 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Robotic Auto-Focus System based on Deep Reinforcement Learning
Paper and Code
Sep 05, 2018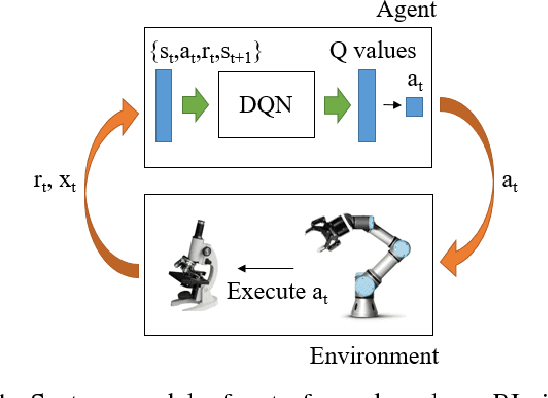



Considering its advantages in dealing with high-dimensional visual input and learning control policies in discrete domain, Deep Q Network (DQN) could be an alternative method of traditional auto-focus means in the future. In this paper, based on Deep Reinforcement Learning, we propose an end-to-end approach that can learn auto-focus policies from visual input and finish at a clear spot automatically. We demonstrate that our method - discretizing the action space with coarse to fine steps and applying DQN is not only a solution to auto-focus but also a general approach towards vision-based control problems. Separate phases of training in virtual and real environments are applied to obtain an effective model. Virtual experiments, which are carried out after the virtual training phase, indicates that our method could achieve 100% accuracy on a certain view with different focus range. Further training on real robots could eliminate the deviation between the simulator and real scenario, leading to reliable performances in real applications.