 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale Multi-sequence Pretraining for Generalizable MRI Analysis in Versatile Clinical Applications
Aug 10, 2025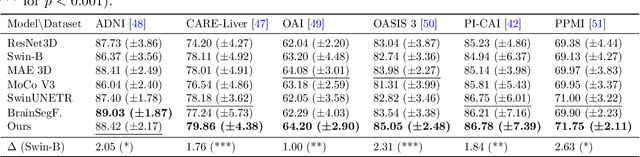
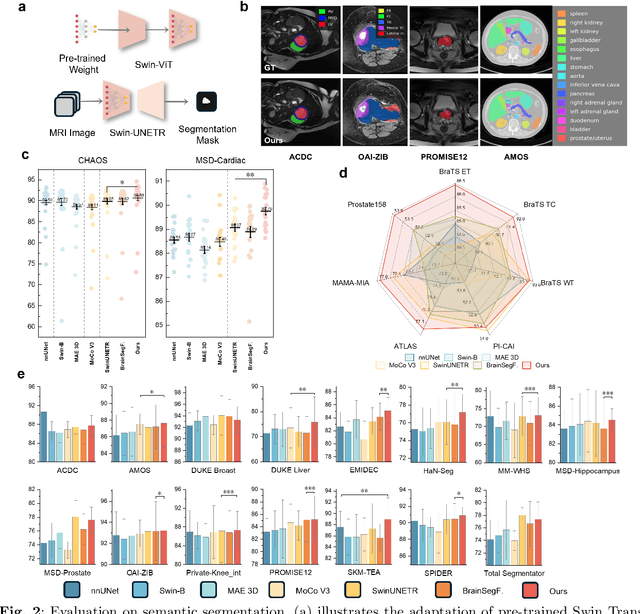
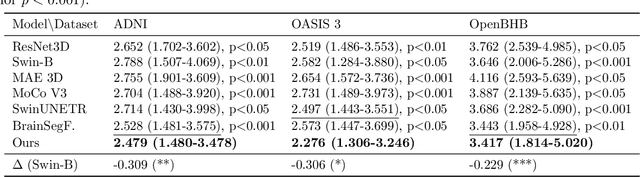
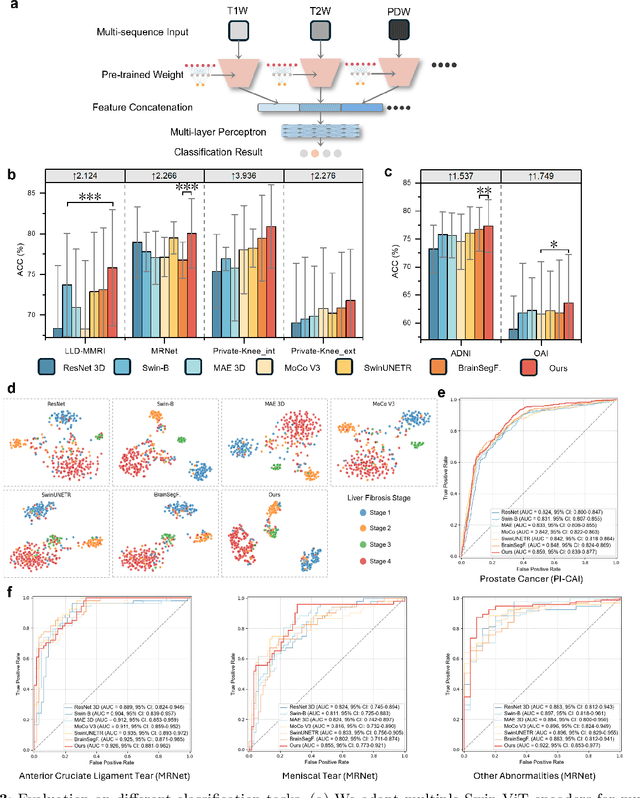
Multi-sequence Magnetic Resonance Imaging (MRI) offers remarkable versatility, enabling the distinct visualization of different tissue types. Nevertheless, the inherent heterogeneity among MRI sequences poses significant challenges to the generalization capability of deep learning models. These challenges undermine model performance when faced with varying acquisition parameters, thereby severely restricting their clinical utility. In this study, we present PRISM, a foundation model PRe-trained with large-scale multI-Sequence MRI. We collected a total of 64 datasets from both public and private sources, encompassing a wide range of whole-body anatomical structures, with scans spanning diverse MRI sequences. Among them, 336,476 volumetric MRI scans from 34 datasets (8 public and 26 private) were curated to construct the largest multi-organ multi-sequence MRI pretraining corpus to date. We propose a novel pretraining paradigm that disentangles anatomically invariant features from sequence-specific variations in MRI, while preserving high-level semantic representations. We established a benchmark comprising 44 downstream tasks, including disease diagnosis, image segmentation, registration, progression prediction, and report generation. These tasks were evaluated on 32 public datasets and 5 private cohorts. PRISM consistently outperformed both non-pretrained models and existing foundation models, achieving first-rank results in 39 out of 44 downstream benchmarks with statistical significance improvements. These results underscore its ability to learn robust and generalizable representations across unseen data acquired under diverse MRI protocols. PRISM provides a scalable framework for multi-sequence MRI analysis, thereby enhancing the translational potential of AI in radiology. It delivers consistent performance across diverse imaging protocols, reinforcing its clinical applicability.
