 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3PT: A Multi-Modal Model for POI Tagging
Jun 16, 2023POI tagging aims to annotate a point of interest (POI) with some informative tags, which facilitates many services related to POIs, including search, recommendation, and so on. Most of the existing solutions neglect the significance of POI images and seldom fuse the textual and visual features of POIs, resulting in suboptimal tagging performance. In this paper, we propose a novel Multi-Modal Model for POI Tagging, namely M3PT, which achieves enhanced POI tagging through fusing the target POI's textual and visual features, and the precise matching between the multi-modal representations. Specifically, we first devise a domain-adaptive image encoder (DIE) to obtain the image embeddings aligned to their gold tags' semantics. Then, in M3PT's text-image fusion module (TIF), the textual and visual representations are fully fused into the POIs' content embeddings for the subsequent matching. In addition, we adopt a contrastive learning strategy to further bridge the gap between the representations of different modalities. To evaluate the tagging models' performance, we have constructed two high-quality POI tagging datasets from the real-world business scenario of Ali Fliggy. Upon the datasets, we conducted the extensive experiments to demonstrate our model's advantage over the baselines of uni-modality and multi-modality, and verify the effectiveness of important components in M3PT, including DIE, TIF and the contrastive learning strategy.
QUERT: Continual Pre-training of Language Model for Query Understanding in Travel Domain Search
Jun 11, 2023


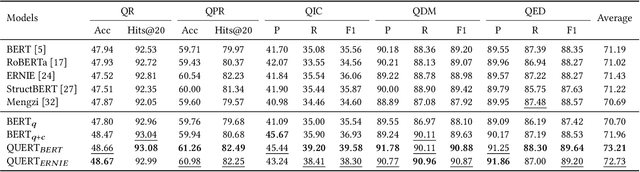
In light of the success of the pre-trained language models (PLMs), continual pre-training of generic PLMs has been the paradigm of domain adaption. In this paper, we propose QUERT, A Continual Pre-trained Language Model for QUERy Understanding in Travel Domain Search. QUERT is jointly trained on four tailored pre-training tasks to the characteristics of query in travel domain search: Geography-aware Mask Prediction, Geohash Code Prediction, User Click Behavior Learning, and Phrase and Token Order Prediction. Performance improvement of downstream tasks and ablation experiment demonstrate the effectiveness of our proposed pre-training tasks. To be specific, the average performance of downstream tasks increases by 2.02% and 30.93% in supervised and unsupervised settings, respectively. To check on the improvement of QUERT to online business, we deploy QUERT and perform A/B testing on Fliggy APP. The feedback results show that QUERT increases the Unique Click-Through Rate and Page Click-Through Rate by 0.89% and 1.03% when applying QUERT as the encoder. Our code and downstream task data will be released for future research.