 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe State of Lithium-Ion Battery Health Prognostics in the CPS Era
Mar 28, 2024Lithium-ion batteries (Li-ion) have revolutionized energy storage technology, becoming integral to our daily lives by powering a diverse range of devices and applications. Their high energy density, fast power response, recyclability, and mobility advantages have made them the preferred choice for numerous sectors. This paper explores the seamless integration of Prognostics and Health Management within batteries, presenting a multidisciplinary approach that enhances the reliability, safety, and performance of these powerhouses. Remaining useful life (RUL), a critical concept in prognostics, is examined in depth, emphasizing its role in predicting component failure before it occurs. The paper reviews various RUL prediction methods, from traditional models to cutting-edge data-driven techniques. Furthermore, it highlights the paradigm shift toward deep learning architectures within the field of Li-ion battery health prognostics, elucidating the pivotal role of deep learning in addressing battery system complexities. Practical applications of PHM across industries are also explored, offering readers insights into real-world implementations.This paper serves as a comprehensive guide, catering to both researchers and practitioners in the field of Li-ion battery PHM.
De-SaTE: Denoising Self-attention Transformer Encoders for Li-ion Battery Health Prognostics
Sep 28, 2023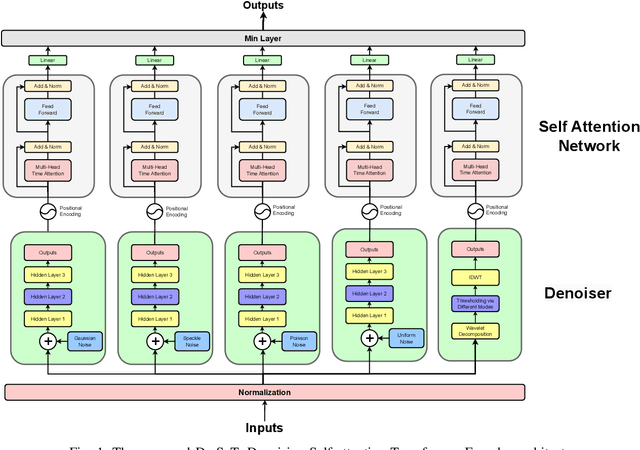

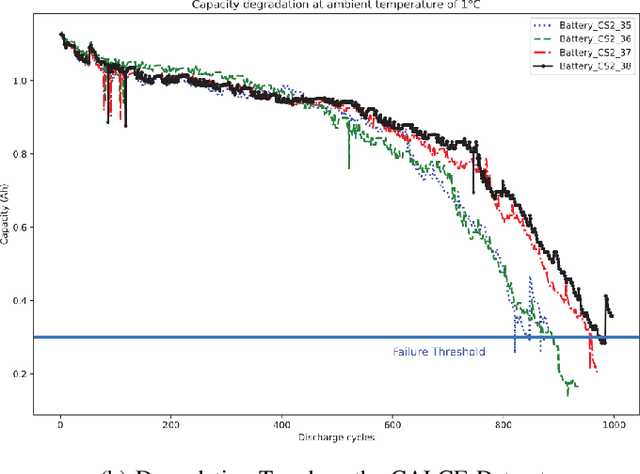

Lithium Ion (Li-ion) batteries have gained widespread popularity across various industries, from powering portable electronic devices to propelling electric vehicles and supporting energy storage systems. A central challenge in managing Li-ion batteries effectively is accurately predicting their Remaining Useful Life (RUL), which is a critical measure for proactive maintenance and predictive analytics. This study presents a novel approach that harnesses the power of multiple denoising modules, each trained to address specific types of noise commonly encountered in battery data. Specifically we use a denoising auto-encoder and a wavelet denoiser to generate encoded/decomposed representations, which are subsequently processed through dedicated self-attention transformer encoders. After extensive experimentation on the NASA and CALCE datasets, we are able to characterize a broad spectrum of health indicator estimations under a set of diverse noise patterns. We find that our reported error metrics on these datasets are on par or better with the best reported in recent literature.
