 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegration of a machine learning model into a decision support tool to predict absenteeism at work of prospective employees
Feb 02, 2022



Purpose - Inefficient hiring may result in lower productivity and higher training costs. Productivity losses caused by absenteeism at work cost U.S. employers billions of dollars each year. Also, employers typically spend a considerable amount of time managing employees who perform poorly. The purpose of this study is to develop a decision support tool to predict absenteeism among potential employees. Design/methodology/approach - We utilized a popular open-access dataset. In order to categorize absenteeism classes, the data have been preprocessed, and four methods of machine learning classification have been applied: Multinomial Logistic Regression (MLR), Support Vector Machines (SVM), Artificial Neural Networks (ANN), and Random Forests (RF). We selected the best model, based on several validation scores, and compared its performance against the existing model; we then integrated the best model into our proposed web-based for hiring managers. Findings - A web-based decision tool allows hiring managers to make more informed decisions before hiring a potential employee, thus reducing time, financial loss and reducing the probability of economic insolvency. Originality/value - In this paper, we propose a model that is trained based on attributes that can be collected during the hiring process. Furthermore, hiring managers may lack experience in machine learning or do not have the time to spend developing machine learning algorithms. Thus, we propose a web-based interactive tool that can be used without prior knowledge of machine learning algorithms.
Remaining Useful Life Estimation of Hard Disk Drives using Bidirectional LSTM Networks
Sep 11, 2021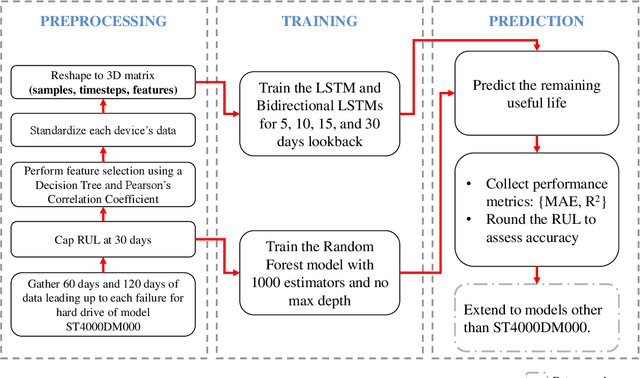
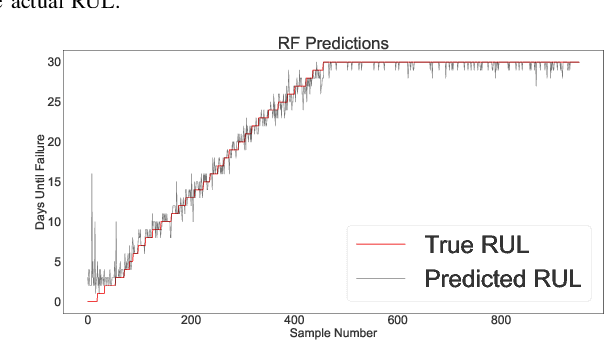
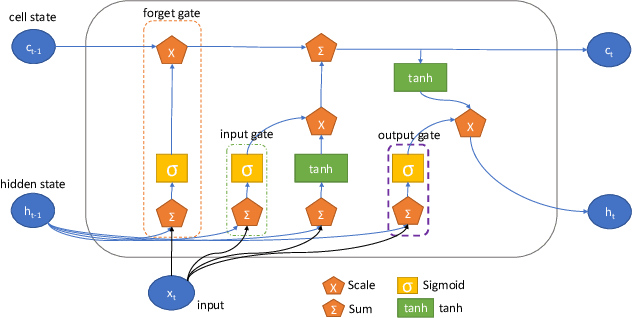
Physical and cloud storage services are well-served by functioning and reliable high-volume storage systems. Recent observations point to hard disk reliability as one of the most pressing reliability issues in data centers containing massive volumes of storage devices such as HDDs. In this regard, early detection of impending failure at the disk level aids in reducing system downtime and reduces operational loss making proactive health monitoring a priority for AIOps in such settings. In this work, we introduce methods of extracting meaningful attributes associated with operational failure and of pre-processing the highly imbalanced health statistics data for subsequent prediction tasks using data-driven approaches. We use a Bidirectional LSTM with a multi-day look back period to learn the temporal progression of health indicators and baseline them against vanilla LSTM and Random Forest models to come up with several key metrics that establish the usefulness of and superiority of our model under some tightly defined operational constraints. For example, using a 15 day look back period, our approach can predict the occurrence of disk failure with an accuracy of 96.4% considering test data 60 days before failure. This helps to alert operations maintenance well in-advance about potential mitigation needs. In addition, our model reports a mean absolute error of 0.12 for predicting failure up to 60 days in advance, placing it among the state-of-the-art in recent literature.