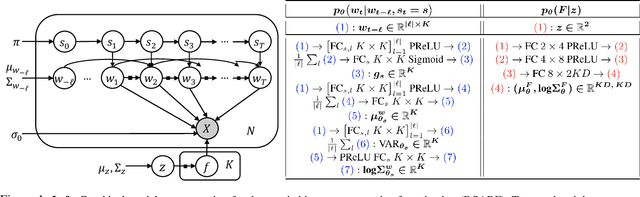
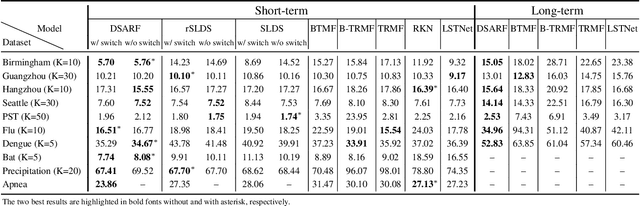
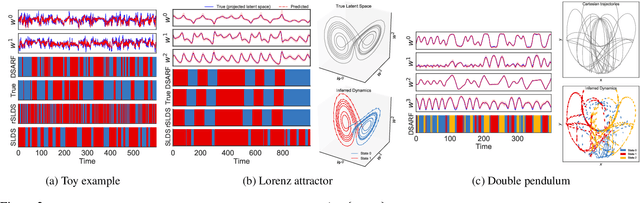
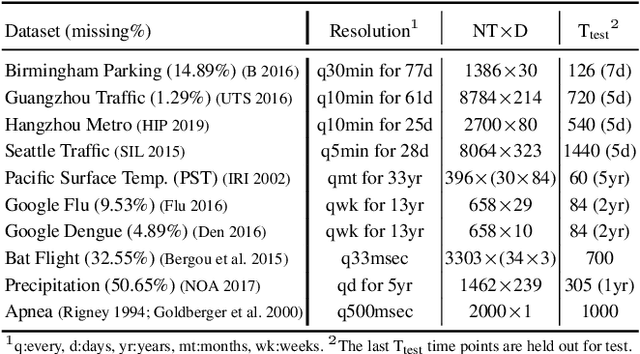
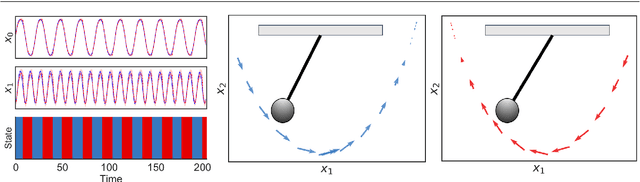
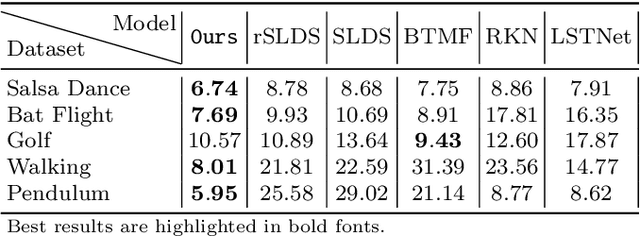
We introduce deep switching auto-regressive factorization (DSARF), a deep generative model for spatio-temporal data with the capability to unravel recurring patterns in the data and perform robust short- and long-term predictions. Similar to other factor analysis methods, DSARF approximates high dimensional data by a product between time dependent weights and spatially dependent factors. These weights and factors are in turn represented in terms of lower dimensional latent variables that are inferred using stochastic variational inference. DSARF is different from the state-of-the-art techniques in that it parameterizes the weights in terms of a deep switching vector auto-regressive likelihood governed with a Markovian prior, which is able to capture the non-linear inter-dependencies among weights to characterize multimodal temporal dynamics. This results in a flexible hierarchical deep generative factor analysis model that can be extended to (i) provide a collection of potentially interpretable states abstracted from the process dynamics, and (ii) perform short- and long-term vector time series prediction in a complex multi-relational setting. Our extensive experiments, which include simulated data and real data from a wide range of applications such as climate change, weather forecasting, traffic, infectious disease spread and nonlinear physical systems attest the superior performance of DSARF in terms of long- and short-term prediction error, when compared with the state-of-the-art methods.
