 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning of Efficient Geometry-Aware Neural Articulated Representations
Apr 19, 2022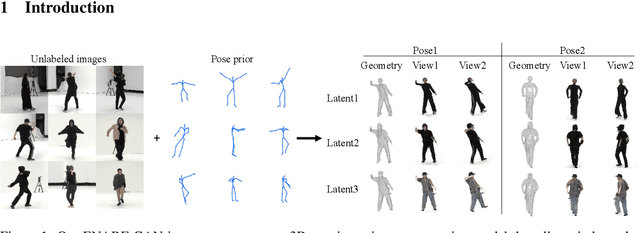
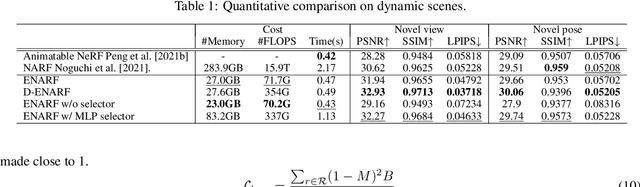
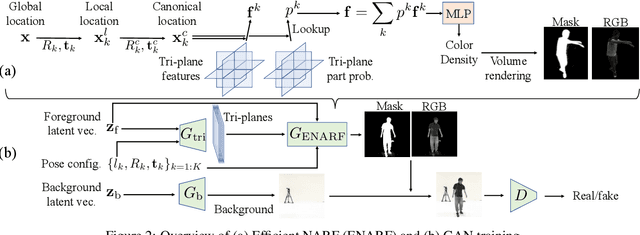
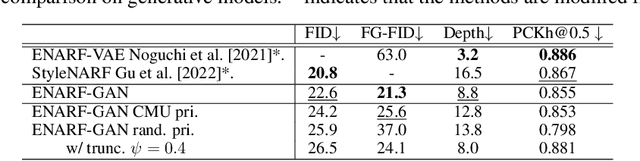
We propose an unsupervised method for 3D geometry-aware representation learning of articulated objects. Though photorealistic images of articulated objects can be rendered with explicit pose control through existing 3D neural representations, these methods require ground truth 3D pose and foreground masks for training, which are expensive to obtain. We obviate this need by learning the representations with GAN training. From random poses and latent vectors, the generator is trained to produce realistic images of articulated objects by adversarial training. To avoid a large computational cost for GAN training, we propose an efficient neural representation for articulated objects based on tri-planes and then present a GAN-based framework for its unsupervised training. Experiments demonstrate the efficiency of our method and show that GAN-based training enables learning of controllable 3D representations without supervision.
Watch It Move: Unsupervised Discovery of 3D Joints for Re-Posing of Articulated Objects
Dec 21, 2021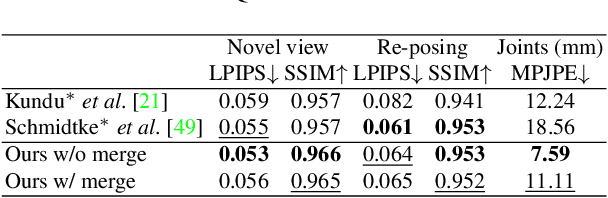
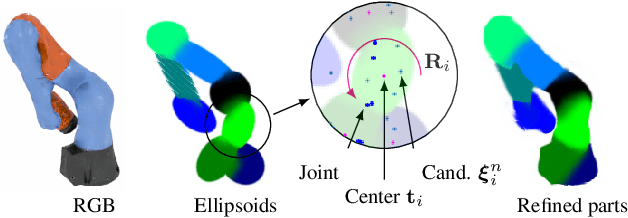
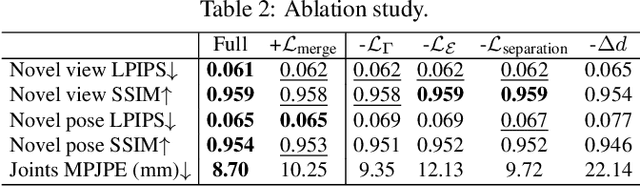
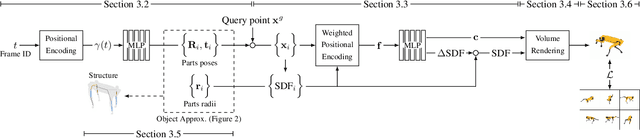
Rendering articulated objects while controlling their poses is critical to applications such as virtual reality or animation for movies. Manipulating the pose of an object, however, requires the understanding of its underlying structure, that is, its joints and how they interact with each other. Unfortunately, assuming the structure to be known, as existing methods do, precludes the ability to work on new object categories. We propose to learn both the appearance and the structure of previously unseen articulated objects by observing them move from multiple views, with no additional supervision, such as joints annotations, or information about the structure. Our insight is that adjacent parts that move relative to each other must be connected by a joint. To leverage this observation, we model the object parts in 3D as ellipsoids, which allows us to identify joints. We combine this explicit representation with an implicit one that compensates for the approximation introduced. We show that our method works for different structures, from quadrupeds, to single-arm robots, to humans.
