 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge360VFI: A Dataset and Benchmark for Omnidirectional Video Frame Interpolation
Jul 19, 2024



With the development of VR-related techniques, viewers can enjoy a realistic and immersive experience through a head-mounted display, while omnidirectional video with a low frame rate can lead to user dizziness. However, the prevailing plane frame interpolation methodologies are unsuitable for Omnidirectional Video Interpolation, chiefly due to the lack of models tailored to such videos with strong distortion, compounded by the scarcity of valuable datasets for Omnidirectional Video Frame Interpolation. In this paper, we introduce the benchmark dataset, 360VFI, for Omnidirectional Video Frame Interpolation. We present a practical implementation that introduces a distortion prior from omnidirectional video into the network to modulate distortions. We especially propose a pyramid distortion-sensitive feature extractor that uses the unique characteristics of equirectangular projection (ERP) format as prior information. Moreover, we devise a decoder that uses an affine transformation to facilitate the synthesis of intermediate frames further. 360VFI is the first dataset and benchmark that explores the challenge of Omnidirectional Video Frame Interpolation. Through our benchmark analysis, we presented four different distortion conditions scenes in the proposed 360VFI dataset to evaluate the challenge triggered by distortion during interpolation. Besides, experimental results demonstrate that Omnidirectional Video Interpolation can be effectively improved by modeling for omnidirectional distortion.
NNVISR: Bring Neural Network Video Interpolation and Super Resolution into Video Processing Framework
Aug 06, 2023We present NNVISR - an open-source filter plugin for the VapourSynth video processing framework, which facilitates the application of neural networks for various kinds of video enhancing tasks, including denoising, super resolution, interpolation, and spatio-temporal super-resolution. NNVISR fills the gap between video enhancement neural networks and video processing pipelines, by accepting any network that enhances a group of frames, and handling all other network agnostic details during video processing. NNVISR is publicly released at https://github.com/tongyuantongyu/vs-NNVISR.
You Only Align Once: Bidirectional Interaction for Spatial-Temporal Video Super-Resolution
Jul 13, 2022
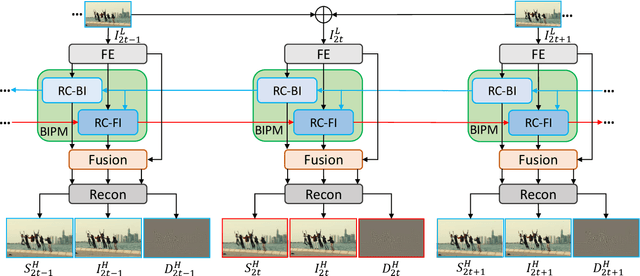

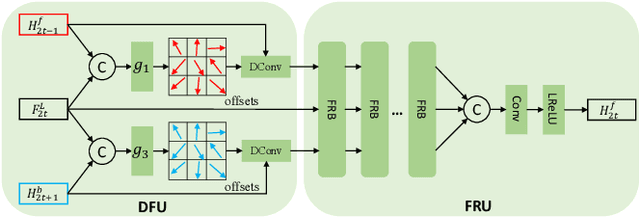
Spatial-Temporal Video Super-Resolution (ST-VSR) technology generates high-quality videos with higher resolution and higher frame rates. Existing advanced methods accomplish ST-VSR tasks through the association of Spatial and Temporal video super-resolution (S-VSR and T-VSR). These methods require two alignments and fusions in S-VSR and T-VSR, which is obviously redundant and fails to sufficiently explore the information flow of consecutive spatial LR frames. Although bidirectional learning (future-to-past and past-to-future) was introduced to cover all input frames, the direct fusion of final predictions fails to sufficiently exploit intrinsic correlations of bidirectional motion learning and spatial information from all frames. We propose an effective yet efficient recurrent network with bidirectional interaction for ST-VSR, where only one alignment and fusion is needed. Specifically, it first performs backward inference from future to past, and then follows forward inference to super-resolve intermediate frames. The backward and forward inferences are assigned to learn structures and details to simplify the learning task with joint optimizations. Furthermore, a Hybrid Fusion Module (HFM) is designed to aggregate and distill information to refine spatial information and reconstruct high-quality video frames. Extensive experiments on two public datasets demonstrate that our method outperforms state-of-the-art methods in efficiency, and reduces calculation cost by about 22%.