Deep Markov Spatio-Temporal Factorization
Mar 22, 2020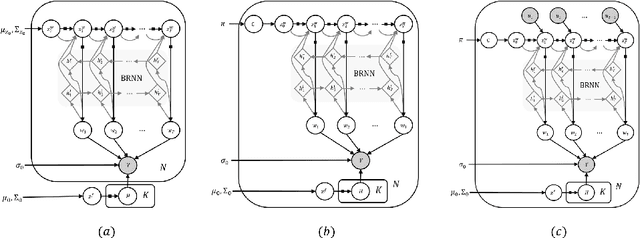

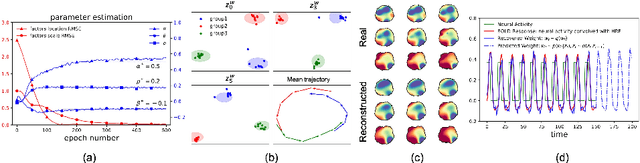

We introduce deep Markov spatio-temporal factorization (DMSTF), a deep generative model for spatio-temporal data. Like other factor analysis methods, DMSTF approximates high-dimensional data by a product between time-dependent weights and spatially dependent factors. These weights and factors are in turn represented in terms of lower-dimensional latent variables that we infer using stochastic variational inference. The innovation in DMSTF is that we parameterize weights in terms of a deep Markovian prior, which is able to characterize nonlinear temporal dynamics. We parameterize the corresponding variational distribution using a bidirectional recurrent network. This results in a flexible family of hierarchical deep generative factor analysis models that can be extended to perform time series clustering, or perform factor analysis in the presence of a control signal. Our experiments, which consider simulated data, fMRI data, and traffic data, demonstrate that DMSTF outperforms related methods in terms of reconstruction accuracy and can perform forecasting in a variety domains with nonlinear temporal transitions.
G-LBM:Generative Low-dimensional Background Model Estimation from Video Sequences
Mar 16, 2020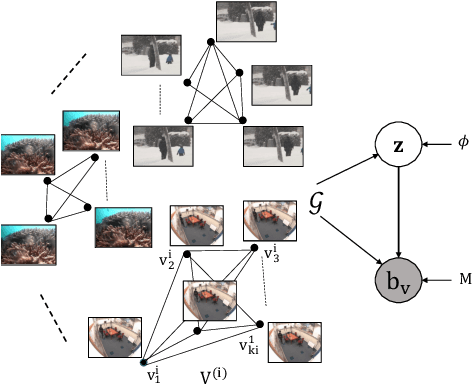
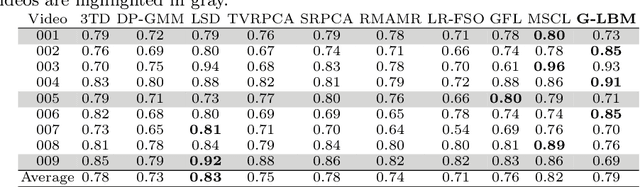
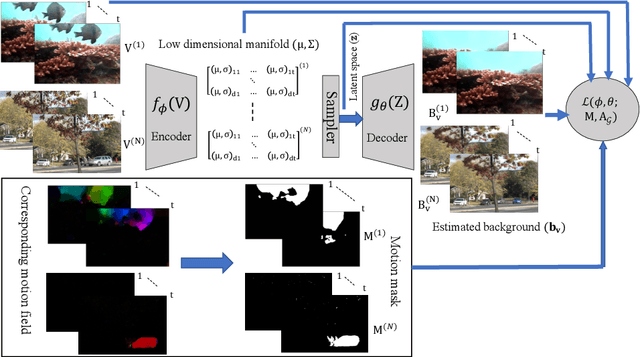
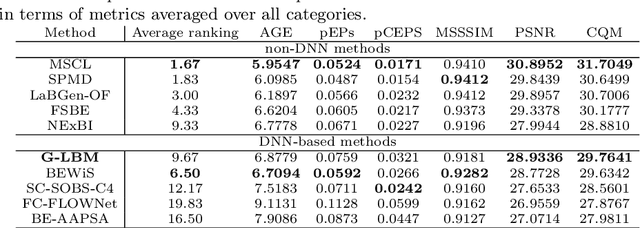
In this paper, we propose a computationally tractable and theoretically supported non-linear low-dimensional generative model to represent real-world data in the presence of noise and sparse outliers. The non-linear low-dimensional manifold discovery of data is done through describing a joint distribution over observations, and their low-dimensional representations (i.e. manifold coordinates). Our model, called generative low-dimensional background model (G-LBM) admits variational operations on the distribution of the manifold coordinates and simultaneously generates a low-rank structure of the latent manifold given the