Neural Articulated Radiance Field
Apr 07, 2021
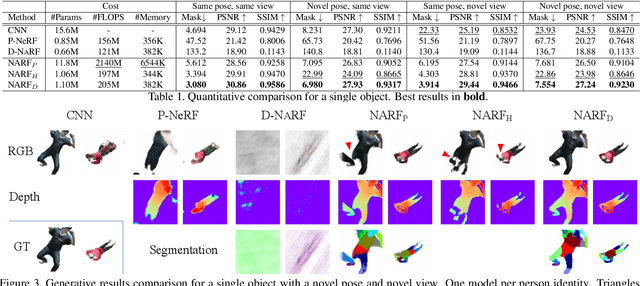
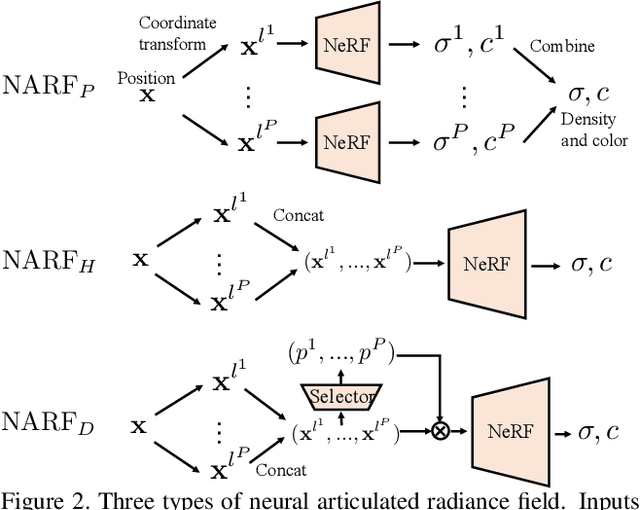
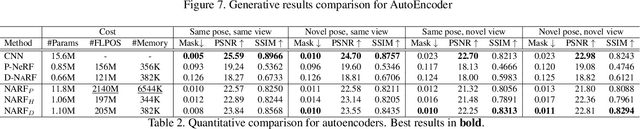
We present Neural Articulated Radiance Field (NARF), a novel deformable 3D representation for articulated objects learned from images. While recent advances in 3D implicit representation have made it possible to learn models of complex objects, learning pose-controllable representations of articulated objects remains a challenge, as current methods require 3D shape supervision and are unable to render appearance. In formulating an implicit representation of 3D articulated objects, our method considers only the rigid transformation of the most relevant object part in solving for the radiance field at each 3D location. In this way, the proposed method represents pose-dependent changes without significantly increasing the computational complexity. NARF is fully differentiable and can be trained from images with pose annotations. Moreover, through the use of an autoencoder, it can learn appearance variations over multiple instances of an object class. Experiments show that the proposed method is efficient and can generalize well to novel poses. We make the code, model and demo available for research purposes at https://github.com/nogu-atsu/NARF
RGBD-GAN: Unsupervised 3D Representation Learning From Natural Image Datasets via RGBD Image Synthesis
Sep 27, 2019
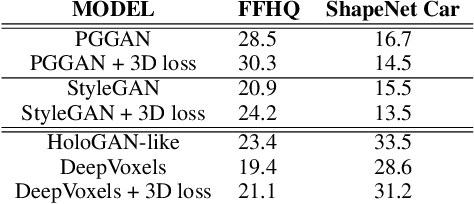
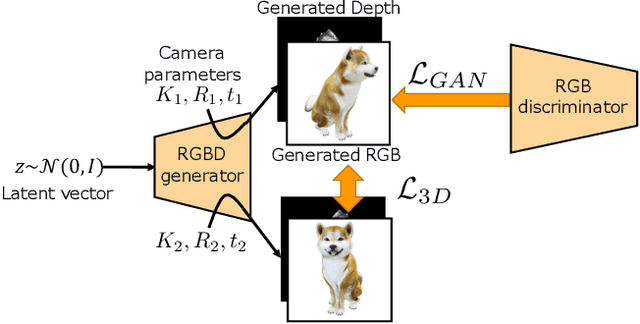
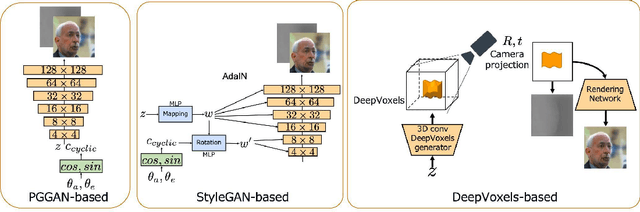
Understanding three-dimensional (3D) geometries from two-dimensional (2D) images without any labeled information is promising for understanding the real world without incurring annotation cost. We herein propose a novel generative model, RGBD-GAN, which achieves unsupervised 3D representation learning from 2D images. The proposed method enables camera parameter conditional