 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-aware Ensemble of Multifaceted Factorization Models for Recommendation Prediction in Social Networks
May 03, 2021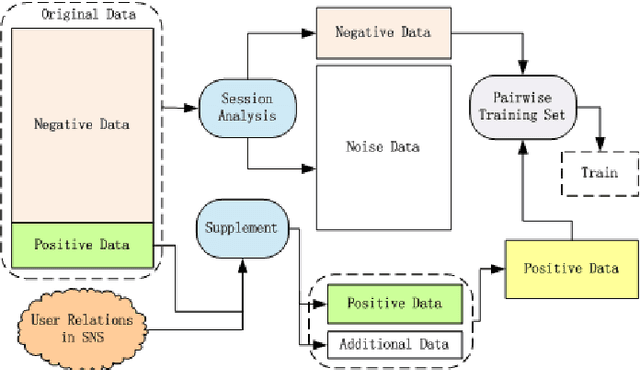
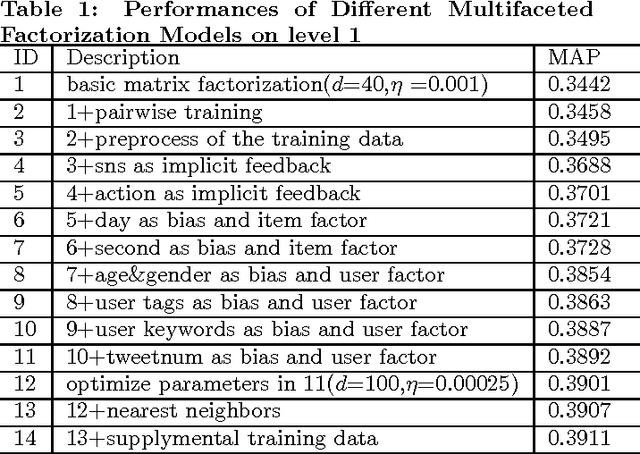
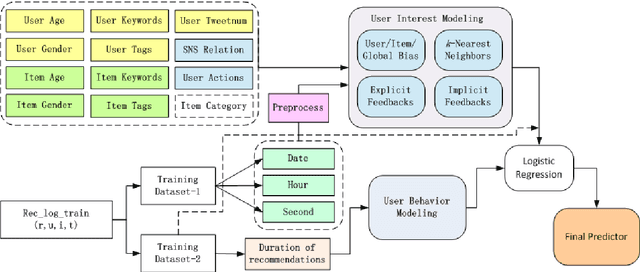

This paper describes the solution of Shanda Innovations team to Task 1 of KDD-Cup 2012. A novel approach called Multifaceted Factorization Models is proposed to incorporate a great variety of features in social networks. Social relationships and actions between users are integrated as implicit feedbacks to improve the recommendation accuracy. Keywords, tags, profiles, time and some other features are also utilized for modeling user interests. In addition, user behaviors are modeled from the durations of recommendation records. A context-aware ensemble framework is then applied to combine multiple predictors and produce final recommendation results. The proposed approach obtained 0.43959 (public score) / 0.41874 (private score) on the testing dataset, which achieved the 2nd place in the KDD-Cup competition.
Learning Better Internal Structure of Words for Sequence Labeling
Oct 29, 2018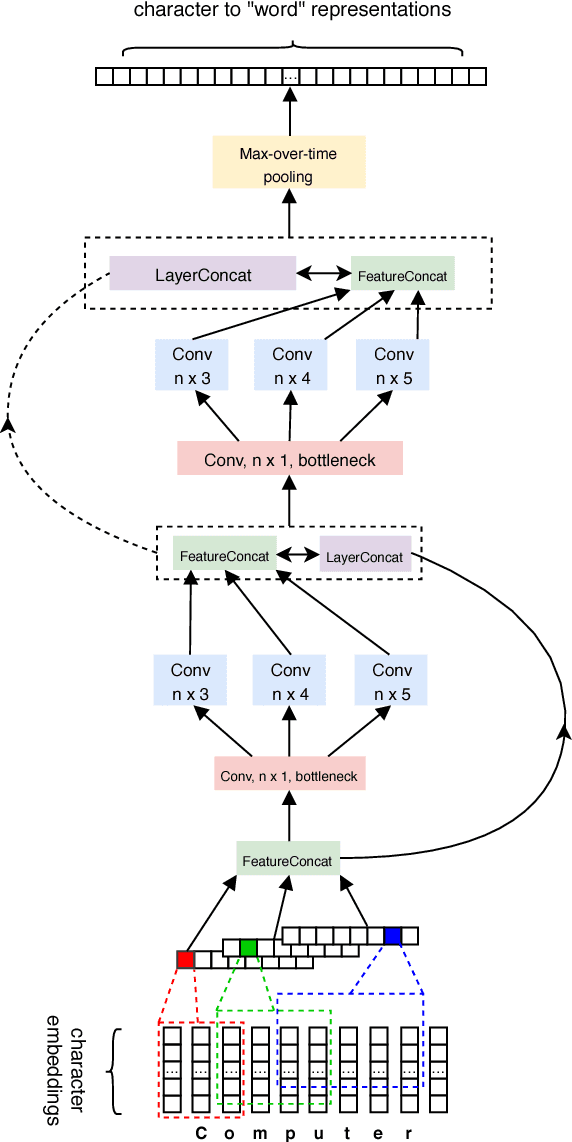
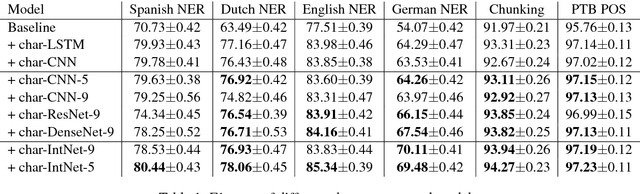
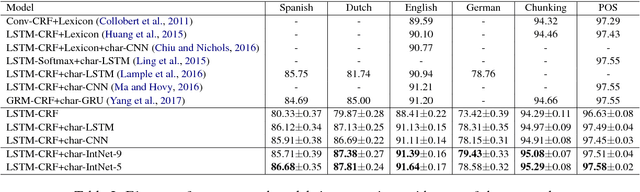

Character-based neural models have recently proven very useful for many NLP tasks. However, there is a gap of sophistication between methods for learning representations of sentences and words. While most character models for learning representations of sentences are deep and complex, models for learning representations of words are shallow and simple. Also, in spite of considerable research on learning character embeddings, it is still not clear which kind of architecture is the best for capturing character-to-word representations. To address these questions, we first investigate the gaps between methods for learning word and sentence representations. We conduct detailed experiments and comparisons of different state-of-the-art convolutional models, and also investigate the advantages and disadvantages of their constituents. Furthermore, we propose IntNet, a funnel-shaped wide convolutional neural architecture with no down-sampling for learning representations of the internal structure of words by composing their characters from limited, supervised training corpora. We evaluate our proposed model on six sequence labeling datasets, including named entity recognition, part-of-speech tagging, and syntactic chunking. Our in-depth analysis shows that IntNet significantly outperforms other character embedding models and obtains new state-of-the-art performance without relying on any external knowledge or resources.