 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Knowledge Graph Error Detection
Nov 18, 2022
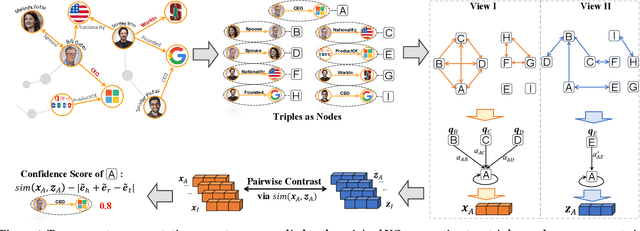
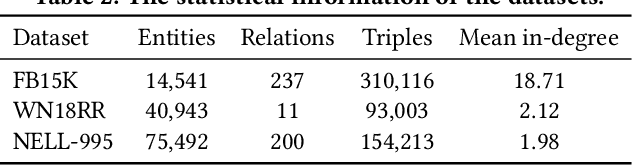
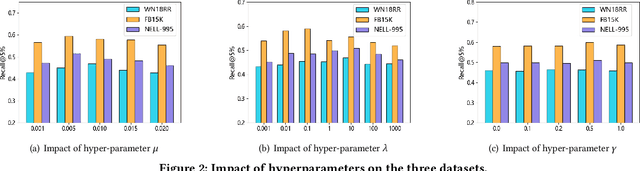
Knowledge Graph (KG) errors introduce non-negligible noise, severely affecting KG-related downstream tasks. Detecting errors in KGs is challenging since the patterns of errors are unknown and diverse, while ground-truth labels are rare or even unavailable. A traditional solution is to construct logical rules to verify triples, but it is not generalizable since different KGs have distinct rules with domain knowledge involved. Recent studies focus on designing tailored detectors or ranking triples based on KG embedding loss. However, they all rely on negative samples for training, which are generated by randomly replacing the head or tail entity of existing triples. Such a negative sampling strategy is not enough for prototyping practical KG errors, e.g., (Bruce_Lee, place_of_birth, China), in which the three elements are often relevant, although mismatched. We desire a more effective unsupervised learning mechanism tailored for KG error detection. To this end, we propose a novel framework - ContrAstive knowledge Graph Error Detection (CAGED). It introduces contrastive learning into KG learning and provides a novel way of modeling KG. Instead of following the traditional setting, i.e., considering entities as nodes and relations as semantic edges, CAGED augments a KG into different hyper-views, by regarding each relational triple as a node. After joint training with KG embedding and contrastive learning loss, CAGED assesses the trustworthiness of each triple based on two learning signals, i.e., the consistency of triple representations across multi-views and the self-consistency within the triple. Extensive experiments on three real-world KGs show that CAGED outperforms state-of-the-art methods in KG error detection. Our codes and datasets are available at https://github.com/Qing145/CAGED.git.
Multi-layered Semantic Representation Network for Multi-label Image Classification
Jun 22, 2021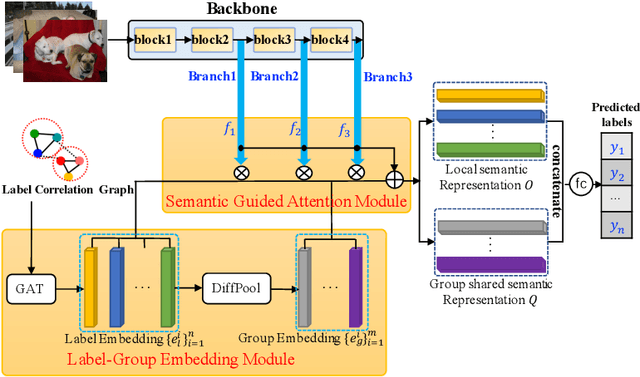
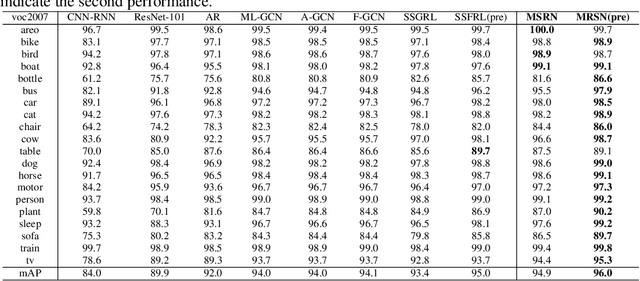
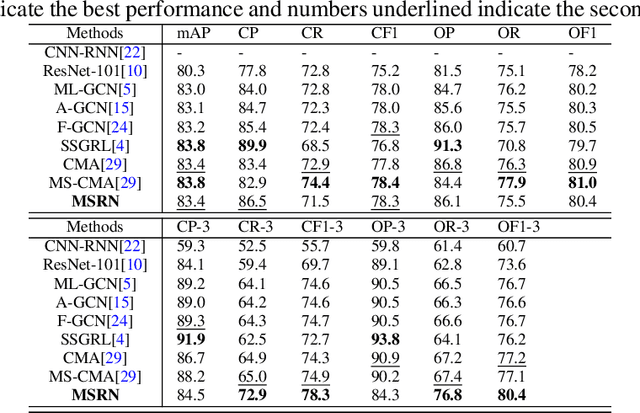
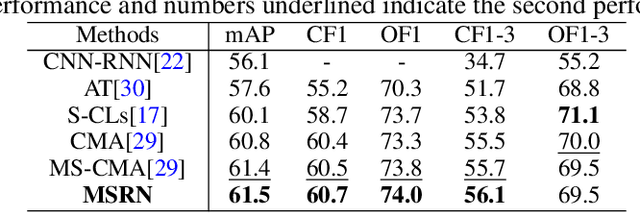
Multi-label image classification (MLIC) is a fundamental and practical task, which aims to assign multiple possible labels to an image. In recent years, many deep convolutional neural network (CNN) based approaches have been proposed which model label correlations to discover semantics of labels and learn semantic representations of images. This paper advances this research direction by improving both the modeling of label correlations and the learning of semantic representations. On the one hand, besides the local semantics of each label, we propose to further explore global semantics shared by multiple labels. On the other hand, existing approaches mainly learn the semantic representations at the last convolutional layer of a CNN. But it has been noted that the image representations of different layers of CNN capture different levels or scales of features and have different discriminative abilities. We thus propose to learn semantic representations at multiple convolutional layers. To this end, this paper designs a Multi-layered Semantic Representation Network (MSRN) which discovers both local and global semantics of labels through modeling label correlations and utilizes the label semantics to guide the semantic representations learning at multiple layers through an attention mechanism. Extensive experiments on four benchmark datasets including VOC 2007, COCO, NUS-WIDE, and Apparel show a competitive performance of the proposed MSRN against state-of-the-art models.
