 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoDIR: Automatic All-in-One Image Restoration with Latent Diffusion
Oct 17, 2023In this paper, we aim to solve complex real-world image restoration situations, in which, one image may have a variety of unknown degradations. To this end, we propose an all-in-one image restoration framework with latent diffusion (AutoDIR), which can automatically detect and address multiple unknown degradations. Our framework first utilizes a Blind Image Quality Assessment Module (BIQA) to automatically detect and identify the unknown dominant image degradation type of the image. Then, an All-in-One Image Refinement (AIR) Module handles multiple kinds of degradation image restoration with the guidance of BIQA. Finally, a Structure Correction Module (SCM) is proposed to recover the image details distorted by AIR. Our comprehensive evaluation demonstrates that AutoDIR outperforms state-of-the-art approaches by achieving superior restoration results while supporting a wider range of tasks. Notably, AutoDIR is also the first method to automatically handle real-scenario images with multiple unknown degradations.
Learning Image-Adaptive Codebooks for Class-Agnostic Image Restoration
Jun 13, 2023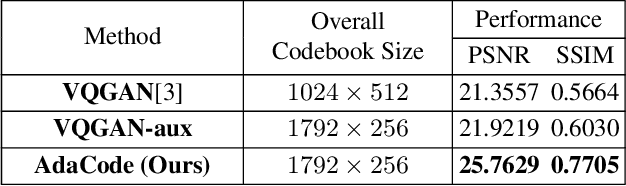
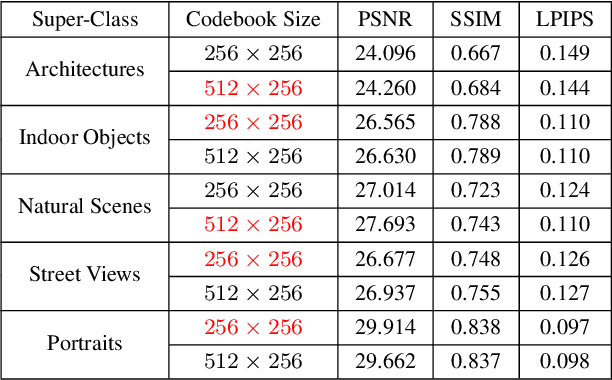
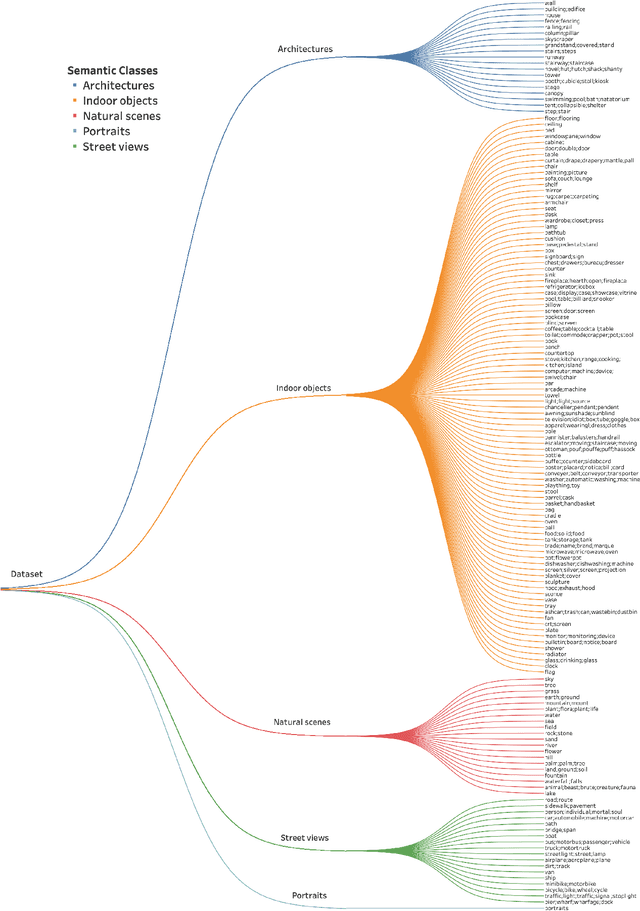
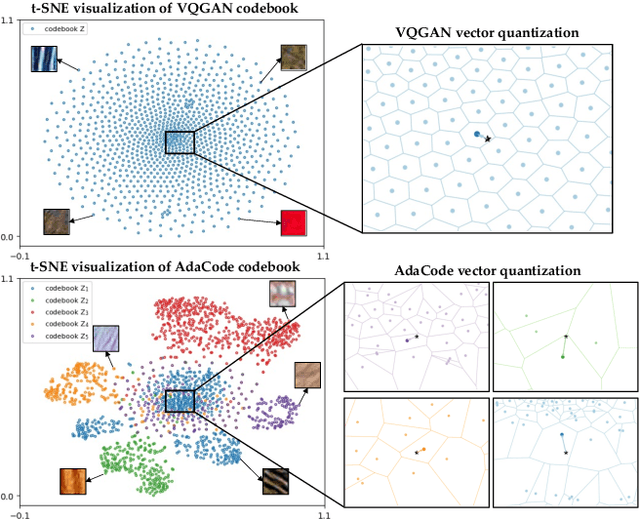
Recent work on discrete generative priors, in the form of codebooks, has shown exciting performance for image reconstruction and restoration, as the discrete prior space spanned by the codebooks increases the robustness against diverse image degradations. Nevertheless, these methods require separate training of codebooks for different image categories, which limits their use to specific image categories only (e.g. face, architecture, etc.), and fail to handle arbitrary natural images. In this paper, we propose AdaCode for learning image-adaptive codebooks for class-agnostic image restoration. Instead of learning a single codebook for each image category, we learn a set of basis codebooks. For a given input image, AdaCode learns a weight map with which we compute a weighted combination of these basis codebooks for adaptive image restoration. Intuitively, AdaCode is a more flexible and expressive discrete generative prior than previous work. Experimental results demonstrate that AdaCode achieves state-of-the-art performance on image reconstruction and restoration tasks, including image super-resolution and inpainting.
