 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARS: Memory-Enhanced Agents with Reflective Self-improvement
Mar 25, 2025Large language models (LLMs) have made significant advances in the field of natural language processing, but they still face challenges such as continuous decision-making, lack of long-term memory, and limited context windows in dynamic environments. To address these issues, this paper proposes an innovative framework Memory-Enhanced Agents with Reflective Self-improvement. The MARS framework comprises three agents: the User, the Assistant, and the Checker. By integrating iterative feedback, reflective mechanisms, and a memory optimization mechanism based on the Ebbinghaus forgetting curve, it significantly enhances the agents capabilities in handling multi-tasking and long-span information.
Research on the Offshore Marine Communication Environment Based on Satellite Remote Sensing Data
Feb 19, 2025Air-sea interface fluxes significantly impact the reliability and efficiency of maritime communication. Compared to sparse in-situ ocean observations, satellite remote sensing data offers broader coverage and extended temporal span. This study utilizes COARE V3.5 algorithm to calculate momentum flux, sensible heat flux, and latent heat flux at the air-sea interface, based on satellite synthetic aperture radar (SAR) wind speed data, reanalysis data, and buoy measurements, combined with neural network methods. Findings indicate that SAR wind speed data corrected via neural networks show improved consistency with buoy-measured wind speeds in flux calculations. Specifically, the bias in friction velocity decreased from -0.03 m/s to 0.01 m/s, wind stress bias from -0.03 N/m^2 to 0.00 N/m^2, drag coefficient bias from -0.29 to -0.21, latent heat flux bias from -8.32 W/m^2 to 5.41 W/m^2, and sensible heat flux bias from 0.67 W/m^2 to 0.06 W/m^2. Results suggest that the neural network-corrected SAR wind speed data can provide more reliable environmental data for maritime communication.
M3PT: A Multi-Modal Model for POI Tagging
Jun 16, 2023POI tagging aims to annotate a point of interest (POI) with some informative tags, which facilitates many services related to POIs, including search, recommendation, and so on. Most of the existing solutions neglect the significance of POI images and seldom fuse the textual and visual features of POIs, resulting in suboptimal tagging performance. In this paper, we propose a novel Multi-Modal Model for POI Tagging, namely M3PT, which achieves enhanced POI tagging through fusing the target POI's textual and visual features, and the precise matching between the multi-modal representations. Specifically, we first devise a domain-adaptive image encoder (DIE) to obtain the image embeddings aligned to their gold tags' semantics. Then, in M3PT's text-image fusion module (TIF), the textual and visual representations are fully fused into the POIs' content embeddings for the subsequent matching. In addition, we adopt a contrastive learning strategy to further bridge the gap between the representations of different modalities. To evaluate the tagging models' performance, we have constructed two high-quality POI tagging datasets from the real-world business scenario of Ali Fliggy. Upon the datasets, we conducted the extensive experiments to demonstrate our model's advantage over the baselines of uni-modality and multi-modality, and verify the effectiveness of important components in M3PT, including DIE, TIF and the contrastive learning strategy.
A Robotic Auto-Focus System based on Deep Reinforcement Learning
Sep 05, 2018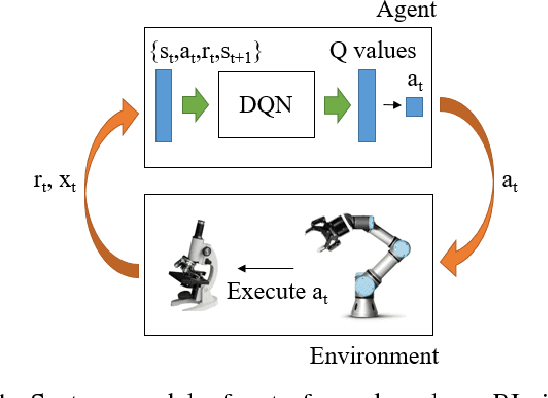



Considering its advantages in dealing with high-dimensional visual input and learning control policies in discrete domain, Deep Q Network (DQN) could be an alternative method of traditional auto-focus means in the future. In this paper, based on Deep Reinforcement Learning, we propose an end-to-end approach that can learn auto-focus policies from visual input and finish at a clear spot automatically. We demonstrate that our method - discretizing the action space with coarse to fine steps and applying DQN is not only a solution to auto-focus but also a general approach towards vision-based control problems. Separate phases of training in virtual and real environments are applied to obtain an effective model. Virtual experiments, which are carried out after the virtual training phase, indicates that our method could achieve 100% accuracy on a certain view with different focus range. Further training on real robots could eliminate the deviation between the simulator and real scenario, leading to reliable performances in real applications.