 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Data Augmentation
Paper and Code
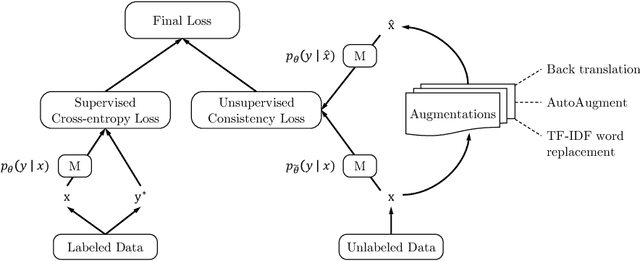
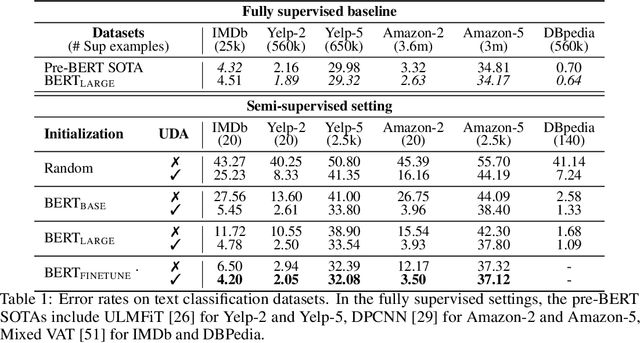
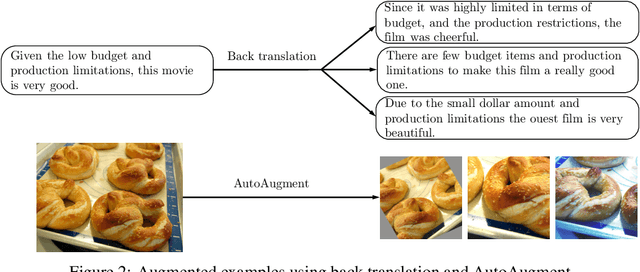

Despite its success, deep learning still needs large labeled datasets to succeed. Data augmentation has shown much promise in alleviating the need for more labeled data, but it so far has mostly been applied in supervised settings and achieved limited gains. In this work, we propose to apply data augmentation to unlabeled data in a semi-supervised learning setting. Our method, named Unsupervised Data Augmentation or UDA, encourages the model predictions to be consistent between an unlabeled example and an augmented unlabeled example. Unlike previous methods that use random noise such as Gaussian noise or dropout noise, UDA has a small twist in that it makes use of harder and more realistic noise generated by state-of-the-art data augmentation methods. This small twist leads to substantial improvements on six language tasks and three vision tasks even when the labeled set is extremely small. For example, on the IMDb text classification dataset, with only 20 labeled examples, UDA outperforms the state-of-the-art model trained on 25,000 labeled examples. On standard semi-supervised learning benchmarks, CIFAR-10 with 4,000 examples and SVHN with 1,000 examples, UDA outperforms all previous approaches and reduces more than $30\%$ of the error rates of state-of-the-art methods: going from 7.66% to 5.27% and from 3.53% to 2.46% respectively. UDA also works well on datasets that have a lot of labeled data. For example, on ImageNet, with 1.3M extra unlabeled data, UDA improves the top-1/top-5 accuracy from 78.28/94.36% to 79.04/94.45% when compared to AutoAugment.