image generation and depth image generation without any 3D annotations such as camera poses or depth. We used an explicit 3D consistency loss for two RGBD images generated from different camera parameters in addition to the ordinal GAN objective. The loss is simple yet effective for any type of image generator such as the DCGAN and StyleGAN to be conditioned on camera parameters. We conducted experiments and demonstrated that the proposed method could learn 3D representations from 2D images with various generator architectures.
Image Generation from Small Datasets via Batch Statistics Adaptation
Apr 22, 2019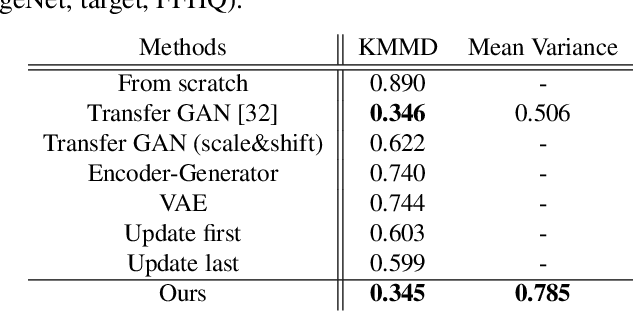

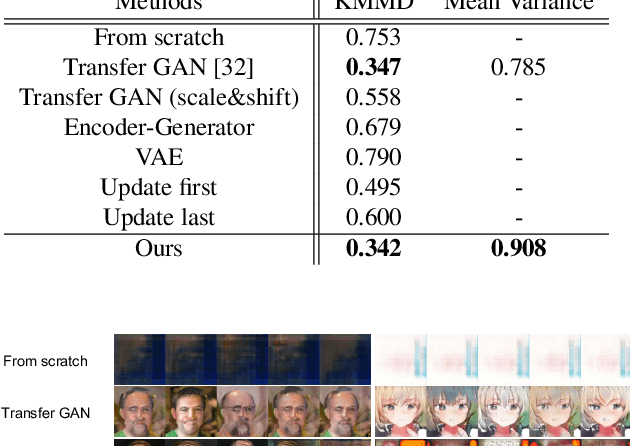

Thanks to the recent development of deep generative models, it is becoming possible to generate high-quality images with both fidelity and diversity. However, the training of such generative models requires a large dataset. To reduce the amount of data required, we propose a new method for transferring prior knowledge of the pre-trained generator, which is trained with a large dataset, to a small dataset in a different domain. Using such prior knowledge, the model can generate images leveraging some common sense that cannot be acquired from a small dataset. In this work, we propose a novel method focusing on the parameters for batch statistics, scale and shift, of the hidden layers in the generator. By training only these parameters in a supervised manner, we achieved stable training of the generator, and our method can generate higher quality images compared to previous methods without collapsing even when the dataset is small (~100). Our results show that the diversity of the filters acquired in the pre-trained generator is important for the performance on the target domain. By our method, it becomes possible to add a new class or domain to a pre-trained generator without disturbing the performance on the original domain.