 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaSwarm: A Novel PSO optimization Method for the Mathematical Equivalence of Error Gradients
Paper and Code
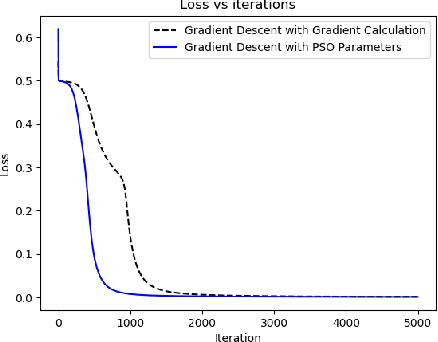
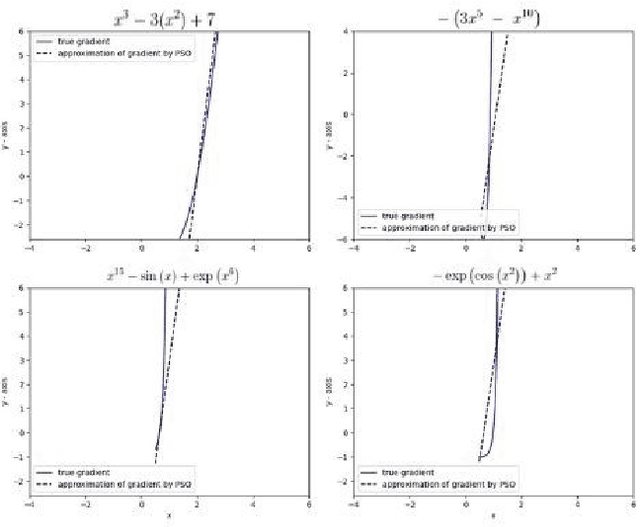
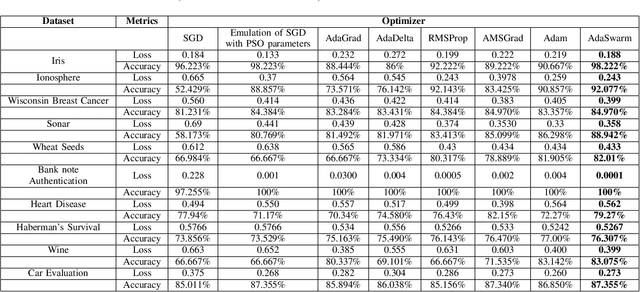

This paper tackles the age-old question of derivative free optimization in neural networks. This paper introduces AdaSwarm, a novel derivative-free optimizer to have similar or better performance to Adam but without "gradients". To support the AdaSwarm, a novel Particle Swarm Optimization Exponentially weighted Momentum PSO (EM-PSO), a derivative-free optimizer, is also proposed which tackles constrained and unconstrained single objective optimization problems and looks at applying the proposed momentum particle swarm optimization on benchmark test functions, engineering optimization problems and habitability scores for exoplanets which show speed and convergence of the technique. The EM-PSO is extended by approximating the gradient of a function at any point using the parameters of the particle swarm optimization. This is a novel technique to simulate gradient descent, an extremely popular method in the back-propagation algorithm, using the approximated gradients from the particle swarm optimization parameters. Mathematical proofs of gradient approximation by EM-PSO, thereby bypassing the gradient computation, are presented. The AdaSwarm is compared with various optimizers and the theory and algorithmic performance are supported by promising results.