 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCould AI Trace and Explain the Origins of AI-Generated Images and Text?
Apr 05, 2025AI-generated content is becoming increasingly prevalent in the real world, leading to serious ethical and societal concerns. For instance, adversaries might exploit large multimodal models (LMMs) to create images that violate ethical or legal standards, while paper reviewers may misuse large language models (LLMs) to generate reviews without genuine intellectual effort. While prior work has explored detecting AI-generated images and texts, and occasionally tracing their source models, there is a lack of a systematic and fine-grained comparative study. Important dimensions--such as AI-generated images vs. text, fully vs. partially AI-generated images, and general vs. malicious use cases--remain underexplored. Furthermore, whether AI systems like GPT-4o can explain why certain forged content is attributed to specific generative models is still an open question, with no existing benchmark addressing this. To fill this gap, we introduce AI-FAKER, a comprehensive multimodal dataset with over 280,000 samples spanning multiple LLMs and LMMs, covering both general and malicious use cases for AI-generated images and texts. Our experiments reveal two key findings: (i) AI authorship detection depends not only on the generated output but also on the model's original training intent; and (ii) GPT-4o provides highly consistent but less specific explanations when analyzing content produced by OpenAI's own models, such as DALL-E and GPT-4o itself.
AAAR-1.0: Assessing AI's Potential to Assist Research
Oct 29, 2024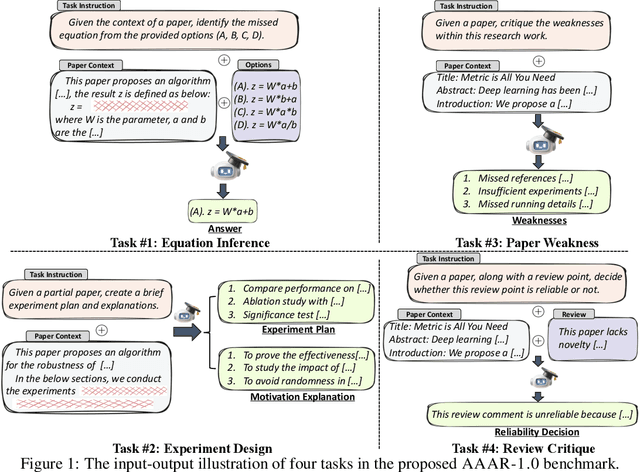
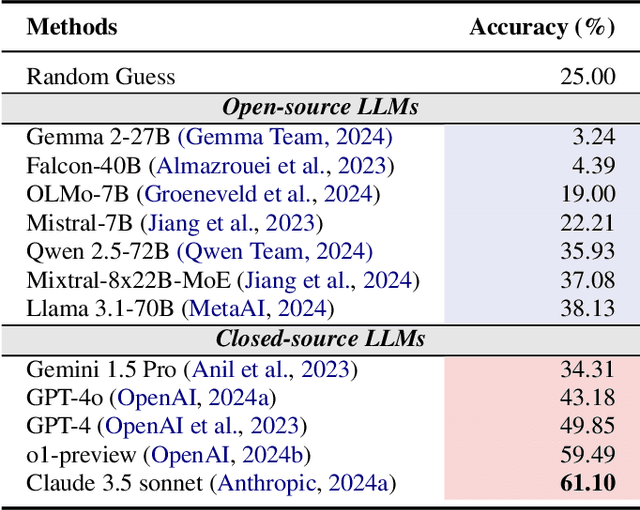
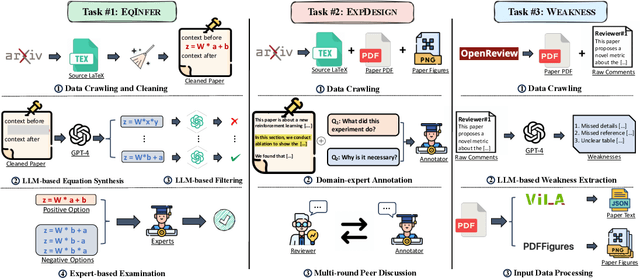
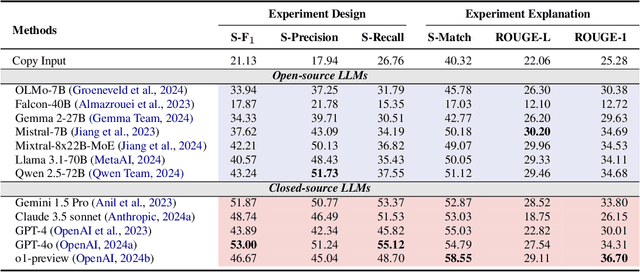
Numerous studies have assessed the proficiency of AI systems, particularly large language models (LLMs), in facilitating everyday tasks such as email writing, question answering, and creative content generation. However, researchers face unique challenges and opportunities in leveraging LLMs for their own work, such as brainstorming research ideas, designing experiments, and writing or reviewing papers. In this study, we introduce AAAR-1.0, a benchmark dataset designed to evaluate LLM performance in three fundamental, expertise-intensive research tasks: (i) EquationInference, assessing the correctness of equations based on the contextual information in paper submissions; (ii) ExperimentDesign, designing experiments to validate research ideas and solutions; (iii) PaperWeakness, identifying weaknesses in paper submissions; and (iv) REVIEWCRITIQUE, identifying each segment in human reviews is deficient or not. AAAR-1.0 differs from prior benchmarks in two key ways: first, it is explicitly research-oriented, with tasks requiring deep domain expertise; second, it is researcher-oriented, mirroring the primary activities that researchers engage in on a daily basis. An evaluation of both open-source and proprietary LLMs reveals their potential as well as limitations in conducting sophisticated research tasks. We will keep iterating AAAR-1.0 to new versions.
CERT: Contrastive Self-supervised Learning for Language Understanding
May 16, 2020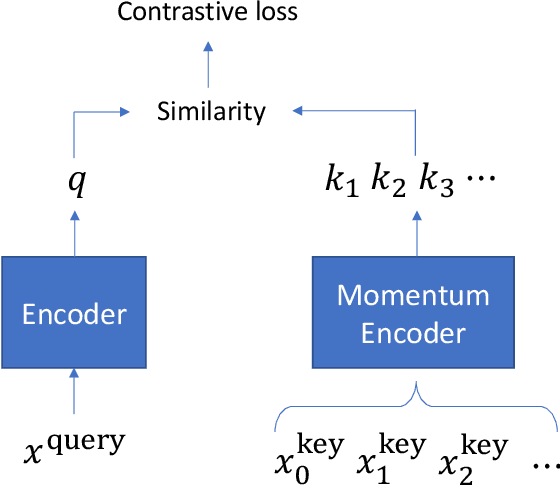



