 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearching for Optimal Subword Tokenization in Cross-domain NER
Jun 07, 2022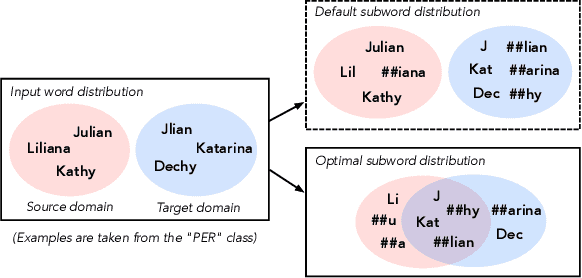

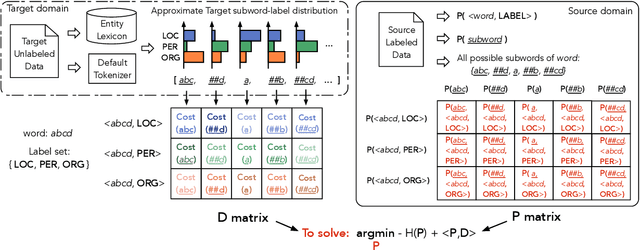
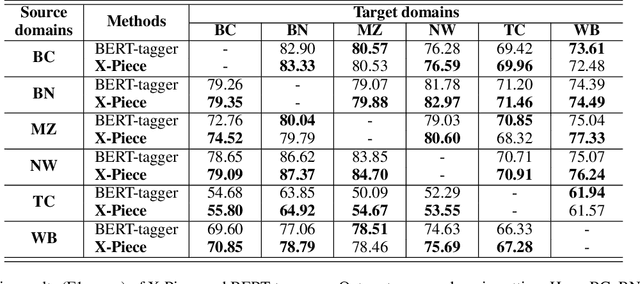
Input distribution shift is one of the vital problems in unsupervised domain adaptation (UDA). The most popular UDA approaches focus on domain-invariant representation learning, trying to align the features from different domains into similar feature distributions. However, these approaches ignore the direct alignment of input word distributions between domains, which is a vital factor in word-level classification tasks such as cross-domain NER. In this work, we shed new light on cross-domain NER by introducing a subword-level solution, X-Piece, for input word-level distribution shift in NER. Specifically, we re-tokenize the input words of the source domain to approach the target subword distribution, which is formulated and solved as an optimal transport problem. As this approach focuses on the input level, it can also be combined with previous DIRL methods for further improvement. Experimental results show the effectiveness of the proposed method based on BERT-tagger on four benchmark NER datasets. Also, the proposed method is proved to benefit DIRL methods such as DANN.
Plug-Tagger: A Pluggable Sequence Labeling Framework Using Language Models
Oct 14, 2021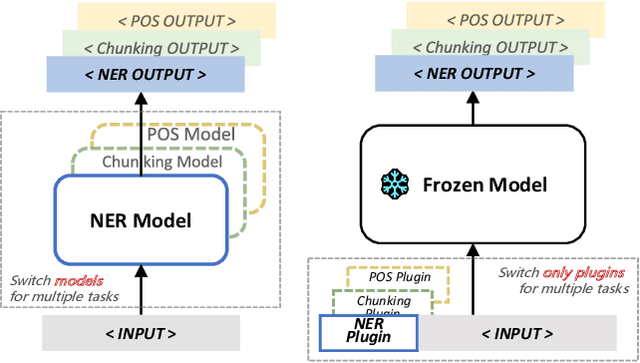

