 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Image-Adaptive Codebooks for Class-Agnostic Image Restoration
Jun 13, 2023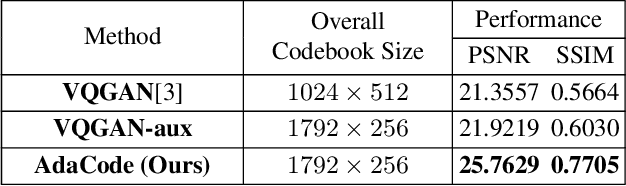
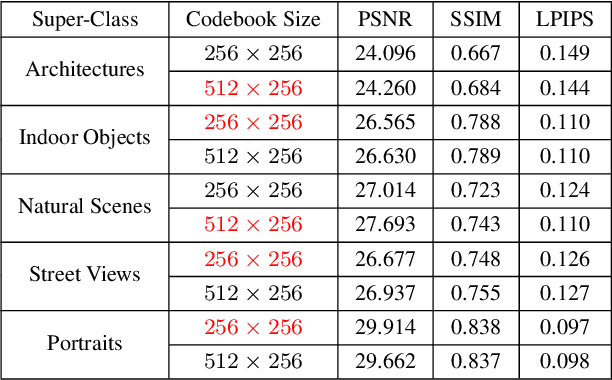
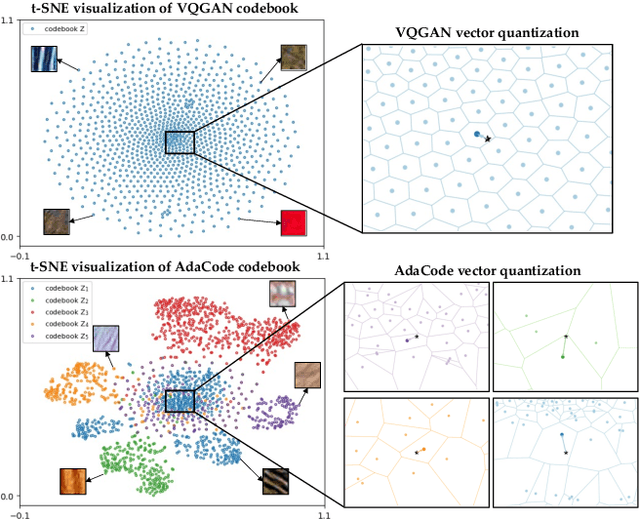
Recent work on discrete generative priors, in the form of codebooks, has shown exciting performance for image reconstruction and restoration, as the discrete prior space spanned by the codebooks increases the robustness against diverse image degradations. Nevertheless, these methods require separate training of codebooks for different image categories, which limits their use to specific image categories only (e.g. face, architecture, etc.), and fail to handle arbitrary natural images. In this paper, we propose AdaCode for learning image-adaptive codebooks for class-agnostic image restoration. Instead of learning a single codebook for each image category, we learn a set of basis codebooks. For a given input image, AdaCode learns a weight map with which we compute a weighted combination of these basis codebooks for adaptive image restoration. Intuitively, AdaCode is a more flexible and expressive discrete generative prior than previous work. Experimental results demonstrate that AdaCode achieves state-of-the-art performance on image reconstruction and restoration tasks, including image super-resolution and inpainting.