data. Therefore, our probabilistic model contains the intuition of the non-probabilistic low-dimensional manifold learning. G-LBM selects the intrinsic dimensionality of the underling manifold of the observations, and its probabilistic nature models the noise in the observation data. G-LBM has direct application in the background scenes model estimation from video sequences and we have evaluated its performance on SBMnet-2016 and BMC2012 datasets, where it achieved a performance higher or comparable to other state-of-the-art methods while being agnostic to the background scenes in videos. Besides, in challenges such as camera jitter and background motion, G-LBM is able to robustly estimate the background by effectively modeling the uncertainties in video observations in these scenarios.
Development of Use-specific High Performance Cyber-Nanomaterial Optical Detectors by Effective Choice of Machine Learning Algorithms
Jan 03, 2020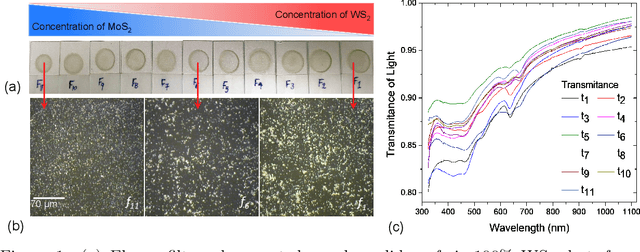
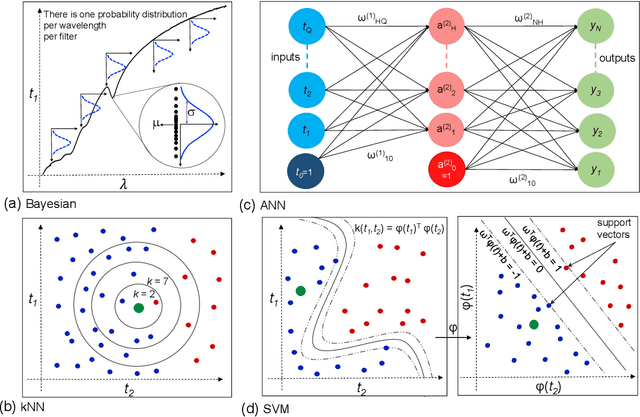
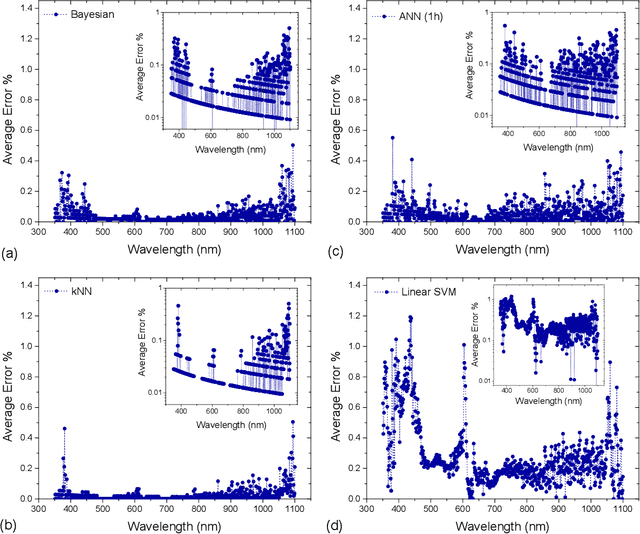
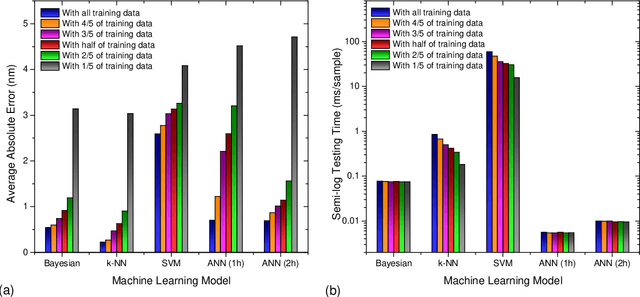
Due to their inherent variabilities,nanomaterial-based sensors are challenging to translate into real-world applications,where reliability/reproducibility is key.Recently we showed Bayesian inference can be employed on engineered variability in layered nanomaterial-based optical transmission filters to determine optical wavelengths with high accuracy/precision.In many practical applications the sensing cost/speed and long-term reliability can be equal or more important considerations.Though various machine learning tools are frequently used on sensor/detector networks to address these,nonetheless their effectiveness on nanomaterial-based sensors has not been explored.Here we show the best choice of ML algorithm in a cyber-nanomaterial detector is mainly determined by specific use considerations,e.g.,accuracy, computational cost,speed, and resilience against drifts/ageing effects.When sufficient data/computing resources are provided,highest sensing accuracy can be achieved by the kNN and Bayesian inference algorithms,but but can be