Real-time Controllable Denoising for Image and Video
Mar 29, 2023Controllable image denoising aims to generate clean samples with human perceptual priors and balance sharpness and smoothness. In traditional filter-based denoising methods, this can be easily achieved by adjusting the filtering strength. However, for NN (Neural Network)-based models, adjusting the final denoising strength requires performing network inference each time, making it almost impossible for real-time user interaction. In this paper, we introduce Real-time Controllable Denoising (RCD), the first deep image and video denoising pipeline that provides a fully controllable user interface to edit arbitrary denoising levels in real-time with only one-time network inference. Unlike existing controllable denoising methods that require multiple denoisers and training stages, RCD replaces the last output layer (which usually outputs a single noise map) of an existing CNN-based model with a lightweight module that outputs multiple noise maps. We propose a novel Noise Decorrelation process to enforce the orthogonality of the noise feature maps, allowing arbitrary noise level control through noise map interpolation. This process is network-free and does not require network inference. Our experiments show that RCD can enable real-time editable image and video denoising for various existing heavy-weight models without sacrificing their original performance.
HDR Video Reconstruction with Tri-Exposure Quad-Bayer Sensors
Mar 19, 2021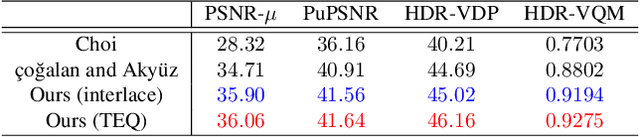
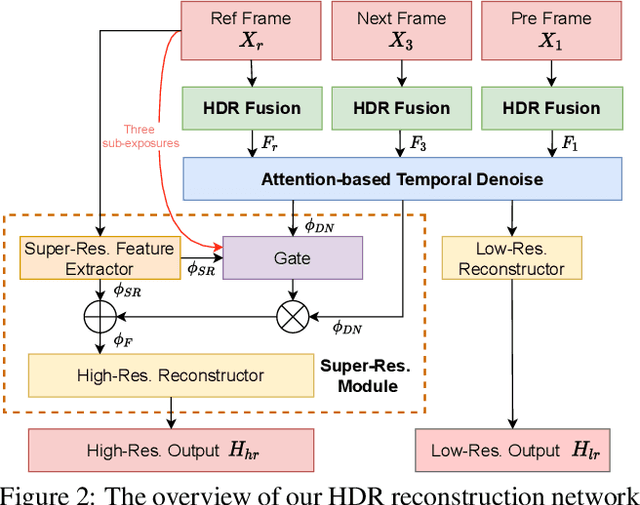
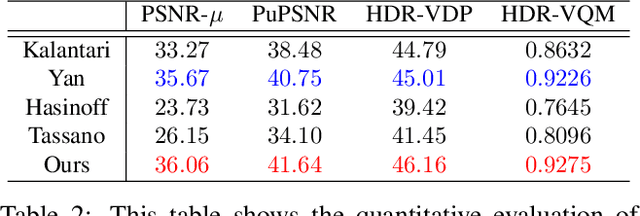
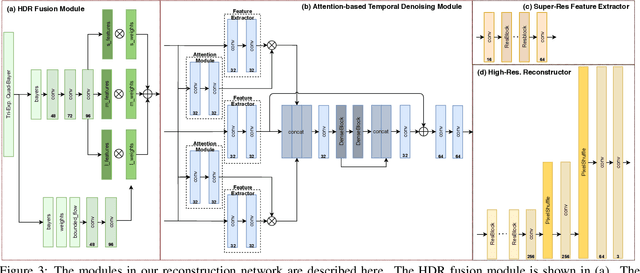
We propose a novel high dynamic range (HDR) video reconstruction method with new tri-exposure quad-bayer sensors. Thanks to the larger number of exposure sets and their spatially uniform deployment over a frame, they are more robust to noise and spatial artifacts than previous spatially varying exposure (SVE) HDR video methods. Nonetheless, the motion blur from longer exposures, the noise from short exposures, and inherent spatial artifacts of the SVE methods remain huge obstacles. Additionally, temporal coherence must be taken into account for the stability of video reconstruction. To tackle these challenges, we introduce a novel network architecture that divides-and-conquers these problems. In order to better adapt the network to the large dynamic range, we also propose LDR-reconstruction loss that takes equal contributions from both the highlighted and the shaded pixels of HDR frames. Through a series of comparisons and ablation studies, we show that the tri-exposure quad-bayer with our solution is more optimal to capture than previous reconstruction methods, particularly for the scenes with larger dynamic range and objects with motion.
