 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporally Consistent HDR Indoor Lighting Estimation
Paper and Code
May 07, 2023
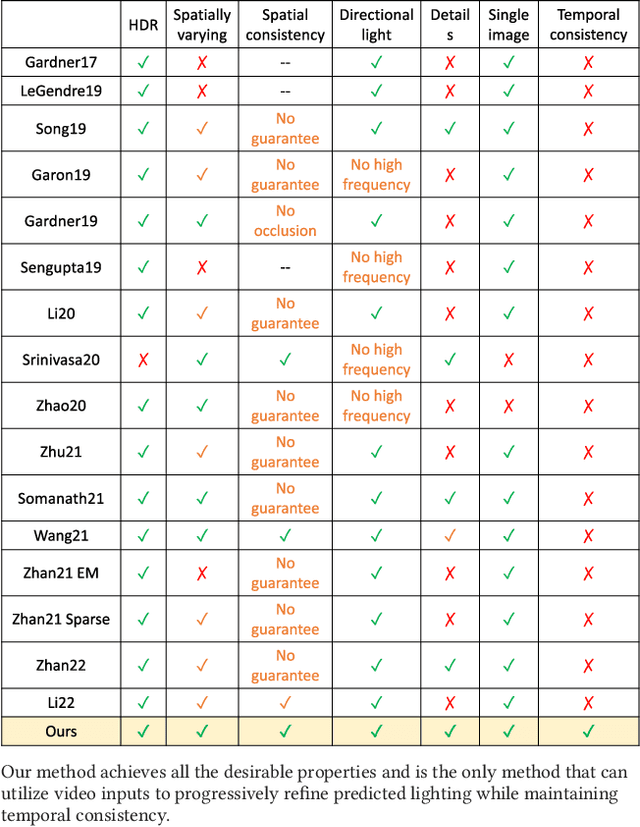
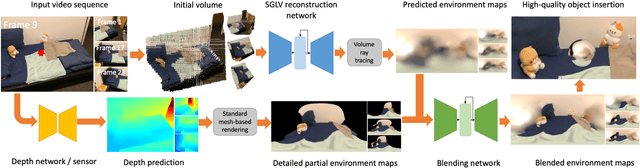
We propose a physically-motivated deep learning framework to solve a general version of the challenging indoor lighting estimation problem. Given a single LDR image with a depth map, our method predicts spatially consistent lighting at any given image position. Particularly, when the input is an LDR video sequence, our framework not only progressively refines the lighting prediction as it sees more regions, but also preserves temporal consistency by keeping the refinement smooth. Our framework reconstructs a spherical Gaussian lighting volume (SGLV) through a tailored 3D encoder-decoder, which enables spatially consistent lighting prediction through volume ray tracing, a hybrid blending network for detailed environment maps, an in-network Monte-Carlo rendering layer to enhance photorealism for virtual object insertion, and recurrent neural networks (RNN) to achieve temporally consistent lighting prediction with a video sequence as the input. For training, we significantly enhance the OpenRooms public dataset of photorealistic synthetic indoor scenes with around 360K HDR environment maps of much higher resolution and 38K video sequences, rendered with GPU-based path tracing. Experiments show that our framework achieves lighting prediction with higher quality compared to state-of-the-art single-image or video-based methods, leading to photorealistic AR applications such as object insertion.