computationally expensive for real-time applications.In contrast,artificial neural networks are computationally expensive to train,but provide the fastest result under testing conditions and remain reasonably accurate.When data is limited,SVMs perform well even with small training sets,while other algorithms show considerable reduction in accuracy if data is scarce,hence,setting a lower limit on the size of required training data.We show by tracking/modeling the long-term drifts of the detector performance over large (1year) period,it is possible to improve the predictive accuracy with no need for recalibration.Our research shows for the first time if the ML algorithm is chosen specific to use-case,low-cost solution-processed cyber-nanomaterial detectors can be practically implemented under diverse operational requirements,despite their inherent variabilities.
DeepPBM: Deep Probabilistic Background Model Estimation from Video Sequences
Feb 03, 2019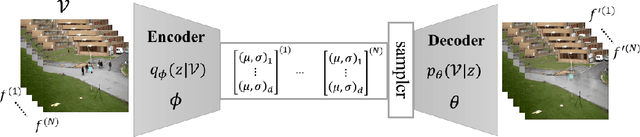
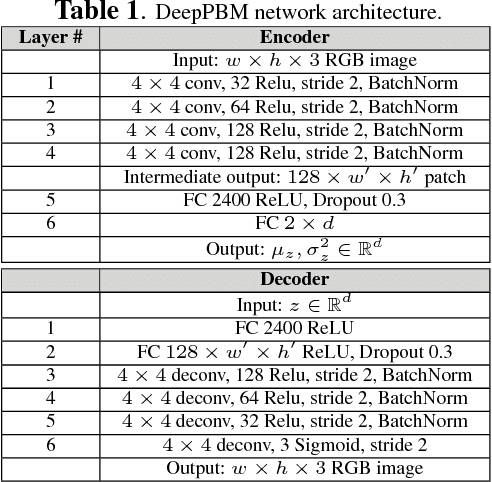
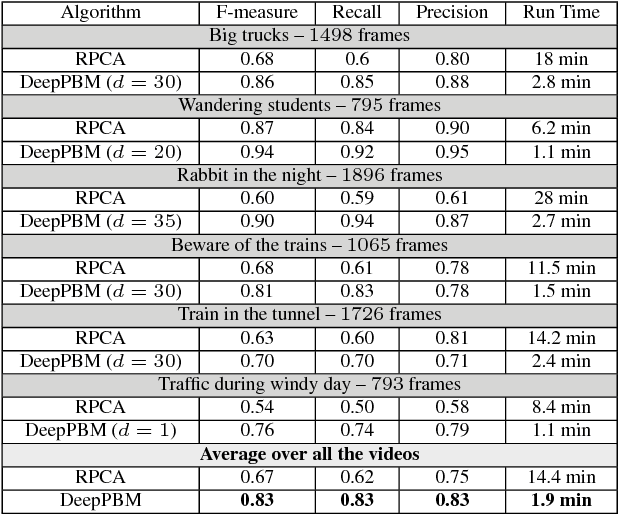

This paper presents a novel unsupervised probabilistic model estimation of visual background in video sequences using a variational autoencoder framework. Due to the redundant nature of the backgrounds in surveillance videos, visual information of the background can be compressed into a low-dimensional subspace in the encoder part of the variational autoencoder, while the highly variant information of its moving foreground gets filtered throughout its encoding-decoding process. Our deep probabilistic background model (DeepPBM) estimation approach is enabled by the power of deep neural networks in learning compressed representations of video frames and reconstructing them back to the original domain. We evaluated the performance of our DeepPBM in background subtraction on 9 surveillance videos from the background model challenge (BMC2012) dataset, and compared that with a standard subspace learning technique, robust principle component analysis (RPCA), which similarly estimates a deterministic low dimensional representation of the background in videos and is widely used for this application. Our method outperforms RPCA on BMC2012 dataset with 23% in average in F-measure score, emphasizing that background subtraction using the trained model can be done in more than 10 times faster.