TFBEST: Dual-Aspect Transformer with Learnable Positional Encoding for Failure Prediction
Sep 06, 2023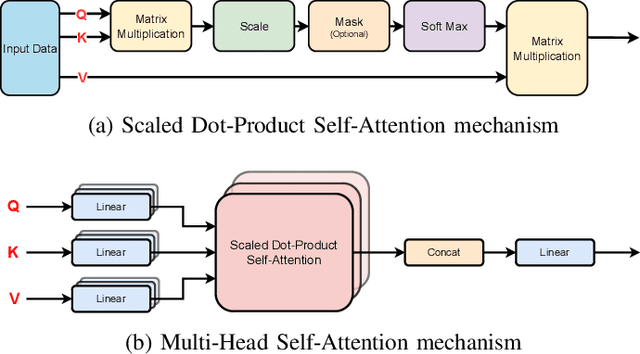
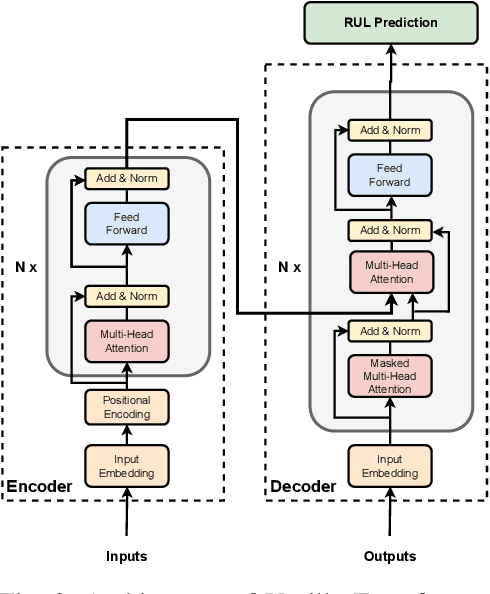
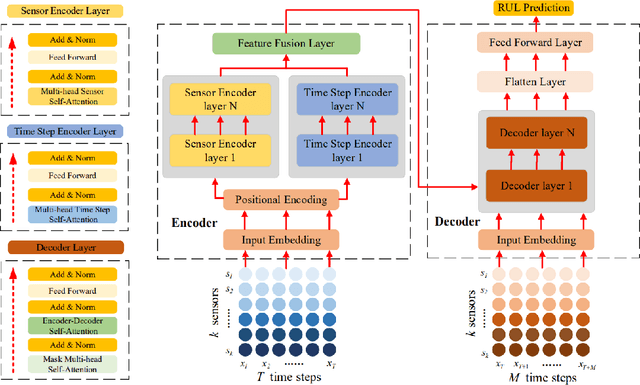
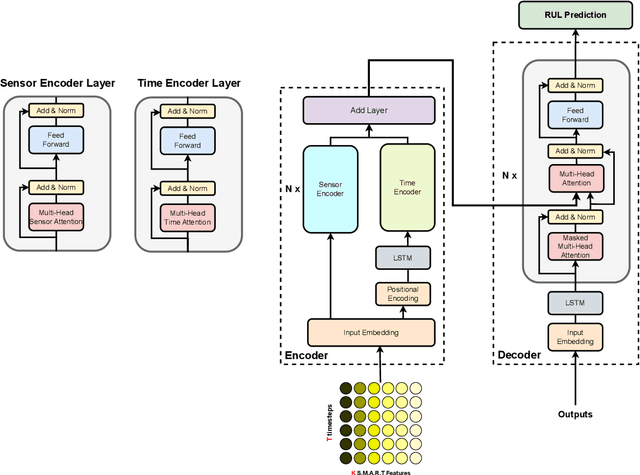
Hard Disk Drive (HDD) failures in datacenters are costly - from catastrophic data loss to a question of goodwill, stakeholders want to avoid it like the plague. An important tool in proactively monitoring against HDD failure is timely estimation of the Remaining Useful Life (RUL). To this end, the Self-Monitoring, Analysis and Reporting Technology employed within HDDs (S.M.A.R.T.) provide critical logs for long-term maintenance of the security and dependability of these essential data storage devices. Data-driven predictive models in the past have used these S.M.A.R.T. logs and CNN/RNN based architectures heavily. However, they have suffered significantly in providing a confidence interval around the predicted RUL values as well as in processing very long sequences of logs. In addition, some of these approaches, such as those based on LSTMs, are inherently slow to train and have tedious feature engineering overheads. To overcome these challenges, in this work we propose a novel transformer architecture - a Temporal-fusion Bi-encoder Self-attention Transformer (TFBEST) for predicting failures in hard-drives. It is an encoder-decoder based deep learning technique that enhances the context gained from understanding health statistics sequences and predicts a sequence of the number of days remaining before a disk potentially fails. In this paper, we also provide a novel confidence margin statistic that can help manufacturers replace a hard-drive within a time frame. Experiments on Seagate HDD data show that our method significantly outperforms the state-of-the-art RUL prediction methods during testing over the exhaustive 10-year data from Backblaze (2013-present). Although validated on HDD failure prediction, the TFBEST architecture is well-suited for other prognostics applications and may be adapted for allied regression problems.