HDR Video Reconstruction with Tri-Exposure Quad-Bayer Sensors
Mar 19, 2021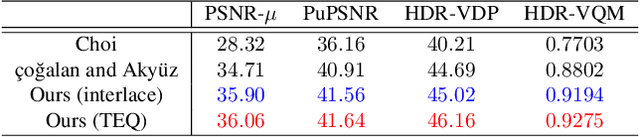
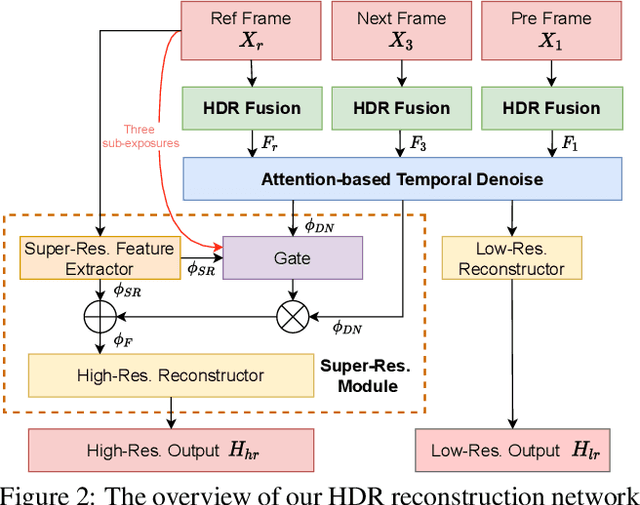
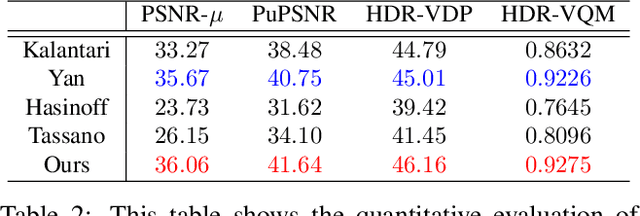
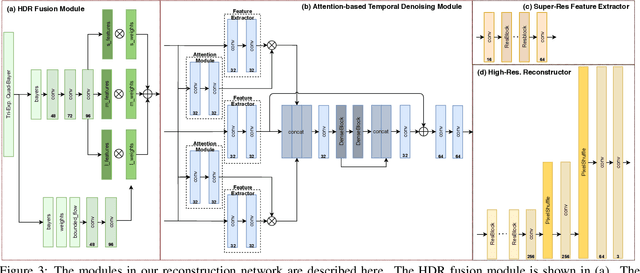
We propose a novel high dynamic range (HDR) video reconstruction method with new tri-exposure quad-bayer sensors. Thanks to the larger number of exposure sets and their spatially uniform deployment over a frame, they are more robust to noise and spatial artifacts than previous spatially varying exposure (SVE) HDR video methods. Nonetheless, the motion blur from longer exposures, the noise from short exposures, and inherent spatial artifacts of the SVE methods remain huge obstacles. Additionally, temporal coherence must be taken into account for the stability of video reconstruction. To tackle these challenges, we introduce a novel network architecture that divides-and-conquers these problems. In order to better adapt the network to the large dynamic range, we also propose LDR-reconstruction loss that takes equal contributions from both the highlighted and the shaded pixels of HDR frames. Through a series of comparisons and ablation studies, we show that the tri-exposure quad-bayer with our solution is more optimal to capture than previous reconstruction methods, particularly for the scenes with larger dynamic range and objects with motion.
Extreme View Synthesis
Dec 12, 2018
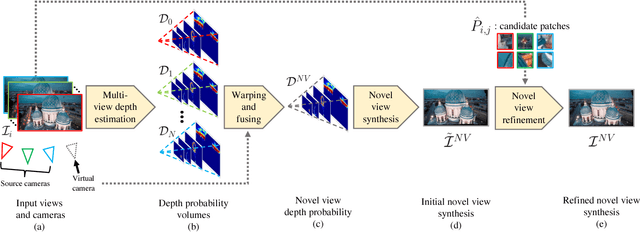

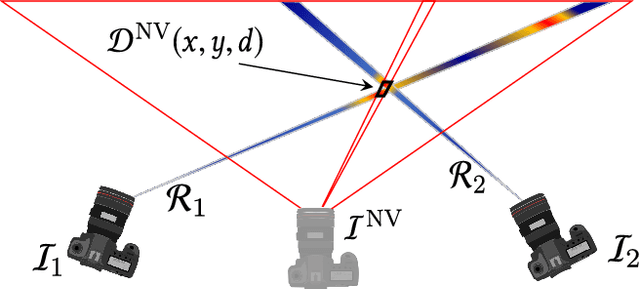
We present Extreme View Synthesis, a solution for novel view extrapolation when the number of input images is small. Occlusions and depth uncertainty, in this context, are two of the most pressing issues, and worsen as the degree of extrapolation increases. State-of-the-art methods approach this problem by leveraging explicit geometric constraints, or learned priors. Our key insight is that only by modeling both depth uncertainty and image priors can the extreme cases be solved. We first generate a depth probability volume for the novel view and synthesize an estimate of the sought image. Then, we use learned priors combined with depth uncertainty, to refine it. Our method is the first to show visually pleasing results for baseline magnifications of up to 30X.