Pretrained language models such as BERT, GPT have shown great effectiveness in language understanding. The auxiliary predictive tasks in existing pretraining approaches are mostly defined on tokens, thus may not be able to capture sentence-level semantics very well. To address this issue, we propose CERT: Contrastive self-supervised Encoder Representations from Transformers, which pretrains language representation models using contrastive self-supervised learning at the sentence level. CERT creates augmentations of original sentences using back-translation. Then it finetunes a pretrained language encoder (e.g., BERT) by predicting whether two augmented sentences originate from the same sentence. CERT is simple to use and can be flexibly plugged into any pretraining-finetuning NLP pipeline. We evaluate CERT on three language understanding tasks: CoLA, RTE, and QNLI. CERT outperforms BERT significantly.
MedDialog: A Large-scale Medical Dialogue Dataset
Apr 07, 2020

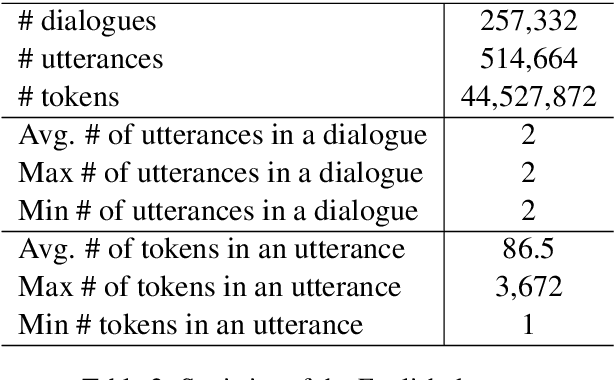

Medical dialogue systems are promising in assisting in telemedicine to increase access to healthcare services, improve the quality of patient care, and reduce medical costs. To facilitate the research and development of medical dialogue systems, we build a large-scale medical dialogue dataset -- MedDialog -- that contains 1.1 million conversations between patients and doctors and 4 million utterances. To our best knowledge, MedDialog is the largest medical dialogue dataset to date. The dataset is available at https://github.com/UCSD-AI4H/Medical-Dialogue-System