Spatial-Temporal Space Hand-in-Hand: Spatial-Temporal Video Super-Resolution via Cycle-Projected Mutual Learning
May 11, 2022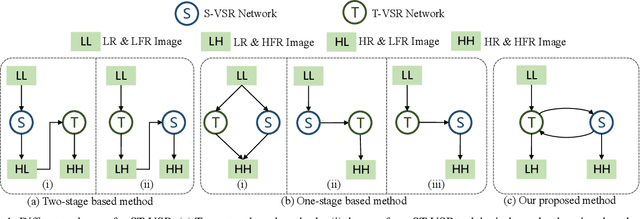
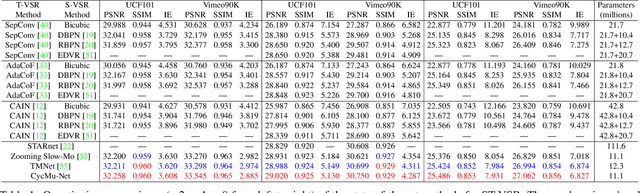
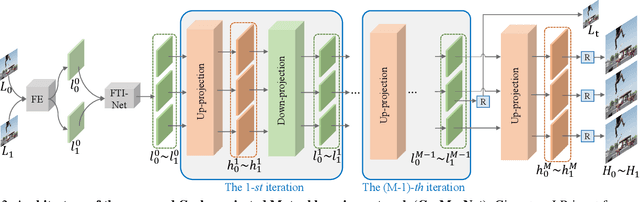
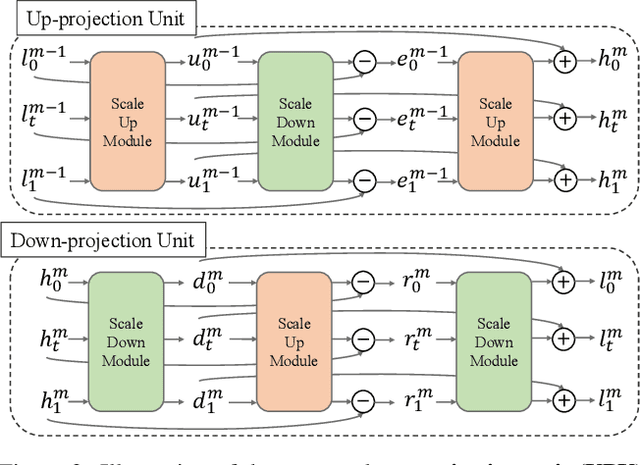
Spatial-Temporal Video Super-Resolution (ST-VSR) aims to generate super-resolved videos with higher resolution(HR) and higher frame rate (HFR). Quite intuitively, pioneering two-stage based methods complete ST-VSR by directly combining two sub-tasks: Spatial Video Super-Resolution (S-VSR) and Temporal Video Super-Resolution(T-VSR) but ignore the reciprocal relations among them. Specifically, 1) T-VSR to S-VSR: temporal correlations help accurate spatial detail representation with more clues; 2) S-VSR to T-VSR: abundant spatial information contributes to the refinement of temporal prediction. To this end, we propose a one-stage based Cycle-projected Mutual learning network (CycMu-Net) for ST-VSR, which makes full use of spatial-temporal correlations via the mutual learning between S-VSR and T-VSR. Specifically, we propose to exploit the mutual information among them via iterative up-and-down projections, where the spatial and temporal features are fully fused and distilled, helping the high-quality video reconstruction. Besides extensive experiments on benchmark datasets, we also compare our proposed CycMu-Net with S-VSR and T-VSR tasks, demonstrating that our method significantly outperforms state-of-the-art methods.
* 10 pages, 8 figures