 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarmonic Beltrami Signature Network: a Shape Prior Module in Deep Learning Framework
Mar 03, 2026This paper presents the Harmonic Beltrami Signature Network (HBSN), a novel deep learning architecture for computing the Harmonic Beltrami Signature (HBS) from binary-like images. HBS is a shape representation that provides a one-to-one correspondence with 2D simply connected shapes, with invariance to translation, scaling, and rotation. By exploiting the function approximation capacity of neural networks, HBSN enables efficient extraction and utilization of shape prior information. The proposed network architecture incorporates a pre-Spatial Transformer Network (pre-STN) for shape normalization, a UNet-based backbone for HBS prediction, and a post-STN for angle regularization. Experiments show that HBSN accurately computes HBS representations, even for complex shapes. Furthermore, we demonstrate how HBSN can be directly incorporated into existing deep learning segmentation models, improving their performance through the use of shape priors. The results confirm the utility of HBSN as a general-purpose module for embedding geometric shape information into computer vision pipelines.
Two-chart Beltrami Optimization for Distortion-Controlled Spherical Bijection with Application to Brain Surface Registration
Feb 04, 2026Many genus-0 surface mapping tasks such as landmark alignment, feature matching, and image-driven registration, can be reduced (via an initial spherical conformal map) to optimizing a spherical self-homeomorphism with controlled distortion. However, existing works lack efficient mechanisms to control the geometric distortion of the resulting mapping. To resolve this issue, we formulate this as a Beltrami-space optimization problem, where the angle distortion is encoded explicitly by the Beltrami differential and bijectivity can be enforced through the constraint $\|μ\|_{\infty}<1$. To make this practical on the sphere, we introduce the Spherical Beltrami Differential (SBD), a two-chart representation of quasiconformal self-maps of the unit sphere $\mathbb{S}^2$, together with cross-chart consistency conditions that yield a globally bijective spherical deformation (up to conformal automorphisms). Building on the Spectral Beltrami Network, we develop BOOST, a differentiable optimization framework that updates two Beltrami fields to minimize task-driven losses while regularizing distortion and enforcing consistency along the seam. Experiments on large-deformation landmark matching and intensity-based spherical registration demonstrate improved task performance meanwhile maintaining controlled distortion and robust bijective behavior. We also apply the method to cortical surface registration by aligning sulcal landmarks and matching cortical sulcal depth, achieving comparative or better registration performance without sacrificing geometric validity.
Genus-0 Surface Parameterization using Spherical Beltrami Differentials
Feb 02, 2026Spherical surface parameterization is a fundamental tool in geometry processing and imaging science. For a genus-0 closed surface, many efficient algorithms can map the surface to the sphere; consequently, a broad class of task-driven genus-0 mapping problems can be reduced to constructing a high-quality spherical self-map. However, existing approaches often face a trade-off between satisfying task objectives (e.g., landmark or feature alignment), maintaining bijectivity, and controlling geometric distortion. We introduce the Spherical Beltrami Differential (SBD), a two-chart representation of quasiconformal self-maps of the sphere, and establish its correspondence with spherical homeomorphisms up to conformal automorphisms. Building on the Spectral Beltrami Network (SBN), we propose a neural optimization framework BOOST that optimizes two Beltrami fields on hemispherical stereographic charts and enforces global consistency through explicit seam-aware constraints. Experiments on large-deformation landmark matching and intensity-based spherical registration demonstrate the effectiveness of our proposed framework. We further apply the method to brain cortical surface registration, aligning sulcal landmarks and jointly matching cortical sulci depth maps, showing improved task fidelity with controlled distortion and robust bijective behavior.
A neural optimization framework for free-boundary diffeomorphic mapping problems and its applications
Nov 12, 2025Free-boundary diffeomorphism optimization is a core ingredient in the surface mapping problem but remains notoriously difficult because the boundary is unconstrained and local bijectivity must be preserved under large deformation. Numerical Least-Squares Quasiconformal (LSQC) theory, with its provable existence, uniqueness, similarity-invariance and resolution-independence, offers an elegant mathematical remedy. However, the conventional numerical algorithm requires landmark conditioning, and cannot be applied into gradient-based optimization. We propose a neural surrogate, the Spectral Beltrami Network (SBN), that embeds LSQC energy into a multiscale mesh-spectral architecture. Next, we propose the SBN guided optimization framework SBN-Opt which optimizes free-boundary diffeomorphism for the problem, with local geometric distortion explicitly controllable. Extensive experiments on density-equalizing maps and inconsistent surface registration demonstrate our SBN-Opt's superiority over traditional numerical algorithms.