Revisiting Shadow Detection: A New Benchmark Dataset for Complex World
Nov 16, 2019
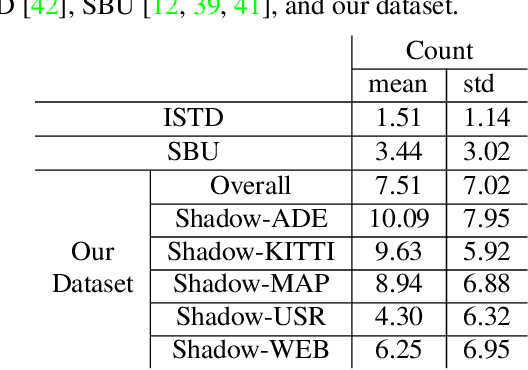


Shadow detection in general photos is a nontrivial problem, due to the complexity of the real world. Though recent shadow detectors have already achieved remarkable performance on various benchmark data, their performance is still limited for general real-world situations. In this work, we collected shadow images for multiple scenarios and compiled a new dataset of 10,500 shadow images, each with labeled ground-truth mask, for supporting shadow detection in the complex world. Our dataset covers a rich variety of scene categories, with diverse shadow sizes, locations, contrasts, and types. Further, we comprehensively analyze the complexity of the dataset, present a fast shadow detection network with a detail enhancement module to harvest shadow details, and demonstrate the effectiveness of our method to detect shadows in general situations.
Mask-ShadowGAN: Learning to Remove Shadows from Unpaired Data
Mar 26, 2019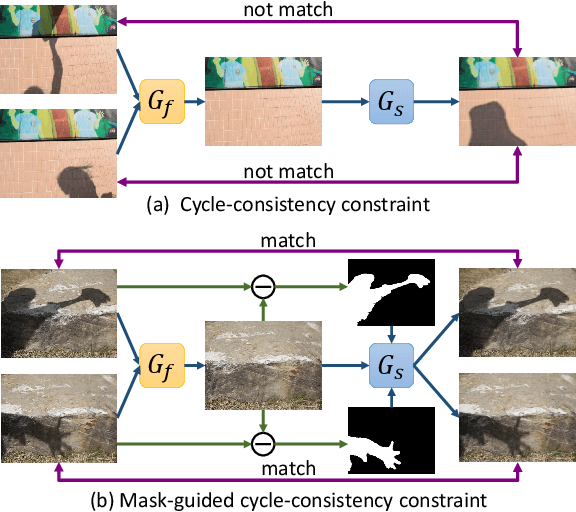
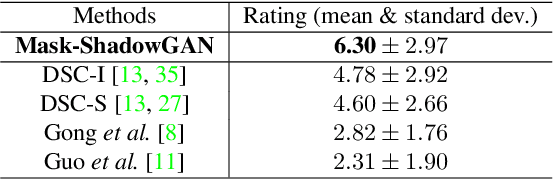
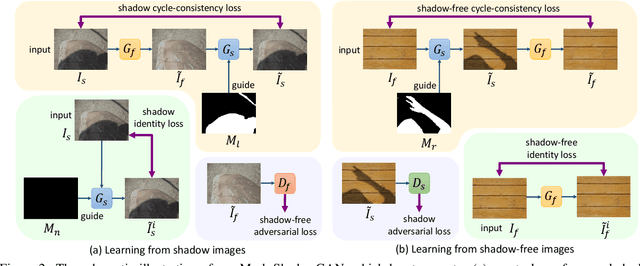
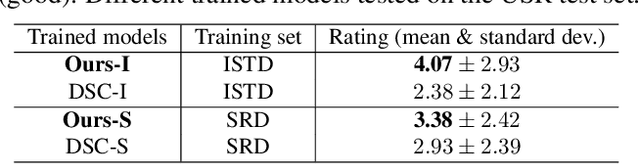
This paper presents a new method for shadow removal using unpaired data, enabling us to avoid tedious annotations and obtain more diverse training samples. However, directly employing adversarial learning and cycle-consistency constraints is insufficient to learn the underlying relationship between the shadow and shadow-free domains, since the mapping between shadow and shadow-free images is not simply one-to-one. To address the problem, we formulate Mask-ShadowGAN, a new deep framework that automatically learns to produce a shadow mask from the input shadow image and then takes the mask to guide the shadow generation via re-formulated cycle-consistency constraints. Particularly, the framework simultaneously learns to produce shadow masks and learns to remove shadows, to maximize the overall performance. Also, we prepared an unpaired dataset for shadow removal and demonstrated the effectiveness of Mask-ShadowGAN on various experiments, even it was trained on unpaired data.