 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Simple Mixture of Softmaxes with BPE and Hybrid-LightRNN for Language Generation
Paper and Code

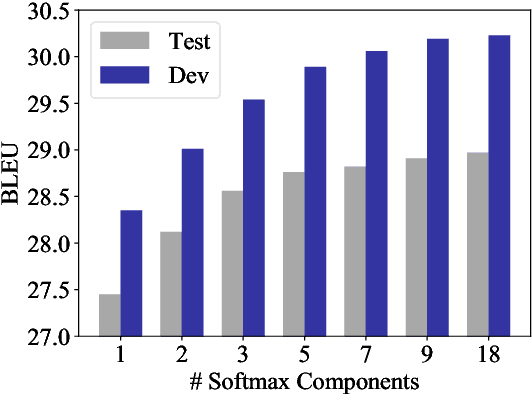
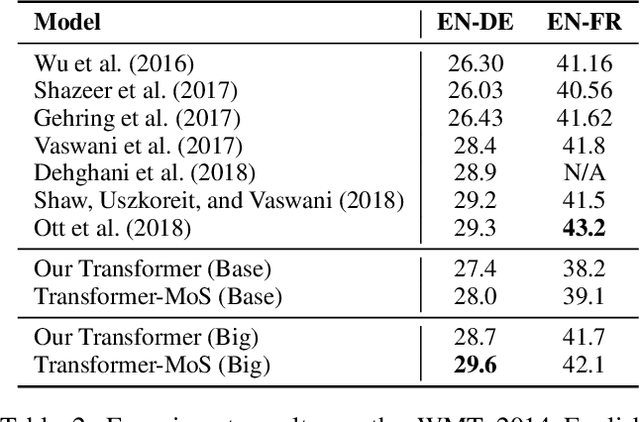

Mixture of Softmaxes (MoS) has been shown to be effective at addressing the expressiveness limitation of Softmax-based models. Despite the known advantage, MoS is practically sealed by its large consumption of memory and computational time due to the need of computing multiple Softmaxes. In this work, we set out to unleash the power of MoS in practical applications by investigating improved word coding schemes, which could effectively reduce the vocabulary size and hence relieve the memory and computation burden. We show both BPE and our proposed Hybrid-LightRNN lead to improved encoding mechanisms that can halve the time and memory consumption of MoS without performance losses. With MoS, we achieve an improvement of 1.5 BLEU scores on IWSLT 2014 German-to-English corpus and an improvement of 0.76 CIDEr score on image captioning. Moreover, on the larger WMT 2014 machine translation dataset, our MoS-boosted Transformer yields 29.5 BLEU score for English-to-German and 42.1 BLEU score for English-to-French, outperforming the single-Softmax Transformer by 0.8 and 0.4 BLEU scores respectively and achieving the state-of-the-art result on WMT 2014 English-to-German task.