A Registration-Based Star-Shape Segmentation Model and Fast Algorithms
Aug 11, 2025Image segmentation plays a crucial role in extracting objects of interest and identifying their boundaries within an image. However, accurate segmentation becomes challenging when dealing with occlusions, obscurities, or noise in corrupted images. To tackle this challenge, prior information is often utilized, with recent attention on star-shape priors. In this paper, we propose a star-shape segmentation model based on the registration framework. By combining the level set representation with the registration framework and imposing constraints on the deformed level set function, our model enables both full and partial star-shape segmentation, accommodating single or multiple centers. Additionally, our approach allows for the enforcement of identified boundaries to pass through specified landmark locations. We tackle the proposed models using the alternating direction method of multipliers. Through numerical experiments conducted on synthetic and real images, we demonstrate the efficacy of our approach in achieving accurate star-shape segmentation.
Learning-based density-equalizing map
Jun 10, 2025



Density-equalizing map (DEM) serves as a powerful technique for creating shape deformations with the area changes reflecting an underlying density function. In recent decades, DEM has found widespread applications in fields such as data visualization, geometry processing, and medical imaging. Traditional approaches to DEM primarily rely on iterative numerical solvers for diffusion equations or optimization-based methods that minimize handcrafted energy functionals. However, these conventional techniques often face several challenges: they may suffer from limited accuracy, produce overlapping artifacts in extreme cases, and require substantial algorithmic redesign when extended from 2D to 3D, due to the derivative-dependent nature of their energy formulations. In this work, we propose a novel learning-based density-equalizing mapping framework (LDEM) using deep neural networks. Specifically, we introduce a loss function that enforces density uniformity and geometric regularity, and utilize a hierarchical approach to predict the transformations at both the coarse and dense levels. Our method demonstrates superior density-equalizing and bijectivity properties compared to prior methods for a wide range of simple and complex density distributions, and can be easily applied to surface remeshing with different effects. Also, it generalizes seamlessly from 2D to 3D domains without structural changes to the model architecture or loss formulation. Altogether, our work opens up new possibilities for scalable and robust computation of density-equalizing maps for practical applications.
Circular Image Deturbulence using Quasi-conformal Geometry
Apr 21, 2025The presence of inhomogeneous media between optical sensors and objects leads to distorted imaging outputs, significantly complicating downstream image-processing tasks. A key challenge in image restoration is the lack of high-quality, paired-label images required for training supervised models. In this paper, we introduce the Circular Quasi-Conformal Deturbulence (CQCD) framework, an unsupervised approach for removing image distortions through a circular architecture. This design ensures that the restored image remains both geometrically accurate and visually faithful while preventing the accumulation of incorrect estimations. The circular restoration process involves both forward and inverse mapping. To ensure the bijectivity of the estimated non-rigid deformations, computational quasi-conformal geometry theories are leveraged to regularize the mapping, enforcing its homeomorphic properties. This guarantees a well-defined transformation that preserves structural integrity and prevents unwanted artifacts. Furthermore, tight-frame blocks are integrated to encode distortion-sensitive features for precise recovery. To validate the performance of our approach, we conduct evaluations on various synthetic and real-world captured images. Experimental results demonstrate that CQCD not only outperforms existing state-of-the-art deturbulence methods in terms of image restoration quality but also provides highly accurate deformation field estimations.
Quasi-Conformal Convolution : A Learnable Convolution for Deep Learning on Riemann Surfaces
Feb 04, 2025Deep learning on non-Euclidean domains is important for analyzing complex geometric data that lacks common coordinate systems and familiar Euclidean properties. A central challenge in this field is to define convolution on domains, which inherently possess irregular and non-Euclidean structures. In this work, we introduce Quasi-conformal Convolution (QCC), a novel framework for defining convolution on Riemann surfaces using quasi-conformal theories. Each QCC operator is linked to a specific quasi-conformal mapping, enabling the adjustment of the convolution operation through manipulation of this mapping. By utilizing trainable estimator modules that produce Quasi-conformal mappings, QCC facilitates adaptive and learnable convolution operators that can be dynamically adjusted according to the underlying data structured on Riemann surfaces. QCC unifies a broad range of spatially defined convolutions, facilitating the learning of tailored convolution operators on each underlying surface optimized for specific tasks. Building on this foundation, we develop the Quasi-Conformal Convolutional Neural Network (QCCNN) to address a variety of tasks related to geometric data. We validate the efficacy of QCCNN through the classification of images defined on curvilinear Riemann surfaces, demonstrating superior performance in this context. Additionally, we explore its potential in medical applications, including craniofacial analysis using 3D facial data and lesion segmentation on 3D human faces, achieving enhanced accuracy and reliability.