FreeTumor: Large-Scale Generative Tumor Synthesis in Computed Tomography Images for Improving Tumor Recognition
Feb 23, 2025Tumor is a leading cause of death worldwide, with an estimated 10 million deaths attributed to tumor-related diseases every year. AI-driven tumor recognition unlocks new possibilities for more precise and intelligent tumor screening and diagnosis. However, the progress is heavily hampered by the scarcity of annotated datasets, which demands extensive annotation efforts by radiologists. To tackle this challenge, we introduce FreeTumor, an innovative Generative AI (GAI) framework to enable large-scale tumor synthesis for mitigating data scarcity. Specifically, FreeTumor effectively leverages a combination of limited labeled data and large-scale unlabeled data for tumor synthesis training. Unleashing the power of large-scale data, FreeTumor is capable of synthesizing a large number of realistic tumors on images for augmenting training datasets. To this end, we create the largest training dataset for tumor synthesis and recognition by curating 161,310 publicly available Computed Tomography (CT) volumes from 33 sources, with only 2.3% containing annotated tumors. To validate the fidelity of synthetic tumors, we engaged 13 board-certified radiologists in a Visual Turing Test to discern between synthetic and real tumors. Rigorous clinician evaluation validates the high quality of our synthetic tumors, as they achieved only 51.1% sensitivity and 60.8% accuracy in distinguishing our synthetic tumors from real ones. Through high-quality tumor synthesis, FreeTumor scales up the recognition training datasets by over 40 times, showcasing a notable superiority over state-of-the-art AI methods including various synthesis methods and foundation models. These findings indicate promising prospects of FreeTumor in clinical applications, potentially advancing tumor treatments and improving the survival rates of patients.