Indoor GeoNet: Weakly Supervised Hybrid Learning for Depth and Pose Estimation
Nov 19, 2018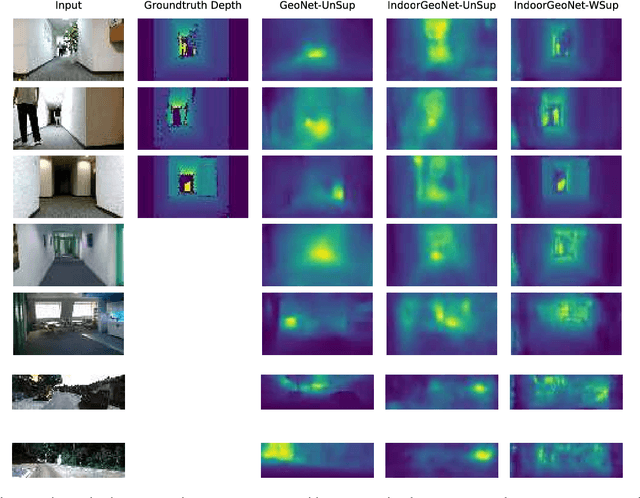



Humans naturally perceive a 3D scene in front of them through accumulation of information obtained from multiple interconnected projections of the scene and by interpreting their correspondence. This phenomenon has inspired artificial intelligence models to extract the depth and view angle of the observed scene by modeling the correspondence between different views of that scene. Our paper is built upon previous works in the field of unsupervised depth and relative camera pose estimation from temporal consecutive video frames using deep learning (DL) models. Our approach uses a hybrid learning framework introduced in a recent work called GeoNet, which leverages geometric constraints in the 3D scenes to synthesize a novel view from intermediate DL-based predicted depth and relative pose. However, the state-of-the-art unsupervised depth and pose estimation DL models are exclusively trained/tested on a few available outdoor scene datasets and we have shown they are hardly transferable to new scenes, especially from indoor environments, in which estimation requires higher precision and dealing with probable occlusions. This paper introduces "Indoor GeoNet", a weakly supervised depth and camera pose estimation model targeted for indoor scenes. In Indoor GeoNet, we take advantage of the availability of indoor RGBD datasets collected by human or robot navigators, and added partial (i.e. weak) supervision in depth training into the model. Experimental results showed that our model effectively generalizes to new scenes from different buildings. Indoor GeoNet demonstrated significant depth and pose estimation error reduction when compared to the original GeoNet, while showing 3 times more reconstruction accuracy in synthesizing novel views in indoor environments.