Generalization Error Bound for Hyperbolic Ordinal Embedding
May 21, 2021Hyperbolic ordinal embedding (HOE) represents entities as points in hyperbolic space so that they agree as well as possible with given constraints in the form of entity i is more similar to entity j than to entity k. It has been experimentally shown that HOE can obtain representations of hierarchical data such as a knowledge base and a citation network effectively, owing to hyperbolic space's exponential growth property. However, its theoretical analysis has been limited to ideal noiseless settings, and its generalization error in compensation for hyperbolic space's exponential representation ability has not been guaranteed. The difficulty is that existing generalization error bound derivations for ordinal embedding based on the Gramian matrix do not work in HOE, since hyperbolic space is not inner-product space. In this paper, through our novel characterization of HOE with decomposed Lorentz Gramian matrices, we provide a generalization error bound of HOE for the first time, which is at most exponential with respect to the embedding space's radius. Our comparison between the bounds of HOE and Euclidean ordinal embedding shows that HOE's generalization error is reasonable as a cost for its exponential representation ability.
A Novel Global Spatial Attention Mechanism in Convolutional Neural Network for Medical Image Classification
Jul 31, 2020


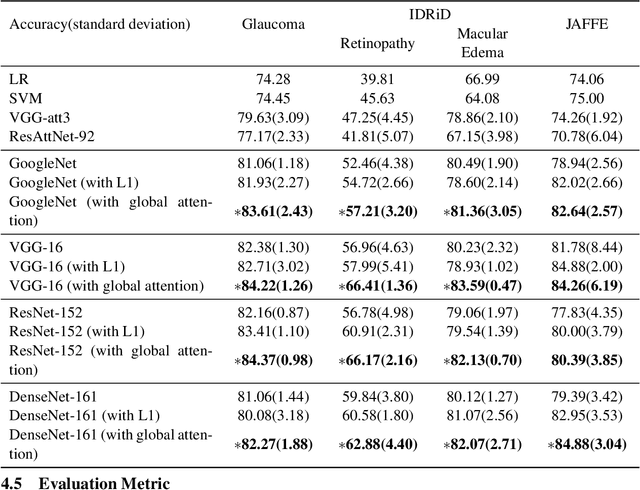
Spatial attention has been introduced to convolutional neural networks (CNNs) for improving both their performance and interpretability in visual tasks including image classification. The essence of the spatial attention is to learn a weight map which represents the relative importance of activations within the same layer or channel. All existing attention mechanisms are local attentions in the sense that weight maps are image-specific. However, in the medical field, there are cases that all the images should share the same weight map because the set of images record the same kind of symptom related to the same object and thereby share the same structural content. In this paper, we thus propose a novel global spatial attention mechanism in CNNs mainly for medical image classification. The global weight map is instantiated by a decision boundary between important pixels and unimportant pixels. And we propose to realize the decision boundary by a binary classifier in which the intensities of all images at a pixel are the features of the pixel. The binary classification is integrated into an image classification CNN and is to be optimized together with the CNN. Experiments on two medical image datasets and one facial expression dataset showed that with the proposed attention, not only the performance of four powerful CNNs which are GoogleNet, VGG, ResNet, and DenseNet can be improved, but also meaningful attended regions can be obtained, which is beneficial for understanding the content of images of a domain.