A4-Unet: Deformable Multi-Scale Attention Network for Brain Tumor Segmentation
Dec 08, 2024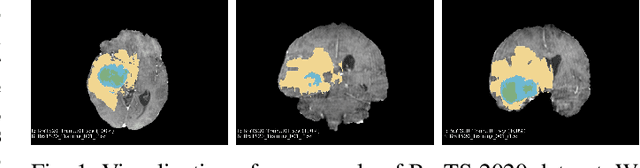
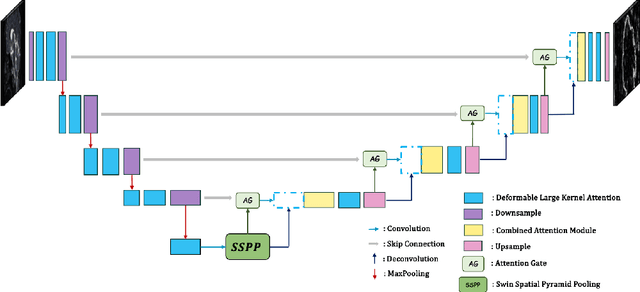
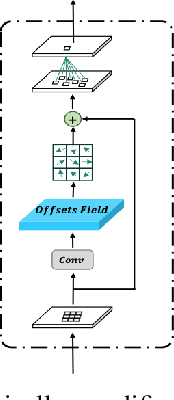
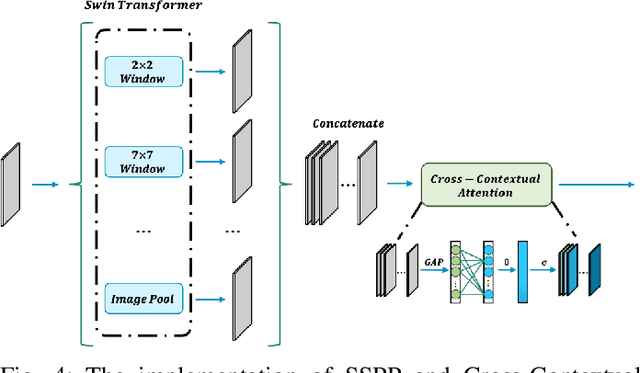
Brain tumor segmentation models have aided diagnosis in recent years. However, they face MRI complexity and variability challenges, including irregular shapes and unclear boundaries, leading to noise, misclassification, and incomplete segmentation, thereby limiting accuracy. To address these issues, we adhere to an outstanding Convolutional Neural Networks (CNNs) design paradigm and propose a novel network named A4-Unet. In A4-Unet, Deformable Large Kernel Attention (DLKA) is incorporated in the encoder, allowing for improved capture of multi-scale tumors. Swin Spatial Pyramid Pooling (SSPP) with cross-channel attention is employed in a bottleneck further to study long-distance dependencies within images and channel relationships. To enhance accuracy, a Combined Attention Module (CAM) with Discrete Cosine Transform (DCT) orthogonality for channel weighting and convolutional element-wise multiplication is introduced for spatial weighting in the decoder. Attention gates (AG) are added in the skip connection to highlight the foreground while suppressing irrelevant background information. The proposed network is evaluated on three authoritative MRI brain tumor benchmarks and a proprietary dataset, and it achieves a 94.4% Dice score on the BraTS 2020 dataset, thereby establishing multiple new state-of-the-art benchmarks. The code is available here: https://github.com/WendyWAAAAANG/A4-Unet.
A Robotic Auto-Focus System based on Deep Reinforcement Learning
Sep 05, 2018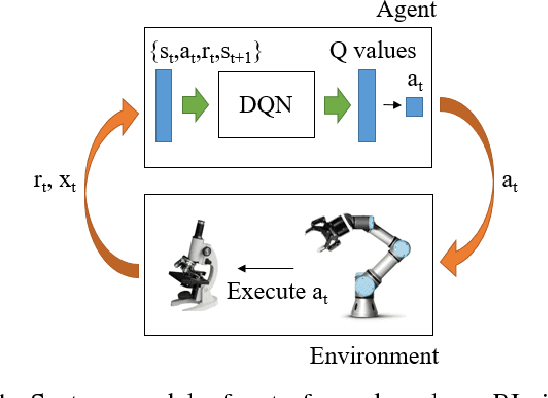



Considering its advantages in dealing with high-dimensional visual input and learning control policies in discrete domain, Deep Q Network (DQN) could be an alternative method of traditional auto-focus means in the future. In this paper, based on Deep Reinforcement Learning, we propose an end-to-end approach that can learn auto-focus policies from visual input and finish at a clear spot automatically. We demonstrate that our method - discretizing the action space with coarse to fine steps and applying DQN is not only a solution to auto-focus but also a general approach towards vision-based control problems. Separate phases of training in virtual and real environments are applied to obtain an effective model. Virtual experiments, which are carried out after the virtual training phase, indicates that our method could achieve 100% accuracy on a certain view with different focus range. Further training on real robots could eliminate the deviation between the simulator and real scenario, leading to reliable performances in real applications.