 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Generation from Small Datasets via Batch Statistics Adaptation
Paper and Code
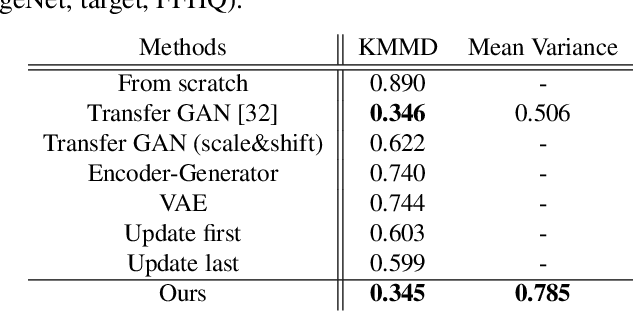

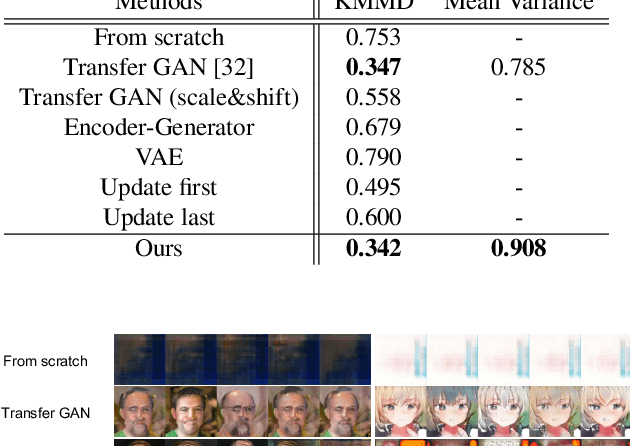

Thanks to the recent development of deep generative models, it is becoming possible to generate high-quality images with both fidelity and diversity. However, the training of such generative models requires a large dataset. To reduce the amount of data required, we propose a new method for transferring prior knowledge of the pre-trained generator, which is trained with a large dataset, to a small dataset in a different domain. Using such prior knowledge, the model can generate images leveraging some common sense that cannot be acquired from a small dataset. In this work, we propose a novel method focusing on the parameters for batch statistics, scale and shift, of the hidden layers in the generator. By training only these parameters in a supervised manner, we achieved stable training of the generator, and our method can generate higher quality images compared to previous methods without collapsing even when the dataset is small (~100). Our results show that the diversity of the filters acquired in the pre-trained generator is important for the performance on the target domain. By our method, it becomes possible to add a new class or domain to a pre-trained generator without disturbing the performance on the original domain.