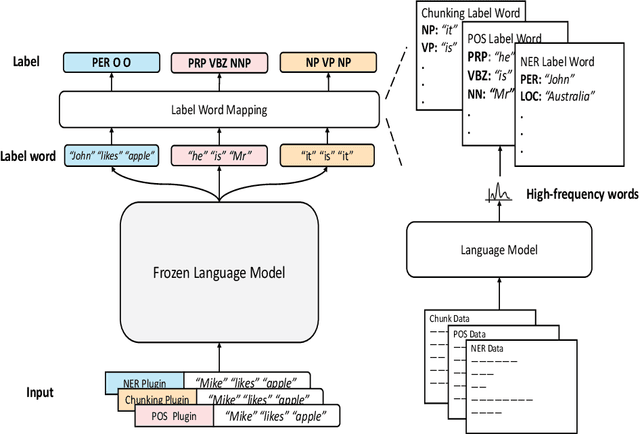

Plug-and-play functionality allows deep learning models to adapt well to different tasks without requiring any parameters modified. Recently, prefix-tuning was shown to be a plug-and-play method on various text generation tasks by simply inserting corresponding continuous vectors into the inputs. However, sequence labeling tasks invalidate existing plug-and-play methods since different label sets demand changes to the architecture of the model classifier. In this work, we propose the use of label word prediction instead of classification to totally reuse the architecture of pre-trained models for sequence labeling tasks. Specifically, for each task, a label word set is first constructed by selecting a high-frequency word for each class respectively, and then, task-specific vectors are inserted into the inputs and optimized to manipulate the model predictions towards the corresponding label words. As a result, by simply switching the plugin vectors on the input, a frozen pre-trained language model is allowed to perform different tasks. Experimental results on three sequence labeling tasks show that the performance of the proposed method can achieve comparable performance with standard fine-tuning with only 0.1\% task-specific parameters. In addition, our method is up to 70 times faster than non-plug-and-play methods while switching different tasks under the resource-constrained scenario.
Template-free Prompt Tuning for Few-shot NER
Sep 28, 2021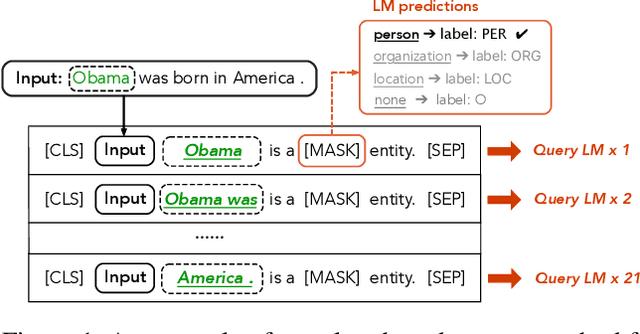
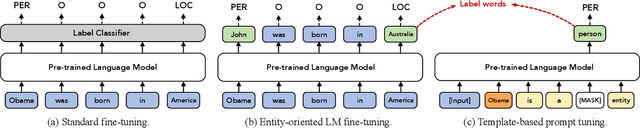
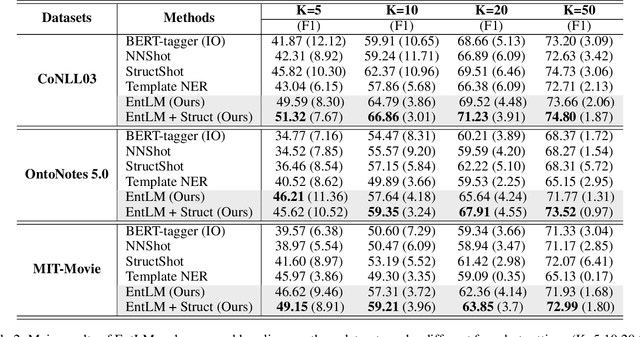
Prompt-based methods have been successfully applied in sentence-level few-shot learning tasks, mostly owing to the sophisticated design of templates and label words. However, when applied to token-level labeling tasks such as NER, it would be time-consuming to enumerate the template queries over all potential entity spans. In this work, we propose a more elegant method to reformulate NER tasks as LM problems without any templates. Specifically, we discard the template construction process while maintaining the word prediction paradigm of pre-training models to predict a class-related pivot word (or label word) at the entity position. Meanwhile, we also explore principled ways to automatically search for appropriate label words that the pre-trained models can easily adapt to. While avoiding complicated template-based process, the proposed LM objective also reduces the gap between different objectives used in pre-training and fine-tuning, thus it can better benefit the few-shot performance. Experimental results demonstrate the effectiveness of the proposed method over bert-tagger and template-based method under few-shot setting. Moreover, the decoding speed of the proposed method is up to 1930.12 times faster than the template-based method.
TextFlint: Unified Multilingual Robustness Evaluation Toolkit for Natural Language Processing
Apr 06, 2021



Various robustness evaluation methodologies from different perspectives have been proposed for different natural language processing (NLP) tasks. These methods have often focused on either universal or task-specific generalization capabilities. In this work, we propose a multilingual robustness evaluation platform for NLP tasks (TextFlint) that incorporates universal text transformation, task-specific transformation, adversarial attack, subpopulation, and their combinations to provide comprehensive robustness analysis. TextFlint enables practitioners to automatically evaluate their models from all aspects or to customize their evaluations as desired with just a few lines of code. To guarantee user acceptability, all the text transformations are linguistically based, and we provide a human evaluation for each one. TextFlint generates complete analytical reports as well as targeted augmented data to address the shortcomings of the model's robustness. To validate TextFlint's utility, we performed large-scale empirical evaluations (over 67,000 evaluations) on state-of-the-art deep learning models, classic supervised methods, and real-world systems. Almost all models showed significant performance degradation, including a decline of more than 50% of BERT's prediction accuracy on tasks such as aspect-level sentiment classification, named entity recognition, and natural language inference. Therefore, we call for the robustness to be included in the model evaluation, so as to promote the healthy development of NLP technology.