 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComfySearch: Autonomous Exploration and Reasoning for ComfyUI Workflows
Jan 07, 2026AI-generated content has progressed from monolithic models to modular workflows, especially on platforms like ComfyUI, allowing users to customize complex creative pipelines. However, the large number of components in ComfyUI and the difficulty of maintaining long-horizon structural consistency under strict graph constraints frequently lead to low pass rates and workflows of limited quality. To tackle these limitations, we present ComfySearch, an agentic framework that can effectively explore the component space and generate functional ComfyUI pipelines via validation-guided workflow construction. Experiments demonstrate that ComfySearch substantially outperforms existing methods on complex and creative tasks, achieving higher executability (pass) rates, higher solution rates, and stronger generalization.
DebFlow: Automating Agent Creation via Agent Debate
Mar 31, 2025
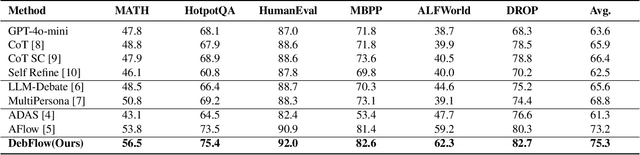
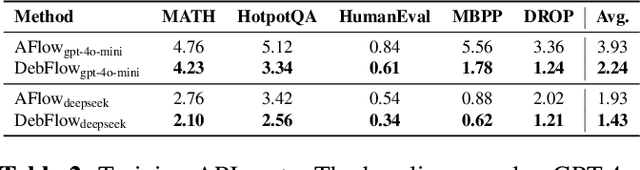
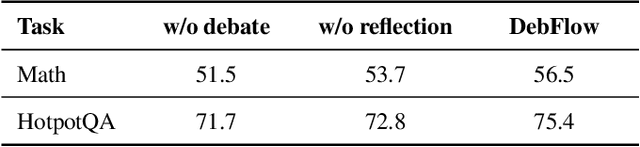
Large language models (LLMs) have demonstrated strong potential and impressive performance in automating the generation and optimization of workflows. However, existing approaches are marked by limited reasoning capabilities, high computational demands, and significant resource requirements. To address these issues, we propose DebFlow, a framework that employs a debate mechanism to optimize workflows and integrates reflexion to improve based on previous experiences. We evaluated our method across six benchmark datasets, including HotpotQA, MATH, and ALFWorld. Our approach achieved a 3\% average performance improvement over the latest baselines, demonstrating its effectiveness in diverse problem domains. In particular, during training, our framework reduces resource consumption by 37\% compared to the state-of-the-art baselines. Additionally, we performed ablation studies. Removing the Debate component resulted in a 4\% performance drop across two benchmark datasets, significantly greater than the 2\% drop observed when the Reflection component was removed. These findings strongly demonstrate the critical role of Debate in enhancing framework performance, while also highlighting the auxiliary contribution of reflexion to overall optimization.
MARS: Memory-Enhanced Agents with Reflective Self-improvement
Mar 25, 2025Large language models (LLMs) have made significant advances in the field of natural language processing, but they still face challenges such as continuous decision-making, lack of long-term memory, and limited context windows in dynamic environments. To address these issues, this paper proposes an innovative framework Memory-Enhanced Agents with Reflective Self-improvement. The MARS framework comprises three agents: the User, the Assistant, and the Checker. By integrating iterative feedback, reflective mechanisms, and a memory optimization mechanism based on the Ebbinghaus forgetting curve, it significantly enhances the agents capabilities in handling multi-tasking and long-span information.
Self-evolving Agents with reflective and memory-augmented abilities
Sep 01, 2024Large language models (LLMs) have made significant advances in the field of natural language processing, but they still face challenges such as continuous decision-making. In this research, we propose a novel framework by integrating iterative feedback, reflective mechanisms, and a memory optimization mechanism based on the Ebbinghaus forgetting curve, it significantly enhances the agents' capabilities in handling multi-tasking and long-span information.
LanguaShrink: Reducing Token Overhead with Psycholinguistics
Sep 01, 2024As large language models (LLMs) improve their capabilities in handling complex tasks, the issues of computational cost and efficiency due to long prompts are becoming increasingly prominent. To accelerate model inference and reduce costs, we propose an innovative prompt compression framework called LanguaShrink. Inspired by the observation that LLM performance depends on the density and position of key information in the input prompts, LanguaShrink leverages psycholinguistic principles and the Ebbinghaus memory curve to achieve task-agnostic prompt compression. This effectively reduces prompt length while preserving essential information. We referred to the training method of OpenChat.The framework introduces part-of-speech priority compression and data distillation techniques, using smaller models to learn compression targets and employing a KL-regularized reinforcement learning strategy for training.\cite{wang2023openchat} Additionally, we adopt a chunk-based compression algorithm to achieve adjustable compression rates. We evaluate our method on multiple datasets, including LongBench, ZeroScrolls, Arxiv Articles, and a newly constructed novel test set. Experimental results show that LanguaShrink maintains semantic similarity while achieving up to 26 times compression. Compared to existing prompt compression methods, LanguaShrink improves end-to-end latency by 1.43 times.
AICoderEval: Improving AI Domain Code Generation of Large Language Models
Jun 07, 2024Automated code generation is a pivotal capability of large language models (LLMs). However, assessing this capability in real-world scenarios remains challenging. Previous methods focus more on low-level code generation, such as model loading, instead of generating high-level codes catering for real-world tasks, such as image-to-text, text classification, in various domains. Therefore, we construct AICoderEval, a dataset focused on real-world tasks in various domains based on HuggingFace, PyTorch, and TensorFlow, along with comprehensive metrics for evaluation and enhancing LLMs' task-specific code generation capability. AICoderEval contains test cases and complete programs for automated evaluation of these tasks, covering domains such as natural language processing, computer vision, and multimodal learning. To facilitate research in this area, we open-source the AICoderEval dataset at \url{https://huggingface.co/datasets/vixuowis/AICoderEval}. After that, we propose CoderGen, an agent-based framework, to help LLMs generate codes related to real-world tasks on the constructed AICoderEval. Moreover, we train a more powerful task-specific code generation model, named AICoder, which is refined on llama-3 based on AICoderEval. Our experiments demonstrate the effectiveness of CoderGen in improving LLMs' task-specific code generation capability (by 12.00\% on pass@1 for original model and 9.50\% on pass@1 for ReAct Agent). AICoder also outperforms current code generation LLMs, indicating the great quality of the AICoderEval benchmark.