Large-scale End-of-Life Prediction of Hard Disks in Distributed Datacenters
Mar 20, 2023On a daily basis, data centers process huge volumes of data backed by the proliferation of inexpensive hard disks. Data stored in these disks serve a range of critical functional needs from financial, and healthcare to aerospace. As such, premature disk failure and consequent loss of data can be catastrophic. To mitigate the risk of failures, cloud storage providers perform condition-based monitoring and replace hard disks before they fail. By estimating the remaining useful life of hard disk drives, one can predict the time-to-failure of a particular device and replace it at the right time, ensuring maximum utilization whilst reducing operational costs. In this work, large-scale predictive analyses are performed using severely skewed health statistics data by incorporating customized feature engineering and a suite of sequence learners. Past work suggests using LSTMs as an excellent approach to predicting remaining useful life. To this end, we present an encoder-decoder LSTM model where the context gained from understanding health statistics sequences aid in predicting an output sequence of the number of days remaining before a disk potentially fails. The models developed in this work are trained and tested across an exhaustive set of all of the 10 years of S.M.A.R.T. health data in circulation from Backblaze and on a wide variety of disk instances. It closes the knowledge gap on what full-scale training achieves on thousands of devices and advances the state-of-the-art by providing tangible metrics for evaluation and generalization for practitioners looking to extend their workflow to all years of health data in circulation across disk manufacturers. The encoder-decoder LSTM posted an RMSE of 0.83 during training and 0.86 during testing over the exhaustive 10 year data while being able to generalize competitively over other drives from the Seagate family.
AdaSwarm: A Novel PSO optimization Method for the Mathematical Equivalence of Error Gradients
May 19, 2020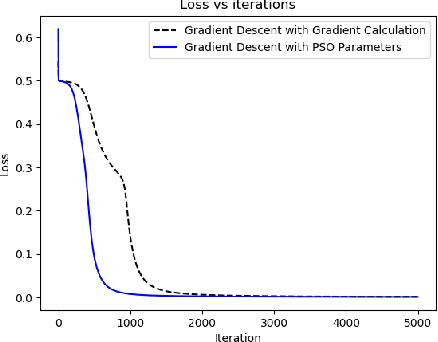
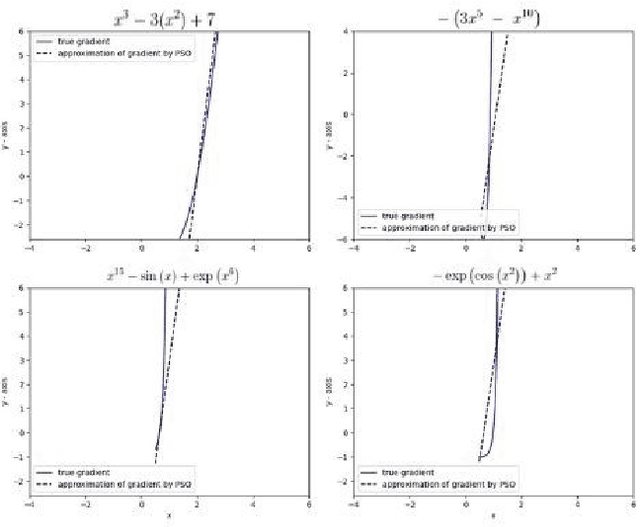
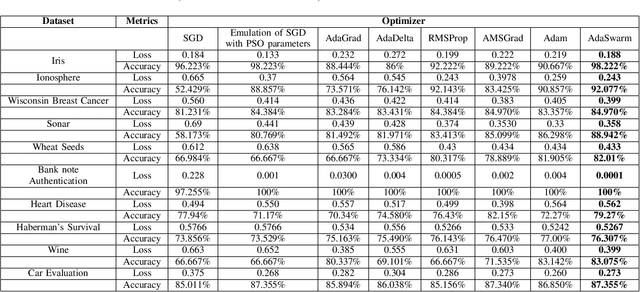

This paper tackles the age-old question of derivative free optimization in neural networks. This paper introduces AdaSwarm, a novel derivative-free optimizer to have similar or better performance to Adam but without "gradients". To support the AdaSwarm, a novel Particle Swarm Optimization Exponentially weighted Momentum PSO (EM-PSO), a derivative-free optimizer, is also proposed which tackles constrained and unconstrained single objective optimization problems and looks at applying the proposed momentum particle swarm optimization on benchmark test functions, engineering optimization problems and habitability scores for exoplanets which show speed and convergence of the technique. The EM-PSO is extended by approximating the gradient of a function at any point using the parameters of the particle swarm optimization. This is a novel technique to simulate gradient descent, an extremely popular method in the back-propagation algorithm, using the approximated gradients from the particle swarm optimization parameters. Mathematical proofs of gradient approximation by EM-PSO, thereby bypassing the gradient computation, are presented. The AdaSwarm is compared with various optimizers and the theory and algorithmic performance are supported by promising results.