Shape Prior Segmentation Guided by Harmonic Beltrami Signature
Jul 05, 2024



This paper presents a novel shape prior segmentation method guided by the Harmonic Beltrami Signature (HBS). The HBS is a shape representation fully capturing 2D simply connected shapes, exhibiting resilience against perturbations and invariance to translation, rotation, and scaling. The proposed method integrates the HBS within a quasi-conformal topology preserving segmentation framework, leveraging shape prior knowledge to significantly enhance segmentation performance, especially for low-quality or occluded images. The key innovation lies in the bifurcation of the optimization process into two iterative stages: 1) The computation of a quasi-conformal deformation map, which transforms the unit disk into the targeted segmentation area, driven by image data and other regularization terms; 2) The subsequent refinement of this map is contingent upon minimizing the $L_2$ distance between its Beltrami coefficient and the reference HBS. This shape-constrained refinement ensures that the segmentation adheres to the reference shape(s) by exploiting the inherent invariance, robustness, and discerning shape discriminative capabilities afforded by the HBS. Extensive experiments on synthetic and real-world images validate the method's ability to improve segmentation accuracy over baselines, eliminate preprocessing requirements, resist noise corruption, and flexibly acquire and apply shape priors. Overall, the HBS segmentation framework offers an efficient strategy to robustly incorporate the shape prior knowledge, thereby advancing critical low-level vision tasks.
A deep neural network framework for dynamic multi-valued mapping estimation and its applications
Jun 29, 2024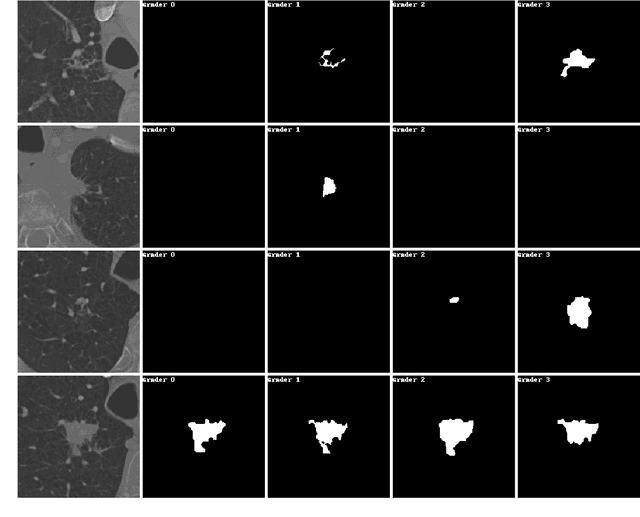

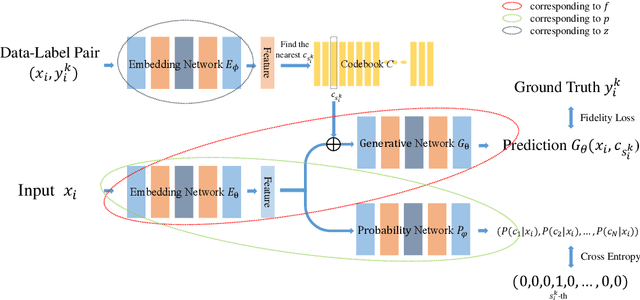
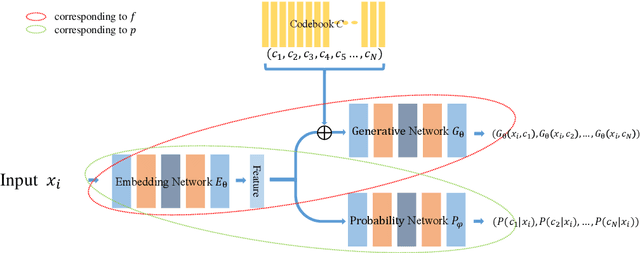
This paper addresses the problem of modeling and estimating dynamic multi-valued mappings. While most mathematical models provide a unique solution for a given input, real-world applications often lack deterministic solutions. In such scenarios, estimating dynamic multi-valued mappings is necessary to suggest different reasonable solutions for each input. This paper introduces a deep neural network framework incorporating a generative network and a classification component. The objective is to model the dynamic multi-valued mapping between the input and output by providing a reliable uncertainty measurement. Generating multiple solutions for a given input involves utilizing a discrete codebook comprising finite variables. These variables are fed into a generative network along with the input, producing various output possibilities. The discreteness of the codebook enables efficient estimation of the output's conditional probability distribution for any given input using a classifier. By jointly optimizing the discrete codebook and its uncertainty estimation during training using a specially designed loss function, a highly accurate approximation is achieved. The effectiveness of our proposed framework is demonstrated through its application to various imaging problems, using both synthetic and real imaging data. Experimental results show that our framework accurately estimates the dynamic multi-valued mapping with uncertainty estimation.